标签:gis 个数 报告 建模工具 database 信息服务 编写 用户 静态对象
数据模型设计
1.整体框架约束下的迭代渐进
谈到关系数据模型设计,首先想到的可能会是“概念数据模型设计”及实体关系图(ER
图),但我认为完整的数据库数据模型设计需要经过三个阶段:
(1) 数据总体结构设计;
(2) 概念数据模型设计;
(3) 构建数据库模式。
2 数据总体结构设计
由于总体结构只是一个静态框架,因此总体结构设计只涉及静态对象建模,建模工具
采用UML。
根据面向对象分析与设计方法,总体结构设计工作可按下列流程开展:
(1) 剖析问题域(工作流与数据流分析);
(2) 划分对象(面向对象分析);
(3) 定义类(面向对象设计);
(4) 定义类之间的关系(面向对象设计);
(5) 绘制UML类图,小组讨论或专家认定;
(6) 发布总体结构,统一设计思想。
1.工作流与数据流分析
剖析问题域是期望通过问题域的工作流和数据流分析提取数据对象,从而构成数据类
的抽象。工作流和数据流分析可以通过UML活动图理顺工作过程以及工作过程中可能产生
的数据对象,如图2.2(采用 Microsoft Visio 绘制)。
图2.2中的UML活动图符号说明如下:
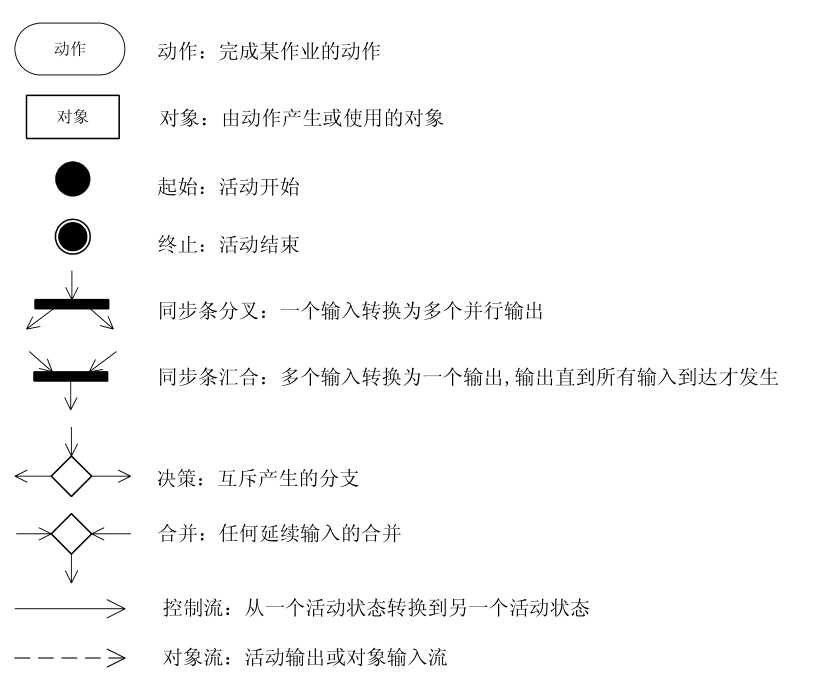
图2.2表示成果图编制过程中的数据处理工作分为三个阶段、五个环节。即资料汇聚,
细化处理和成品提交阶段;其中细化处理阶段又包括分组整理、分类加工及元数据编写环
节,与数据供方的沟通交流和质量控制措施贯穿始终。在资料汇聚阶段,数据处理方必须
明确数据包数据内容,并与数据供方沟通协调,畅通数据渠道,促使双方形成一个有机的
