标签:交换 额外 存在 nload 复合 访问 nan jar 无锁
对于并发控制而言,
锁是一种悲观的策略。它总是假设每一次的临界区操作会产生冲突,因此,必须对每次操作都小心翼翼。如果有多个线程同时需要访问临界区资源,就宁可牺牲性能让线程进行等待,所以说锁会阻塞线程执行。
而无锁是一种乐观的策略,它会假设对资源的访问是没有冲突的。既然没有冲突,自然不需要等待,所以所有的线程都可以在不停顿的状态下持续执行。那遇到冲突怎么办呢?无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。
无锁的好处:
第一,在高并发的情况下,它比有锁的程序拥有更好的性能;
第二,它天生就是死锁免疫的。
就凭借这两个优势,就值得我们冒险尝试使用无锁的并发。
1.与众不同的并发策略:比较交换(CAS)
与锁相比,使用比较交换(下文简称CAS)会使程序看起来更加复杂一些。但由于其非阻塞性,它对死锁问题天生免疫,并且,线程间的相互影响也远远比基于锁的方式要小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
CAS算法的过程是这样:它包含三个参数CAS(V,E,N)。V表示要更新的变量,E表示预期值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
简单地说,CAS需要你额外给出一个期望值,也就是你认为这个变量现在应该是什么样子的。如果变量不是你想象的那样,那说明它已经被别人修改过了。你就重新读取,再次尝试修改就好了。
在硬件层面,大部分的现代处理器都已经支持原子化的CAS指令。在JDK 5.0以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且,这种操作在虚拟机中可以说是无处不在。
2.无锁的线程安全整数:AtomicI nteger
为了让Java程序员能够受益于CAS等CPU指令,JDK并发包中有一个atomic包,里面实现了一些直接使用CAS操作的线程安全的类型。其中,最常用的一个类,应该就是AtomicIn-teger。你可以把它看做是一个整数。但是与Inte-ger不同,它是可变的,并且是线程安全的。对其进行修改等任何操作,都是用CAS指令进行的。这里简单列举一下AtomicInteger的一些主要方法,对于其他原子类,操作也是非常类似的:
public final int get()//取得当前值
public final void set(int newValue)//设置当前值
public final int getAndSet(int newValue)//设置新值,并返回旧值
public final boolean compareAndSet(int expect, int u)//如果当前值为expect,则设置为u
public final int getAndIncrement()//当前值加1,返回旧值
public final int getAndDecrement()//当前值减1,返回旧值
public final int getAndAdd(int delta)//当前值增加delta,返回旧值
public final int incrementAndGet()//当前值加1,返回新值
public final int decrementAndGet()//当前值减1,返回新值
public final int addAndGet(int delta)//当前值增加delta,返回新值
就内部实现上来说,AtomicInteger中保存一个核心字段:
private volatile int value;它就代表了AtomicInteger的当前实际取值。
此外还有一个:
private static final long valueOffset;它保存着value字段在AtomicInteger对象中的偏移量。后面你会看到,这个偏移量是实现AtomicInteger的关键。
和AtomicInteger类似的类还有AtomicLong用来代表long型,AtomicBoolean表示boolean型,AtomicReference表示对象引用。
3.Java中的指针:Unsafe类
在AtomicInteger中compareAndSet()方法:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
有一个特殊的变量unsafe,它是sun.misc.Unsafe类型。这个类封装了一些不安全的操作,类似C语言中指针的操作。
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
方法是一个navtive方法,它的参数含义是:
var1为给定的对象
var2为对象内的偏移量(其实就是一个字段到对象头部的偏移量,通过这个偏移量可以快速定位字段)
var4表示期望值
xvar5要设置的值。如果指定的字段的值等于var4,那么就会把它设置为var5。
不难看出,compareAndSwapInt()方法的内部,必然是使用CAS原子指令来完成的
此外,Unsafe类还提供了一些方法,主要有以下几个(以Int操作为例,其他数据类型是类似的):
public native int getInt(Object o, long offset);//获得给定对象偏移量上的int值
public native void putInt(Object o, long offset, int x);//设置给定对象偏移量上的int值
public native long objectFieldOffset(Field f);//获得字段在对象中的偏移量
