标签:bit tcl 台湾 执行 copyto == iunknown var 加法
1.HRESULT 函数返回值
组件API及接口指针中,除了IUnknown::AddRef()和IUnknown::Release()两个函数外,其它所有的函数,都以 HRESULT作为返回值。
想象一个组件的接口函数比如叫Add(),完成2个整数的加法运算,在C语言中,我们可以如下定义:
long Add( long n1, long n2 )
{
return n1 + n2;
}
COM 组件是运行在分布式环境中的。也就是说,这个函数可能运行在“地球另一边”的计算机上,既然运行在那么遥远的地方,就有可能出现服务器关机、网络掉线、运行超时、对方不在服务区......等异常。于是,这个加法函数,除了需要返回运算结果以外,还应该返回一个值------函数是否被正常执行了。
HRESULT Add( long n1, long n2, long *pSum )
{
*pSum = n1 + n2;
return S_OK;
}
如果函数正常执行,则返回 S_OK,同时真正的函数运行结果则通过参数指针返回。如果遇到了异常情况,则COM系统经过判断,会返回相应的错误值。常见的返回值有:
| HRESULT | 值 | 含义 |
| S_OK | 0x00000000 | 成功 |
| S_FALSE | 0x00000001 | 函数成功执行完成,但返回时出现错误 |
| E_INVALIDARG | 0x80070057 | 参数有错误 |
| E_OUTOFMEMORY | 0x8007000E | 内存申请错误 |
| E_UNEXPECTED | 0x8000FFFF | 未知的异常 |
| E_NOTIMPL | 0x80004001 | 未实现功能 |
| E_FAIL | 0x80004005 | 没有详细说明的错误。 |
| E_POINTER | 0x80004003 | 无效的指针 |
| E_HANDLE | 0x80070006 | 无效的句柄 |
| E_ABORT | 0x80004004 | 终止操作 |
| E_ACCESSDENIED | 0x80070005 | 访问被拒绝 |
| E_NOINTERFACE | 0x80004002 | 不支持接口 |
HRESULT 其实是一个双字节的值,其最高位(bit)如果是0表示成功,1表示错误:

在程序中如果需要判断返回值,可以采用SUCCEEDED宏和FAILED宏:
HRESULT hr = 调用组件函数;
if( SUCCEEDED( hr ) ){...} // 如果成功
......
if( FAILED( hr ) ){...} // 如果失败
......
2.UNICODE
计算机发明后,为了在计算机中表示字符,人们制定了一种编码,叫ASCII码。ASCII码由一个字节中的7位(bit)表示,范围是0x00 - 0x7F 共128个字符。他们以为这128个数字就足够表示abcd....ABCD....1234 这些字符了。后来发现,如果需要按照表格方式打印这些字符的时候,缺少了“制表符”。于是又扩展了ASCII的定义,使用一个字节的全部8位(bit)来表示字符了,这就叫扩展ASCII码。范围是0x00 - 0xFF 共256个字符。
中国人利用连续2个扩展ASCII码的扩展区域(0xA0以后)来表示一个汉字,该方法的标准叫GB-2312。后来,日文、韩文、阿拉伯文、台湾繁体(BIG-5)......都使用类似的方法扩展了本地字符集的定义,现在统一称为 MBCS 字符集(多字节字符集)。这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB-2312的软件,就不能在BIG-5的环境下运行(显示乱码),反之亦然。
为了把全世界人民所有的所有的文字符号都统一进行编码,于是制定了UNICODE标准字符集。UNICODE 使用2个字节表示一个字符(unsigned shor int、WCHAR、_wchar_t、OLECHAR)。这下终于好啦,全世界任何一个地区的软件,可以不用修改地就能在另一个地区运行了。虽然我用 IE 浏览日本网站,显示出我不认识的日文文字,但至少不会是乱码了。UNICODE 的范围是 0x0000 - 0xFFFF 共6万多个字符,其中光汉字就占用了4万多个。嘿嘿,中国人赚大发了。
在程序中使用各种字符集的方法:
const char * p = "Hello"; // 使用 ASCII 字符集
const char * p = "你好"; // 使用 MBCS 字符集,由于 MBCS 完全兼容 ASCII,多数情况下,我们并不严格区分他们
LPCSTR p = "Hello,你好"; // 意义同上
const WCHAR * p = L"Hello,你好"; // 使用 UNICODE 字符集
LPCOLESTR p = L"Hello,你好"; // 意义同上
// 如果预定义了_UNICODE,则表示使用UNICODE字符集;如果定义了_MBCS,则表示使用 MBCS
const TCHAR * p = _T("Hello,你好");
LPCTSTR p = _T("Hello,你好"); // 意义同上
在上面的例子中,T是非常有意思的一个符号,它表示使用一种中间类型,既不明确表示使用 MBCS,也不明确表示使用 UNICODE。那到底使用哪种字符集?编译的时候决定吧。使用 T 类型,是非常好的习惯,严重推荐!