整体,保障工作顺利进行。细化处理阶段,按照数据模型设计要求将数据包分解为各数据
集单元,然后将各数据集单元分解为数据子集单元,再按载体类型对不同载体的数据子集
资料进行分类加工;加工后的数据再以数据子集为单元物理整合,以数据集为单元逻辑组
合,质量检查合格后提交数据产品;最后,编写并提交数据集的元数据。成品提交阶段,
将各数据集的数据与元数据汇总打包成数据集产品,数据质量审查合格后形成数据集成品
或数据包成品提交入库。
工作流和数据流也可以采用结构化软件设计中的工作流与数据流图进行分析,如图2.3、
图2.4。工作流与数据流图是结构化软件设计中的分析工具,虽然现在多采用面向对象以及
UML来进行软件系统的分析设计,但工作流与数据流图因其简易直观仍然有着不可替代的作
用。
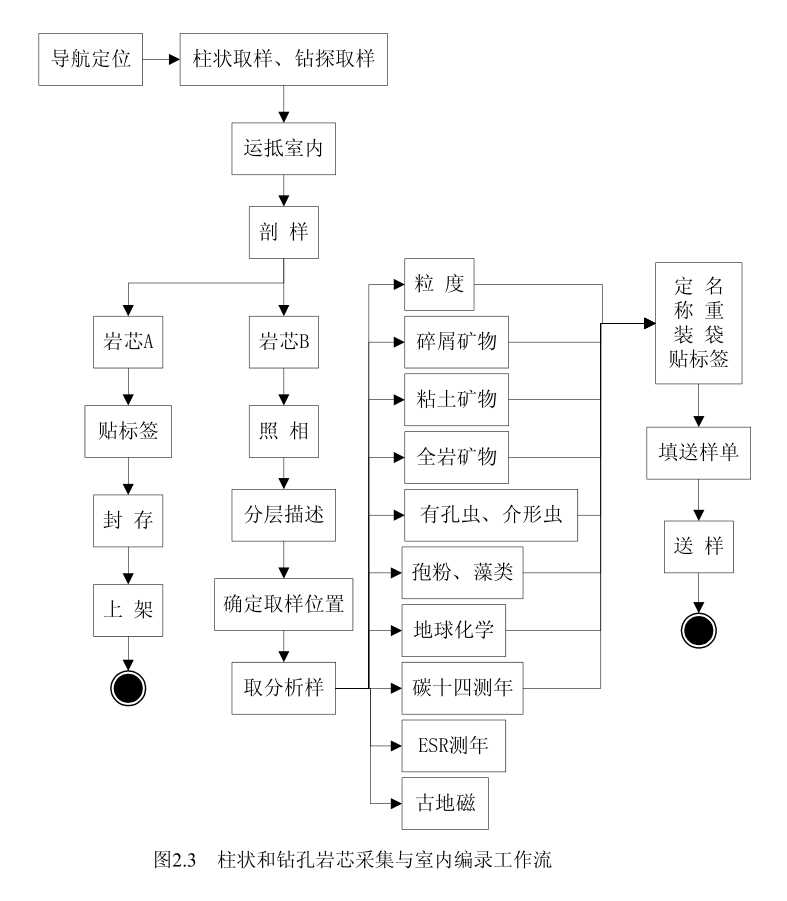
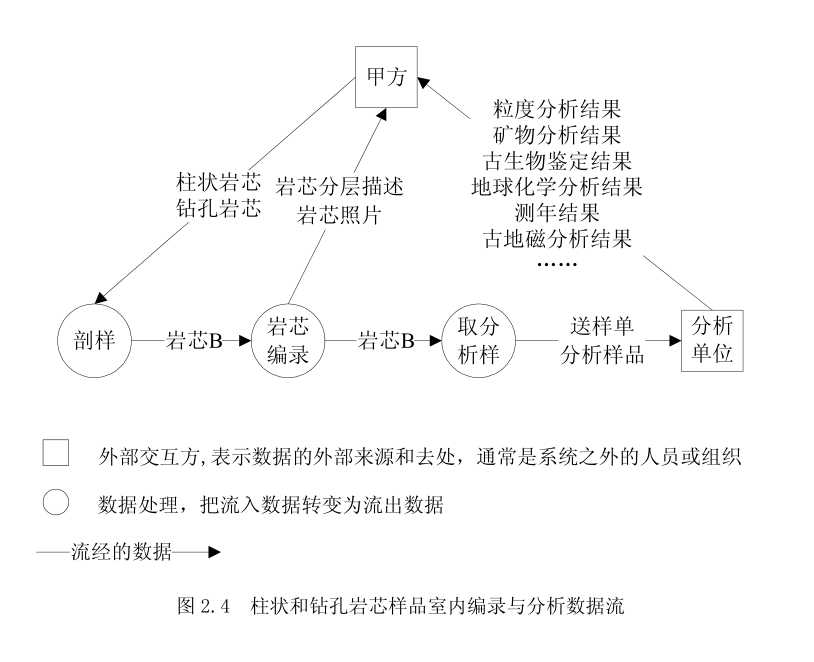
图 2.3 与图 2.4 表示了柱状与钻孔岩芯在室内的编录与分析过程,首先沿按岩芯管中
轴线将柱状与钻孔岩芯剖分两半,其中的一半进行封装处理作永久保留,另一半用于室内
编录和分析样采集。编录前对岩芯进行照相,然后进行岩芯分层描述。在岩芯描述完成后,
确定各类分析样品的取样位置,采取分析样品。采取的分析样品经定名、称重、装袋、贴
标签、填写送样单,最后送各实验室测试分析。
2 面向对象分析与设计
面向对象分析与设计中可采用的原则不少, Craig Larma 在其《UML和模式应用》)一
书中有详细的论述,下面的原则我认为对数据总体结构设计来说很有用:
