标签:str 频率 images size reduce bsp 时间 jar 常用
Storm常用操作命令
1、任务提交命令:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
storm jar /export/servers/storm/examples/storm-starter/storm-starter-topologies-1.0.3.jar org.apache.storm.starter.WordCountTopology wordcount
与hadoop不同的是:不需要指定输入输出路径
hadoop jar /usr/local/wordcount.jar /data.txt /wcout
2、杀死任务命令:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
3、停用任务命令:storm deactivte 【拓扑名称】
storm deactive topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
4、启用任务命令:storm activate 【拓扑名称】
storm activate topology-name
5、重新部署任务命令:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配worker,并重启拓扑。
StormWordCount(重点掌握)
WordCount分析:
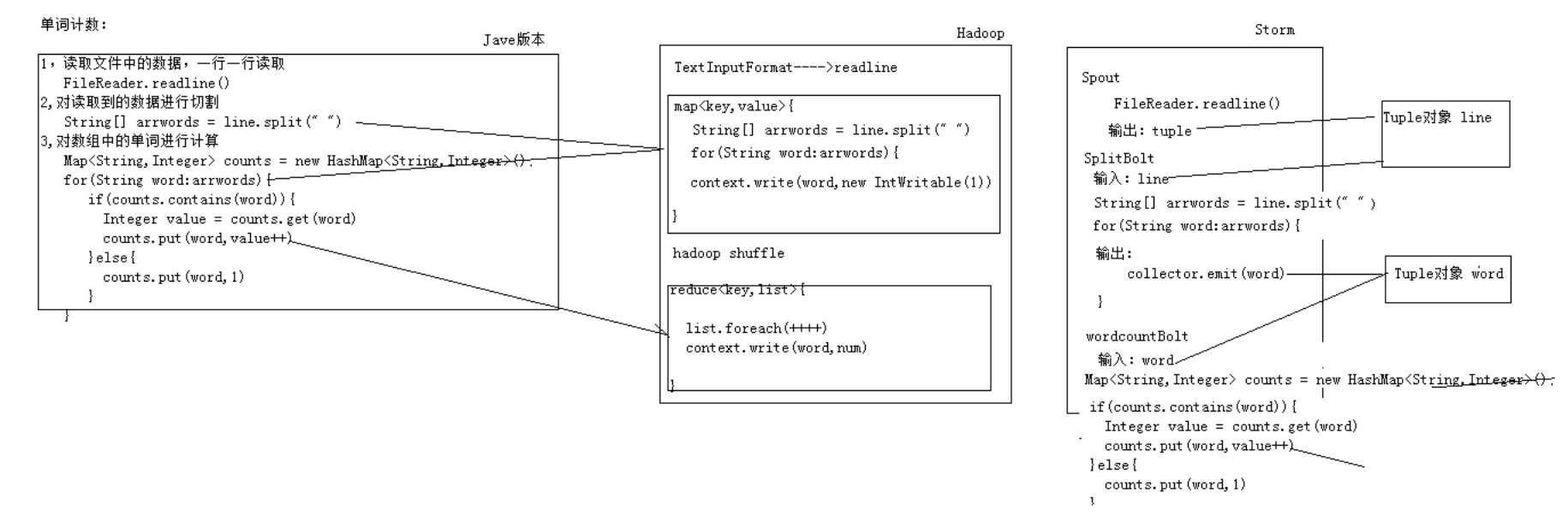
Java版本:
1、读取文件中的数据,一行一行的读取;
2、将读到的数据进行切割;
3、对切割后的数组中的单词进行计算。
Hadoop版本:
1、按行读取文件中的数据;
2、在Mapper()函数中对每一行的数据进行切割,并输出切割后的数据数组;
3、接收Mapper()中输出的数据数组,在Reducer()函数中对数组中的单词进行计算,将计算后的统计结果输出。
Storm版本:
1、Spout从外部数据源中读取数据,随机发送一个元组对象出去;
2、SplitBolt接收Spout中输出的元组对象,将元组中的数据切分成单词,并将切分后的单词发射出去;
3、WordCountBolt接收SplitBolt中输出的单词数组,对里面单词的频率进行累加,将累加后的结果输出。
标签:str 频率 images size reduce bsp 时间 jar 常用
原文地址:http://www.cnblogs.com/ahu-lichang/p/6871920.html