标签:clu 分享 wap 优化 color swa 随机数 并且 include
洛谷上卡不过去的朋友们可以来看看小C的程序(小C才不是标题党呢!)

第1行包含5个整数,依次为 x_0,a,b,c,d ,描述小H采用的随机数生成算法所需的随机种子。
第2行包含三个整数 N,M,Q ,表示小H希望生成一个1到 N×M 的排列来填入她 N 行 M 列的棋盘,并且小H在初始的 N×M 次交换操作后,又进行了 Q 次额外的交换操作。
接下来 Q 行,第 i 行包含两个整数 u_i,vi,表示第 i 次额外交换操作将交换 T(ui )和 T(v_i ) 的值。
输出一行,包含 N+M-1 个由空格隔开的正整数,表示可以得到的字典序最小的路径序列。
1 3 5 1 71
3 4 3
1 7
9 9
4 9
1 2 6 8 9 12
奇技淫巧题,卡时卡空间,考出了WC的画风。
相信O(nmlog(n+m))的做法大家都会。
一通模拟过后,基本思路就是贪心,每次选最小的数,能加就加,加入之后更新限制范围……你懂的。
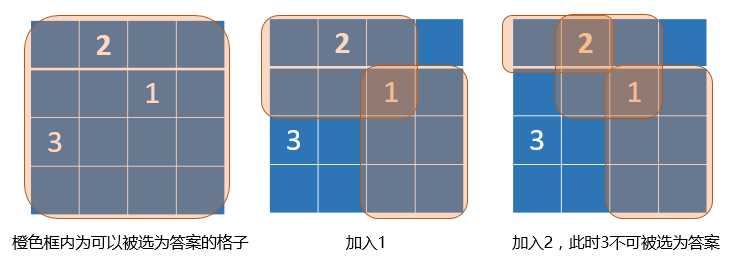
很多做法,一种是用set或平衡树来维护限制范围,还有一种就是直接在数组上二分,插入时暴力插入。
小C觉得第一种常数很大并且懒得写平衡树,所以就写了第二种。复杂度O(nmlog(n+m)+(n+m)^2)。
注意代码上各种会影响常数的细节,如取模等。
当你绞尽脑汁试图扭曲你的代码去卡过那万恶的常数时,不如再想想强有力的剪枝。
我们发现每条斜线上有且仅有一个数会被记入答案,不妨开一个bool数组来标记一下。
整整快了一倍有木有!
#include <cstdio> #include <algorithm> #define MM 25000005 #define MN 5005 #define make(a1,a2) ((pr){a1,a2}) #define l(a) (a.x) #define r(a) (a.y) using namespace std; struct pr{int x,y;}pa[MN<<1]; int X,A,B,C,D; int n,m,gs,p,nm,a[MM],b[MM]; bool u[MN<<1]; inline int read() { int n=0,f=1; char c=getchar(); while (c<‘0‘ || c>‘9‘) {if(c==‘-‘)f=-1; c=getchar();} while (c>=‘0‘ && c<=‘9‘) {n=n*10+c-‘0‘; c=getchar();} return n*f; } bool cmp(pr a,pr b) {return a.x<b.x || a.x==b.x && a.y<b.y;} int main() { register int i,j,x; pr z; X=read(); A=read(); B=read(); C=read(); D=read(); n=read(); m=read(); p=read(); nm=n*m; for (i=1;i<=nm;++i) { X=((1LL*A*X+B)*X+C)%D; a[i]=i; swap(a[i],a[(X%i)+1]); } while (p--) swap(a[read()],a[read()]); for (i=1;i<=nm;++i) b[a[i]]=i-1; pa[gs=1]=make(MN,MN); for (i=1;i<=nm;++i) { z=make(b[i]/m,b[i]%m); if (u[l(z)+r(z)]) continue; x=lower_bound(pa+1,pa+gs+1,z,cmp)-pa; if (r(z)>r(pa[x])||r(z)<r(pa[x-1])) continue; for (j=gs++;j>=x;--j) pa[j+1]=pa[j]; u[l(z)+r(z)]=true; pa[x]=z; if (i>1) putchar(‘ ‘); printf("%d",i); } }
在考场上谁会知道自己的程序会被卡成什么样呢?大概只有写完程序发现跑了5.X秒然后在程序末尾加上"orz ditoly"来保平安了吧。
不过仔细想想这样的优化还是能想得到的。
看看BZOJ上一个个只跑了20s的dalao们,感觉没有人A还要求放宽时限的洛谷还是Too Young。
n+e光速读入用在这道题上是杯水车薪。
标签:clu 分享 wap 优化 color swa 随机数 并且 include
原文地址:http://www.cnblogs.com/ACMLCZH/p/6857707.html