(1) 模块化:将问题域数据分解成一组内部内聚、外部松散耦合的模块。内聚指对象
自身职责的相关性和集中度比较高,类似于把相关性和集中度比较高的职责分配
给单独的对象,不让一个对象承担过多不相关的工作。松散耦合指对象之间的依
赖程度比较低,需要时可以帮一下,不需要时相忘于江湖,互相没有太多的牵连,
以此来降低对象之间的依赖程度,减少变化带来的影响,提高系统的伸缩性。在
Geodatabase中的模块化就是将数据分成不同的要素集,要素集内的数据共享同一
空间参照系,要素集内的要素类之间可以具有拓扑关系,但要素集之间的耦合是
松散的。
(2) 信息专家:把某类信息的管理职责分配给拥有该类信息的对象。信息专家原则实
际上是要求一个对象所涉及的信息要单一,不要涉及不相关的信息内容。
(3) 间接性:为了避免两个或多个对象之间的直接耦合,可引入中介对象,使其作为
联系的媒介,通过中介可使数据库内部各数据模块之间的关系达到最小化。这就
是所谓的不要和“陌生人”对象讲话,增加公共的“熟人”对象原则。GIS系统设
计中最常见的是将位置模块作为公共模块,数据模块之间的关联均通过位置模块
实现,使模块之间的关系最小化。
(4) 纯虚构:如果不想违背模块化原则,信息专家原则又不合适时,可以创建新的对
象,该对象不代表问题域的概念,是凭空虚构的。如Geodatabase中的要素集实际
上就是纯虚构对象。
(5) 防止变异:预测可能的变化点或进化点,在变化范围之外创建对象,使其内部变
化不会对其它对象产生不良影响。最常见的是动静隔离的方法,将多变的部分从
相对稳定的部分中隔离出来。
总体结构最终给出的应该是一个有机整体,整体内部自成体系,如:里外分层、内部
