标签:load 方式 cto logs 容器 path rac com bsp
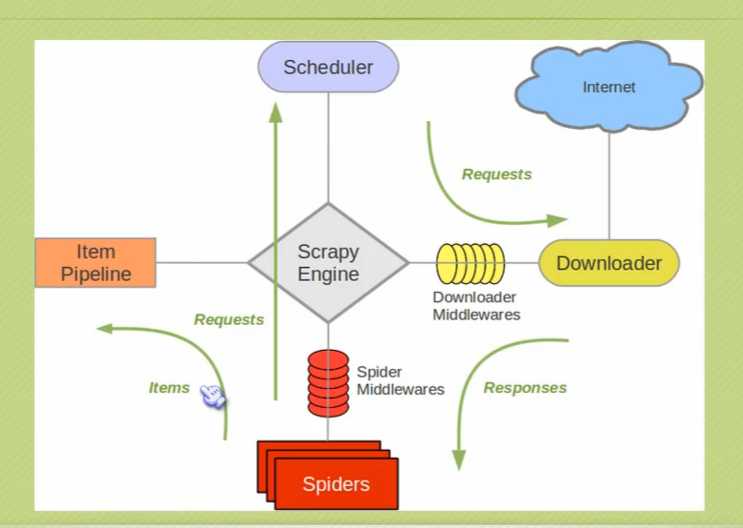
downloader:负责下载html页面
spider:负责爬取页面内容,我们需要自己写爬取规则 srapy提供了selector,获取的方式有xpath,css,正则,extract
item容器:spider获取到的内容放到item中
schedul:负责调度
标签:load 方式 cto logs 容器 path rac com bsp
原文地址:http://www.cnblogs.com/caojunjie/p/6868195.html