标签:web 添加 ica 环境配置 param floyd datanode arp mon
上一篇博文,博主以自己的看法对大数据与 Hadoop 进行了一些简单的介绍,然后配置了系统环境。这篇博文,博主继续把配置伪分布式接下来的步骤与配置的意义写下来。
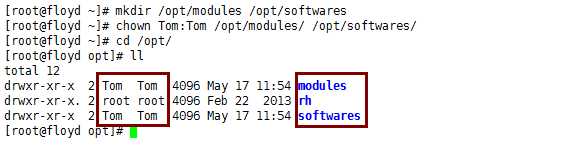
1 [root@floyd ~]# mkdir /opt/modules /opt/softwares 2 [root@floyd ~]# chown Tom:Tom/opt/modules//opt/softwares/
1 [Tom@floyd~]$ rpm -qa | grep -i java #检查本地是否已经安装jdk 2 [Tom@floyd~]$ rpm -e --nodeps jdkxxxxxxxxxxxxxxxxxxx #如果有就删除掉
[Tom@floyd softwares]$ tar -zxvf jdk-7u67-linux-x64.tar.gz -C /opt/modules/
[Tom@floyd~]$ sudo vi /etc/profile
编辑 profile 文件,在最后一行添加
1 [Tom@floyd~]$ source /etc/profile 2 [Tom@floyd~]$ java -version # 检查java 版本

[root@floyd ~]# visudo
[Tom@floyd~]$ tar -zxvf /opt/softwares/hadoop-2.5.0.tar.gz -C /opt/modules/
[Tom@floyd~]$ sudo vi /etc/profile # 与配置jdk环境方法类似
[Tom@floyd~]$ cd /opt/modules/hadoop-2.5.0/etc/hadoop/
[Tom@floyd hadoop]$ sudo vi hadoop-env.sh
# The java implementation to use.
1 <configuration> 2 <!--NameNode的访问URI,写主机名或ip地址,8020为默认端口,可改--> 3 <property> 4 <name>fs.defaultFS</name> 5 <value>hdfs://floyd.domain:8020</value> 6 </property> 7 <!--临时数据目录,用来存放数据,格式化时会自动生成--> 8 <property> 9 <name>hadoop.tmp.dir</name> 10 <value>/opt/modules/hadoop-2.5.0/data</value> 11 </property> 12 </configuration>