分块,外层有入口(数据入口或数据管理单元),有出口(数据对外的信息通道),内部有
不同的模块(类)和模块之间的通道(类之间的联系)。同时,总体结构必须具有足够的抽
象程度,能保持长期稳定,并包容变化。检验总体结构的基本标准是:总体结构来自问题
域数据流的抽象,但必须与问题域的具体应用无关。

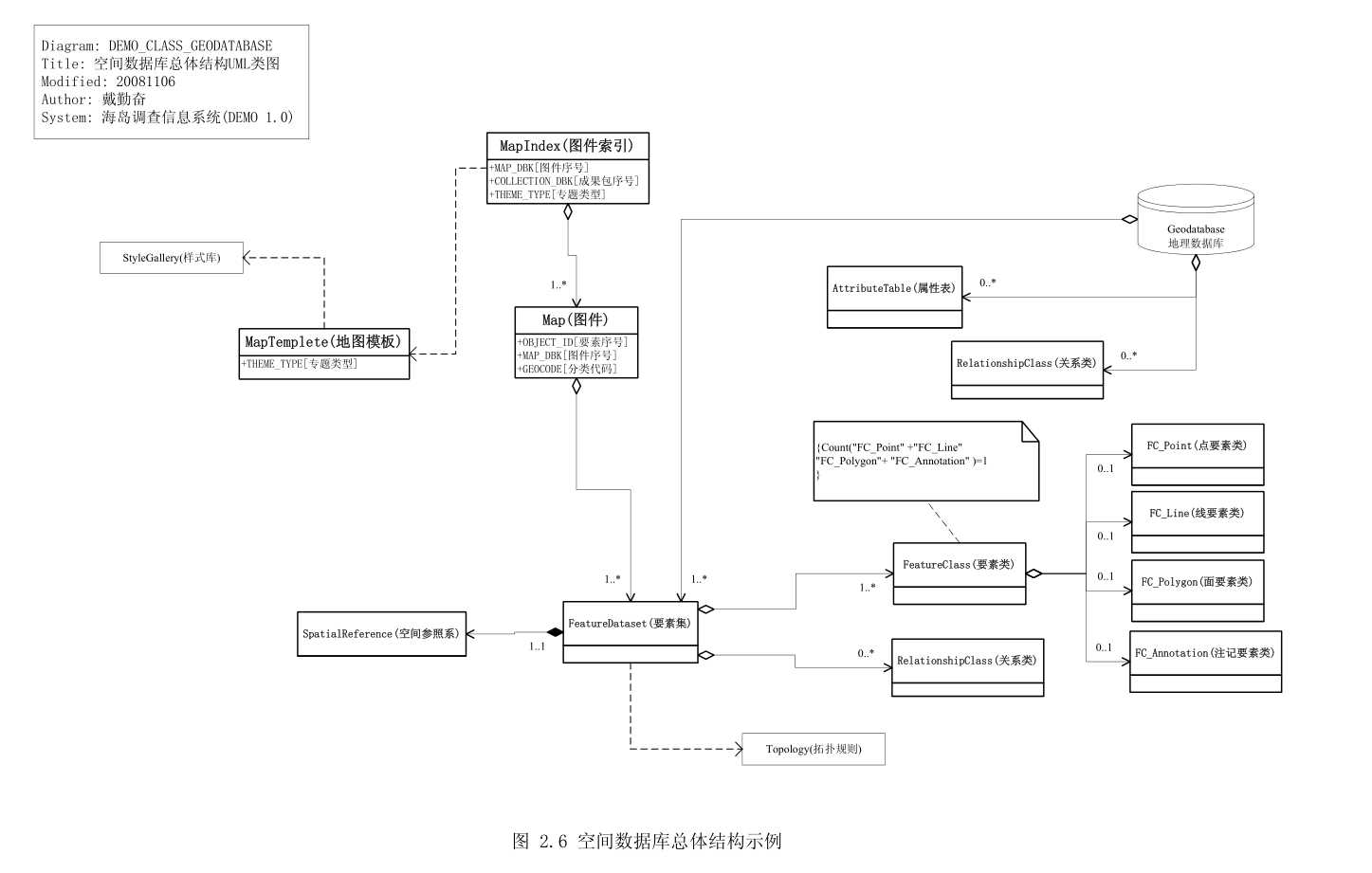
图中类与类的关系包括聚合/组合、泛化和依赖。
当类之间有整体与部分关系的时候,使用聚合或者组合。聚合是一种相对松散的整体
与部分关系,聚合类不需要对被聚合类负责。图 2.6 中,“要素集”由“要素类”及其“关
系类”聚合而成。
组合是一种强聚合关系,组合类控制着被组合类的生命期,被组合类会随着组合类的
创建而创建,随着组合类的消亡而消亡。图 2.6 中,“要素集”与“空间参照系”之间就是
组合关系,同一个要素集内的要素类享有同一空间参照系,离开空间参照系,空间数据就
失去了地理意义。
依赖是一种弱关联,表示一个类与另一个类的涉及关系,但不是固定关系。例如:自
行车与打气筒,汽车与汽油的关系。图 2.6 中“要素集”与“拓扑规则”之间定义为依赖
关系,表示需要时可以通过拓扑规则来检测地理要素的数据质量,两者之间没有必然联系。
泛化表示子类与父类之间的关系,父类能够派生出具有更多特殊行为的子类,此时父
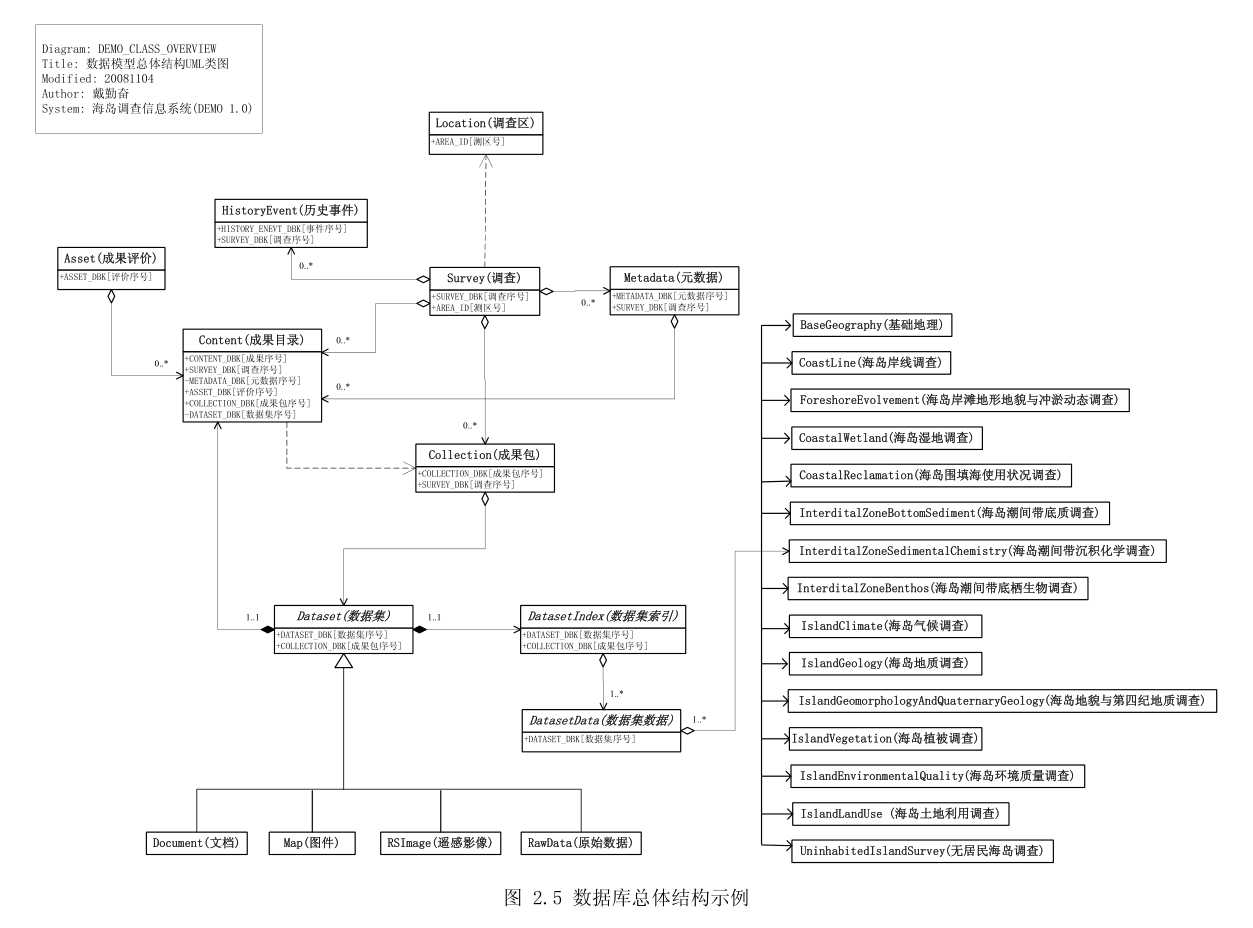
类即为子类的超类或说子类的泛化,子类是父类的特化。图 2.5 的抽象类(斜体字表示)“数
据集”为一泛化类,“文档”、“图件”、“遥感影像”和“原始数据”都是“数据集”的特化。