public native void putIntVolatile(Object o, long offset, int x);//设置给定对象的int值,使用volatile语义
public native int getIntVolatile(Object o, long offset);//获得给定对象对象的int值,使用volatile语义
public native void putOrderedInt(Object o, long offset, int x);//和putIntVolatile()一样,但是它要求被操作字段就是volatile类型的
这里就可以看到,虽然Java抛弃了指针。但是在关键时刻,类似指针的技术还是必不可少的。这里底层的Unsafe实现就是最好的例子。但是很不幸,JDK的开发人员并不希望大家使用这个类。获得Unsafe实例的方法是调动其工厂方法getUnsafe()。但是,它的实现却是这样:
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if(!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
注意加粗部分的代码,它会检查调用getUnsafe()函数的类,如果这个类的ClassLoader不为null,就直接抛出异常,拒绝工作。因此,这也使得我们自己的应用程序无法直接使用Unsafe类。它是一个JDK内部使用的专属类。
注意:根据Java类加载器的工作原理,应用程序的类由App Loader加载。而系统核心类,如rt.jar中的类由Bootstrap类加载器加载。Bootstrap加载器没有Java对象的对象,因此试图获得这个类加载器会返回null。所以,当一个类的类加载器为null时,说明它是由Bootstrap加载的,而这个类也极有可能是rt.jar中的类。
4.无锁的对象引用:AtomicReference
AtomicReference和AtomicInteger非常类似,不同之处就在于AtomicInteger是对整数的封装,而AtomicReference则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性。在介绍AtomicReference的同时,我希望同时提出一个有关原子操作的逻辑上的不足。
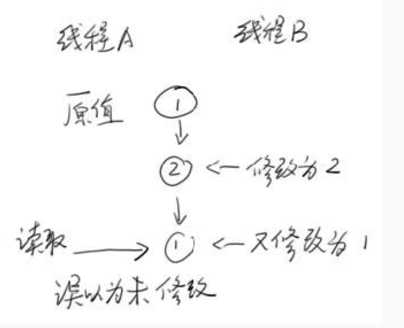
之前我们说过,线程判断被修改对象是否可以正确写入的条件是对象的当前值和期望值是否一致。这个逻辑从一般意义上来说是正确的。但有可能出现一个小小的例外,就是当你获得对象当前数据后,在准备修改为新值前,对象的值被其他线程连续修改了两次,而经过这两次修改后,对象的值又恢复为旧值。这样,当前线程就无法正确判断这个对象究竟是否被修改过,如图:
虽然说这种情况出现的概率不大,但是依然是有可能出现的。因此,当业务上确实可能出现这种情况时,我们也必须多加防范。体贴的JDK也已经为我们考虑到了这种情况,使用AtomicStampedReference就可以很好地解决这个问题。
5.带有时间戳的对象引用:AtomicStampedReference
AtomicReference无法解决上述问题的根本因为是对象在修改过程中,丢失了状态信息。
AtomicStampedReference,它内部不仅维护了对象值,还维护了一个时间戳(我这里把它称为时间戳,实际上它可以使任何一个整数来表示状态值)。当AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新时间戳。
当AtomicStampedReference设置对象值时,对象值以及时间戳都必须满足期望值,写入才会成功。因此,即使对象值被反复读写,写回原值,只要时间戳发生变化,就能防止不恰当的写入。
AtomicStampedReference的几个API在AtomicReference的基础上新增了有关时间戳的信息:
public boolean compareAndSet(V expectedReference,VnewReference,int expectedStamp,int newStamp)//比较设置 参数依次为:期望值 写入新值 期望时间戳 新时间戳
public V getReference()//获得当前对象引用
public int getStamp()//获得当前时间戳
public void set(V newReference, int newStamp)//设置当前对象引用和时间戳
6.数组也能无锁:AtomicIntegerArray
除了提供基本数据类型外,JDK还为我们准备了数组等复合结构。当前可用的原子数组有:AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray,分别表示整数数组、long型数组和普通的对象数组。
这里以AtomicIntegerArray为例,展示原子数组的使用方式。
AtomicIntegerArray本质上是对int[]类型的封装,使用Unsafe类通过CAS的方式控制int[]在多线程下的安全性。它提供了以下几个核心API:
public final int get(int i)//获得数组第i个下标的元素
public final int length()//获得数组的长度
public final int getAndSet(int i, int newValue)//将数组第i个下标设置为newValue,并返回旧的值
public final boolean compareAndSet(int i, int expect, int update)//进行CAS操作,如果第i个下标的元素等于expect,则设置为update,设置成功返回true
public final int getAndIncrement(int i)//将第i个下标的元素加1