1 <configuration> 2 <!--Block的副本数,伪分布式要改为1--> 3 <property> 4 <name>dfs.replication</name> 5 <value>1</value> 6 </property> 7 </configuration>
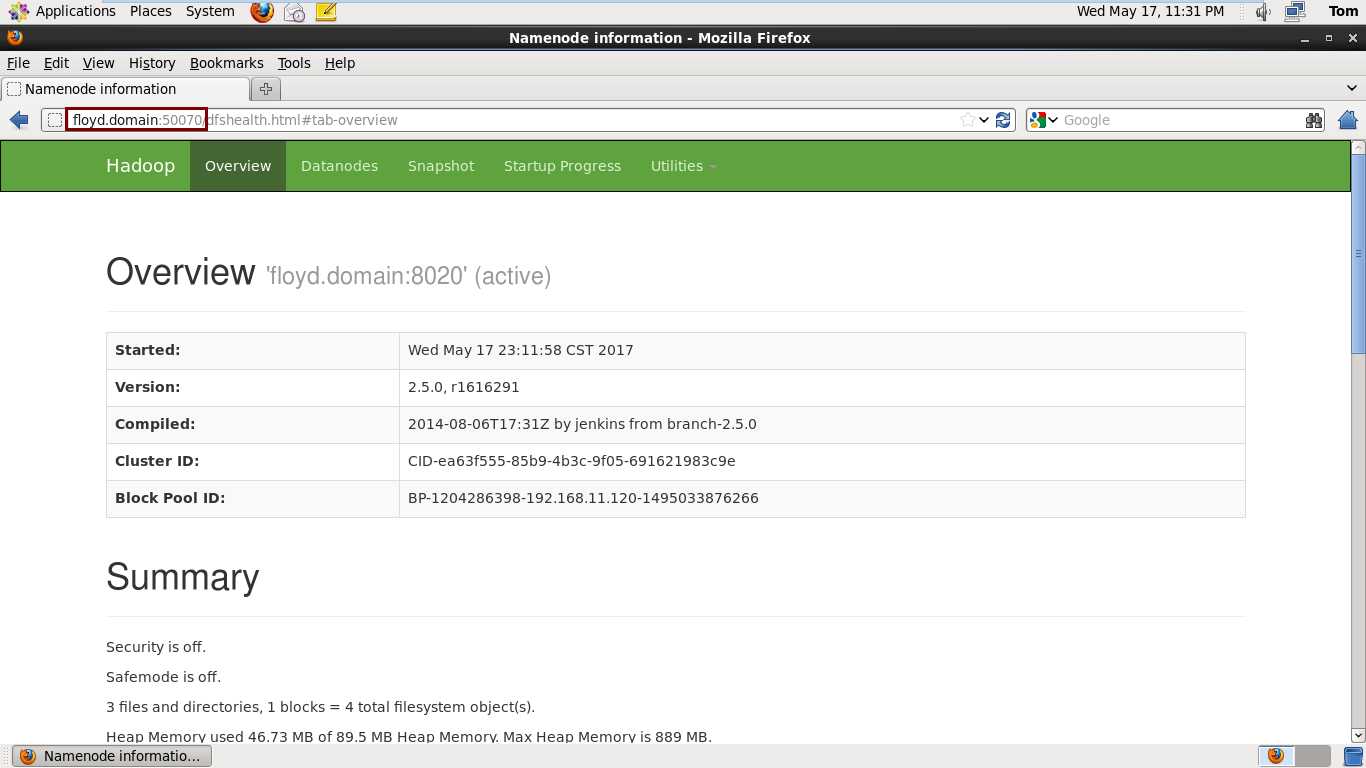
[Tom@floyd hadoop-2.5.0]$ bin/hdfs namenode -format
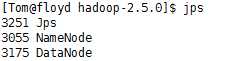
1 [Tom@floyd hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode 2 [Tom@floyd hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode 3 [Tom@floyd hadoop-2.5.0]$ jps # Process status
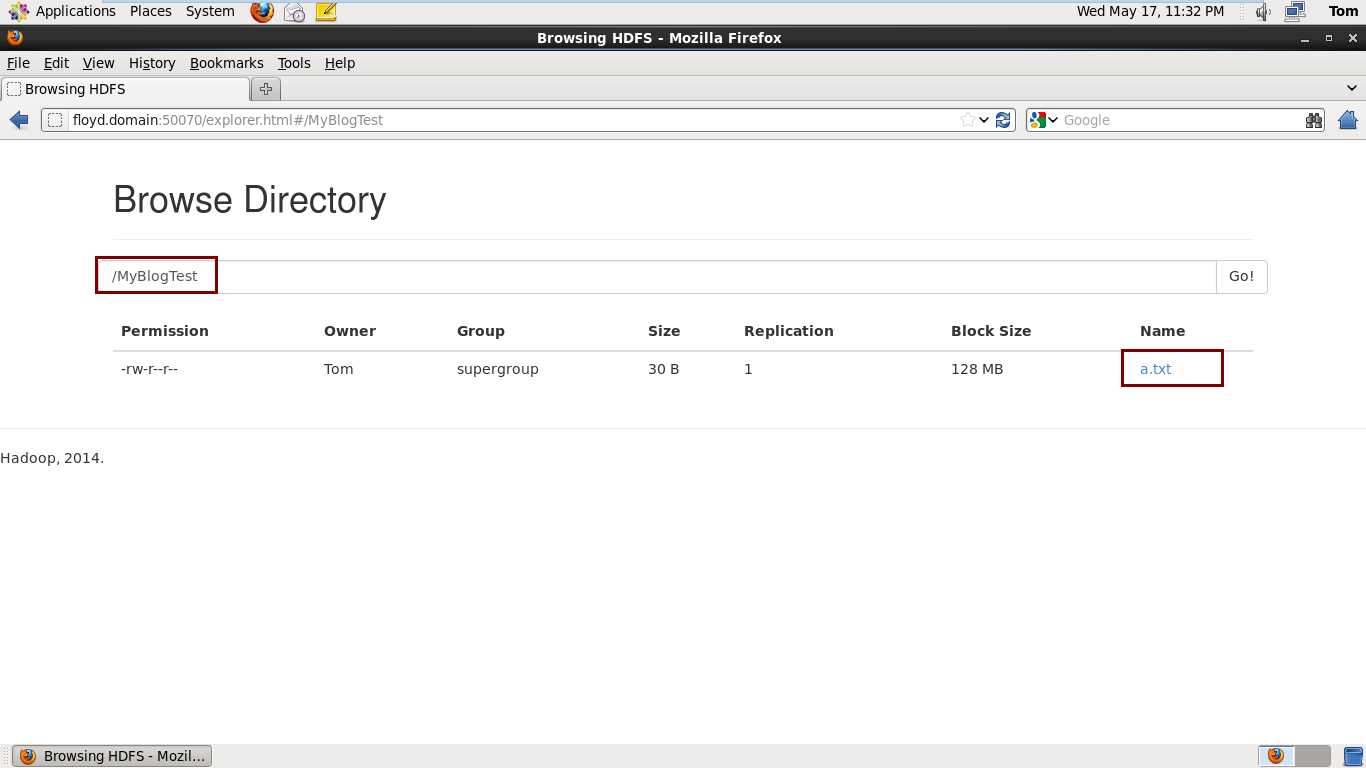
1 [Tom@floyd hadoop-2.5.0]$ bin/hdfs dfs -mkdir /MyBlogTest 2 [Tom@floyd hadoop-2.5.0]$ vi a.txt 3 [Tom@floyd hadoop-2.5.0]$ bin/hdfs dfs -put a.txt /MyBlogTest
[Tom@floyd hadoop]$ sudo vi yarn-env.sh
[Tom@floyd hadoop]$ sudo vi mapred-env.sh
[Tom@floyd hadoop]$ sudo vi slaves