经常见到泛化与继承混用,严格来说,两者属于不同的领域不拟混用。泛化和特化属于问
题域,继承属于软件领域。软件领域的继承是使超类的特性适应于子类的软件机制,主要
是为了代码重用。而在问题域是期望对泛化类的研究提取子类的共性,以便数据类的抽象。
图 2.5 的设计意图如下:
(1) 数据库数据内外分层,层内分块。外层为数据信息层,包括调查信息模块的“调
查区”(Location)、“调查”(Survey)、“历史事件”(HistoryEvent)、“成果目
录”(Content)、“成果评价”(Asset)和“成果包”(Collection),以及元数据
模块的“元数据”(Metadata),它们负责数据的对外信息服务。内层为数据资
源层,负责具体数据资源(文档、图件、遥感影像及原始数据模块)的存储。
外层与内层之间只有逻辑上的联系,物理上可以是隔离的,这为数据的安全性
提供了保障。
(2) “调查”(Survey)、“成果包”(Collection)、“数据集”(Dataset)类是支撑数
据库的中枢。在一个调查区可能进行多项专业调查,每项专业调查结果会形成
一个成果包,每个成果包中可能包括有多个报告文档、多幅成果图件、以及一
系列实测或收集的原始数据。
(3) “成果包”(Collection)是由外层进入内层的隘口,每个成果包的拥有者可以
拥有自己数据的管理权。这为实施多方数据管理奠定了基础,如果对成果包对
象施加数据表行级安全策略,进入数据库后,数据供方将只能看到并管理自己
的数据。
(4) “调查”(Survey)是数据信息层的非空间入口,同时“调查区”(Location)
可以作为数据的空间入口。入口意味着它们是数据的出入管理员,数据入库必