public final int getAndDecrement(int i)//将第i个下标的元素减1
public final int getAndAdd(int i, int delta)//将第i个下标的元素增加delta(delta可以是负数)
7.让普通变量也享受原子操作:AtomicIntegerFieldUpdater
将普通变量也变成线性安全的。
在原子包里还有一个实用的工具类AtomicIn-tegerFieldUpdater。它可以让你在不改动(或者极少改动)原有代码的基础上,让普通的变量也享受CAS操作带来的线程安全性,这样你可以修改极少的代码,来获得线程安全的保证。
根据数据类型不同,这个Updater有三种,分别是AtomicIntegerFieldUpdater、AtomicLong-FieldUpdater和AtomicReferenceFieldUpdater。顾名思义,它们分别可以对int、long和普通对象进行CAS修改。
虽然AtomicIntegerFieldUpdater很好用,但是还是有几个注意事项:
第一,Updater只能修改它可见范围内的变量。因为Updater使用反射得到这个变量。如果变量不可见,就会出错。比如如果score申明为private,就是不可行的。
第二,为了确保变量被正确的读取,它必须是volatile类型的。如果我们原有代码中未申明这个类型,那么简单地申明一下就行,这不会引起什么问题。
第三,由于CAS操作会通过对象实例中的偏移量直接进行赋值,因此,它不支持static字段(Unsafe. objectFieldOffset()不支持静态变量)。
8.SynchronousQueue的实现
在对线程池的介绍中,提到了一个非常特殊的等待队列SynchronousQueue。Syn-chronousQueue的容量为0,任何一个对Syn-chronousQueue的写需要等待一个对Syn-chronousQueue的读,因此,Syn-chronousQueue与其说是一个队列,不如说是一个数据交换通道。
对SynchronousQueue来说,它将put()和take()两个功能截然不同的操作抽象为一个共通的方法Transferer.transfer()。
Object transfer(Object e, boolean timed, long nanos)
当参数e为非空时,表示当前操作传递给一个消费者,如果为空,则表示当前操作需要请求一个数据。timed参数决定是否存在timeout时间,nanos决定了timeout的时长。如果返回值非空,则表示数据已经接受或者正常提供,如果为空,则表示失败(超时或者中断)。
SynchronousQueue内部会维护一个线程等待队列。等待队列中会保存等待线程以及相关数据的信息。比如,生产者将数据放入Syn-chronousQueue时,如果没有消费者接收,那么数据本身和线程对象都会打包在队列中等待(因为SynchronousQueue容积为0,没有数据可以正常放入)。
Transferer.transfer()函数的实现是Syn-chronousQueue的核心,它大体上分为三个步骤:
/*
* Basic algorithm is to loop trying one of three actions:
*
* 1. If apparently empty or already containing nodes of same
* mode, try to push node on stack and wait for a match,
* returning it, or null if cancelled.
*
* 2. If apparently containing node of complementary mode,
* try to push a fulfilling node on to stack, match
* with corresponding waiting node, pop both from
* stack, and return matched item. The matching or
* unlinking might not actually be necessary because of
* other threads performing action 3:
*
* 3. If top of stack already holds another fulfilling node,
* help it out by doing its match and/or pop
* operations, and then continue. The code for helping
* is essentially the same as for fulfilling, except
* that it doesn‘t return the item.
*/
1. 如果等待队列为空,或者队列中节点的类型和本次操作是一致的,那么将当前操作压入队列等待。比如,等待队列中是读线程等待,本次操作也是读,因此这两个读都需要等待。进入等待队列的线程可能会被挂起,它们会等待一个“匹配”操作。
2. 如果等待队列中的元素和本次操作是互补的(比如等待操作是读,而本次操作是写),那么就插入一个“完成”状态的节点,并且让他“匹配”到一个等待节点上。接着弹出这两个节点,并且使得对应的两个线程继续执行。
3. 如果线程发现等待队列的节点就是“完成”节点,那么帮助这个节点完成任务。其流程和步骤2是一致的。
无锁机制实现并发访问
标签:交换 额外 存在 nload 复合 访问 nan jar 无锁
原文地址:http://www.cnblogs.com/756623607-zhang/p/6876060.html