1 <configuration> 2 <!--NodeManager上运行的辅助(auxiliary)服务,需配置成mapreduce_shuffle,才可运行MapReduce程序--> 3 <property> 4 <name>yarn.nodemanager.aux-services</name> 5 <value>mapreduce_shuffle</value> 6 </property> 7 <!--指定resourcemanager主机--> 8 <property> 9 <name>yarn.resourcemanager.hostname</name> 10 <value>floyd.domain</value> 11 </property> 12 <!--启用日志聚合功能--> 13 <property> 14 <name>yarn.log-aggregation-enable</name> 15 <value>true</value> 16 </property> 17 <!--日志保留时间,单位秒--> 18 <property> 19 <name>yarn.log-aggregation.retain-seconds</name> 20 <value>86400</value> 21 </property> 22 </configuration>
<configuration> <!--mapreduce是一种编程模型,运行在yarn平台上面--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--JobHistory服务的IPC地址(IPC:Inter-ProcessCommunication进程间通信)--> <property> <name>mapreduce.jobhistory.address</name> <value>floyd.domain:10020</value> </property> <!--日志的web访问地址--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>floyd.domain:19888</value> </property> </configuration>
1 [Tom@floyd hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager 2 [Tom@floyd hadoop-2.5.0]$ sbin/yarn-daemon.sh start datamanager
标签:web 添加 ica 环境配置 param floyd datanode arp mon
原文地址:http://www.cnblogs.com/moyinyu/p/6872711.html