须先向它们登记,数据检索也首先从它们开始,对数据的任何操作将在入口处
被跟踪。
(5) “元数据”(Metadata)作为对外信息窗口,调查可以有调查元数据,成果也可
以有成果元数据。
(6) “成果目录”(Content)和“历史事件”(HistoryEvent)由系统自动维护,追踪
数据资源的入库、修改及更新操作。“成果目录”(Content)中可以容纳“成果
评价”(Asset)信息,让用户在第一时间了解数据的质量级别。成果评价可以
由多方专家通过网络评定。
(7) 内层的数据资源由“文档”、“图件”、“遥感影像”及“原始数据”模块管理。
数据集作为数据资源的逻辑组织单元,数据集可以是一个文档、一幅图件、或
同期同类型的实测数据,没有严格的范围界定。数据集实际数据均通过索引表
调用。
图 2.6 其实是 ArcGIS Geodatabase 的总体结构 UML 类图,其包含信息描述如下:
(1) 地图通过“图件索引”(MapIndex)提取,“图件”(Map)类负责地理要素的存储,
“地图模板”(MapTemplete)负责地理要素的显示。
(2) 一幅图件是 1 到多个要素集数据的专题聚合,及选定样式下各要素类对应图层
的综合表现。
(3) 地图数据由 ESRI 面向对象地理数据库(Geodatabase)统一存储及管理。包括
库级的要素集、属性表与关系类,以及要素集级别的要素类和关系类。
(4) 要素集聚合对象包括不同几何类型的要素类以及与要素类相关的关系类。同一个
空间要素集内的要素类享有同一空间参照系。拓扑规则也在同一数据库的要素
集中进行管理。
(5) 矢量要素类图元类型包括有:点(Point)、线(Line)、面(Polygon)、注记
(Annotation)四种,一个要素类只能包含一种图元类型。
(6) 属性表存储在地理数据库中通过关系类与要素类关联,实现要素类属性的动态捆
绑。
总体结构设计有关大局, 它是整个数据模型的灵魂,需要思路合理和概念完整,能在
将来为数据库系统的易用性及伸缩性提供保障,因为技术会不断更新,需求也会不断变化,
但数据库是不应该推倒重来的。有效的总体结构模型应该捕获了能满足当前需求的问题域
概念,搭建起实用的概念连接框架,最终确保模型能回答任何合理的问题,譬如: 是否有
利于数据安全保护?是否有利于数据管理?是否有利于公众服务?是否能适应变化?是否
能对后续设计起到指导与约束作用?等等。
3 概念数据模型设计
概念数据模型设计的目标是创建问题域对象的概念描述,使用关系模型时,问题域的
概念称作实体,概念的描述就是定义实体以及实体间的联系。概念数据模型通过实体
(Entity)、属性(attribute)、域(domain)和联系来描述。
概念数据模型设计在总体结构框架约束下进行,首先在总体结构框架中选择数据类,
最好从你比较熟悉的、或你认为比较重要的、或具有代表性的数据类入手;然后依据规范
化原则将数据对象分解成可关联的数据实体;在此基础上根据实际需要定义各实体的属性,
同时依照专业领域的业务规则定义属性的域;最后进行模型的测试及优化。概念数据模型
设计工作可以由多人分模块进行,但是必须将总体结构设计思想落实到每一个人,始终维
护总体设计思想的一致性。
概念数据模型设计流程如下:
(1) 从总体结构中选取数据模块,确定待设计的数据对象;
(2) 分解数据对象,确定数据实体及实体间的关系,绘制总实体关系图(不带属性 ER
图);
(3) 定义实体的属性及域,绘制带属性的实体关系图,并附数据字典对属性的定义以
及属性的域加以文字补充说明;
(4) 模型测试、修改与优化。
概念数据模型设计涉及许多“概念”,我很长时间处于模模糊糊之中,譬如说概念数据
模型的概念两字其含义究竟是什么?实体又是什么?域又是什么?规范化原则到底该贯彻
到何种程度?等等。2.3.1 的一些认识,可能会对设计工作有所帮助。
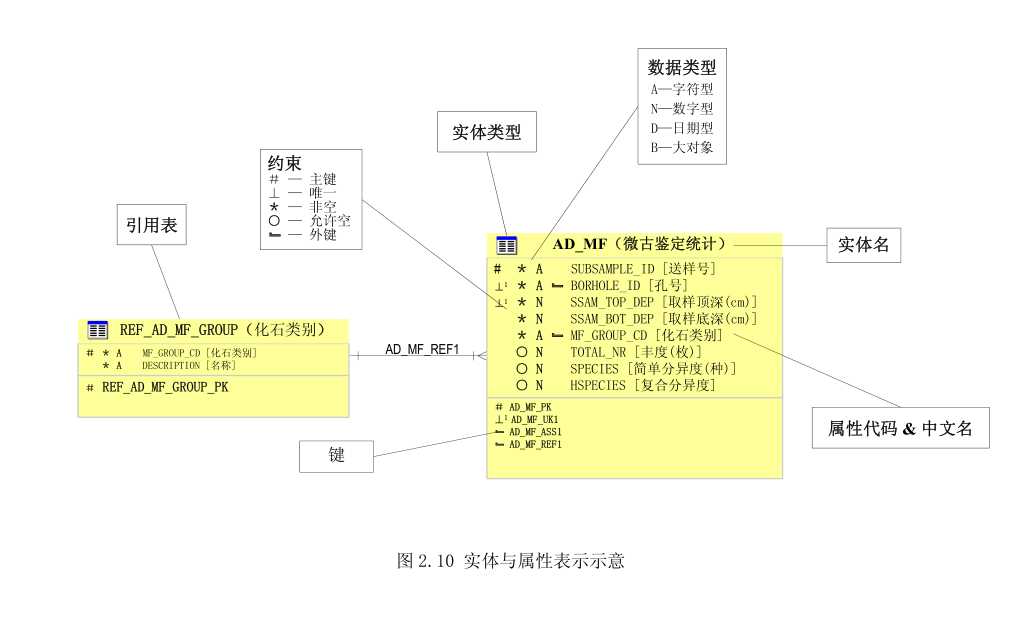
实体关系图与数据字典
概念数据模型文档一般包括两部分,实体关系图(ER图)及数据字典,数据字典以字
典形式给出数据实体与属性的文字定义,以避免多义理解。
实体关系图(ER 图)绘制一般分两步走,第一步只考虑实体以及它们之间的联系,第
二步考虑给定实体的属性,不同时考虑两者是为了让设计工作变得单纯一点。实体关系图
的表示方法很多,当然只要能清楚表达设计意图就好。
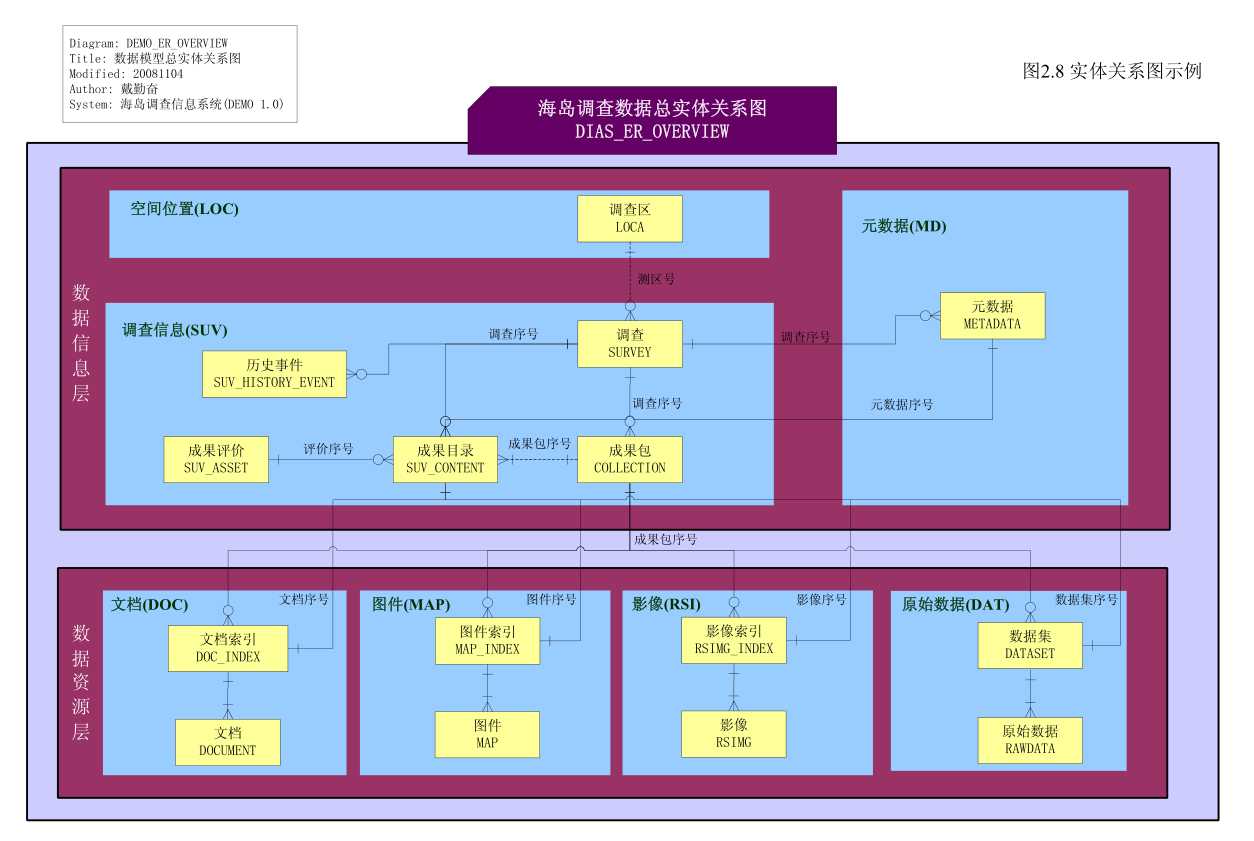
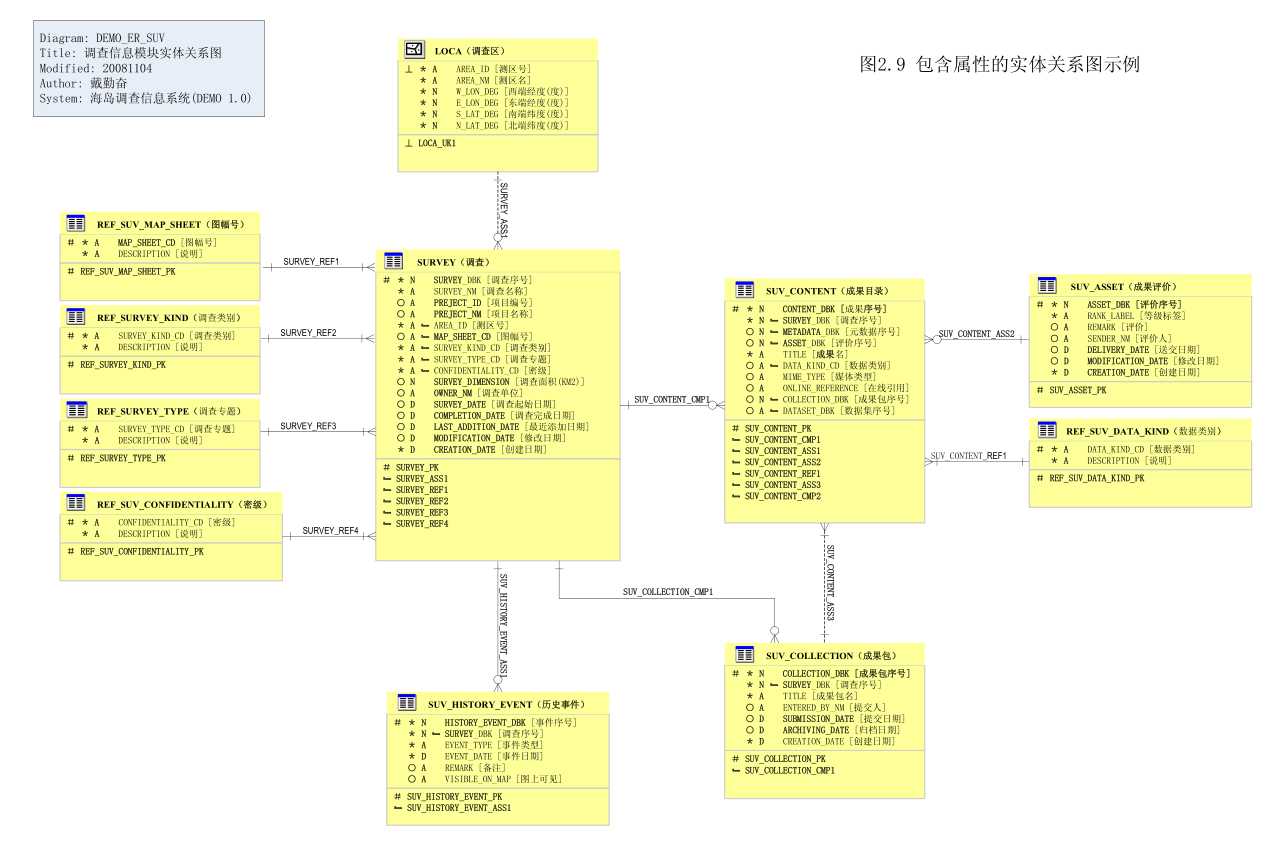
图 2.8 为只考虑实体及其联系的实体关系图示例,图 2.9 为包含属性的实体关系图。

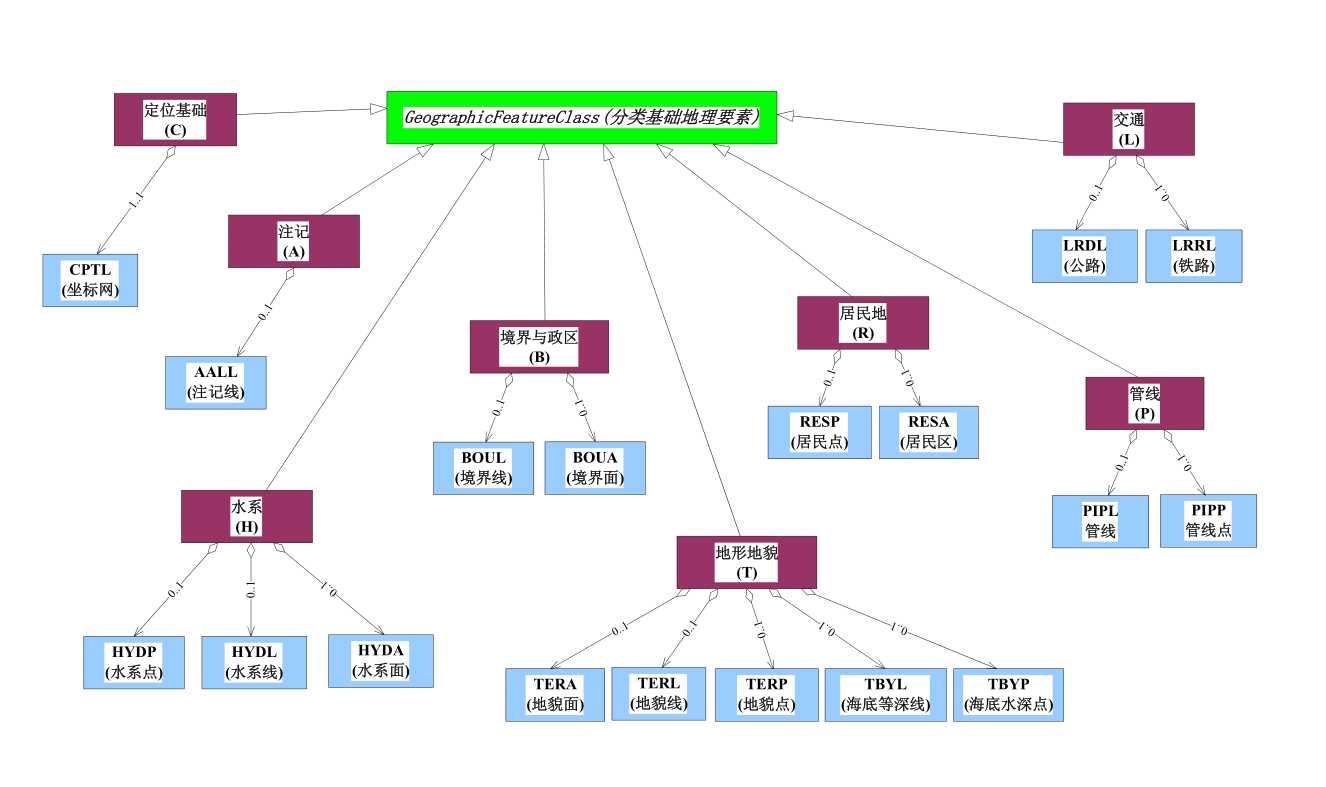
划分要素集和要素类
更多参见: http://pan.baidu.com/s/1jIE8H1O
标签:gis 个数 报告 建模工具 database 信息服务 编写 用户 静态对象
原文地址:http://www.cnblogs.com/q1104460935/p/6874956.html