3.BSTR
COM 中除了使用一些简单标准的数据类型外,字符串类型需要特别重点地说明一下。COM组件是运行在分布式环境中的。通俗地说,你不能直接把一个内存指针直接作为参数传递给COM函数。你想想,系统需要把这块内存的内容传递到“地球另一 边”的计算机上,因此,我至少需要知道你这块内存的尺寸吧?不然让我如何传递呀?传递多少字节呀?!而字符串又是非常常用的一种类型,因此 COM 设计者引入了 BASIC 中字符串类型的表示方式---BSTR。BSTR 其实是一个指针类型,它的内存结构是:(输入程序片段 BSTR p =::SysAllocString(L"Hello,你好");断点执行,然后观察p的内存)
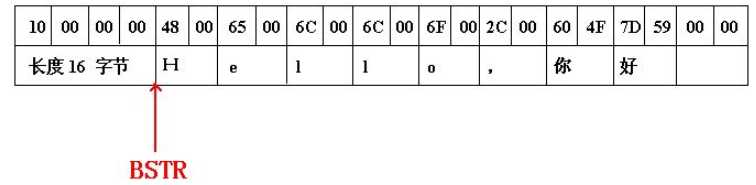
BSTR 是一个指向 UNICODE 字符串的指针,且 BSTR 向前的4个字节中,使用DWORD保存着这个字符串的字节长度(没有含字符串的结束符)。因此系统就能够正确处理并传送这个字符串到“地球另一 边”了。特别需要注意的是,由于BSTR的指针就是指向 UNICODE 串,因此
BSTR 和 LPOLESTR 可以在一定程度上混用,但一定要注意:
有函数 fun(LPCOLESTR lp),则你调用 BSTR p=...; fun(p); 正确
有函数 fun(const BSTR bstr),则你调用 LPCOLESTR p=...; fun(p); 错误!!!
有关 BSTR 的处理函数:
| API 函数 | 说明 |
| SysAllocString() | 申请一个 BSTR 指针,并初始化为一个字符串 |
| SysFreeString() | 释放 BSTR 内存 |
| SysAllocStringLen() | 申请一个指定字符长度的 BSTR 指针,并初始化为一个字符串 |
| SysAllocStringByteLen() | 申请一个指定字节长度的 BSTR 指针,并初始化为一个字符串 |
| SysReAllocStringLen() | 重新申请 BSTR 指针 |
|
CString 函数 |
说明 |
| AllocSysString() | 从 CString 得到 BSTR |
| SetSysString() | 重新申请 BSTR 指针,并复制到 CString 中 |
|
CComBSTR 函数 ATL 的 BSTR 包装类。在 atlbase.h 中定义 |
|
| Append()、AppendBSTR()、AppendBytes()、ArrayToBSTR()、BSTRToArray()、AssignBSTR()、Attach()、Detach()、Copy()、CopyTo()、Empty()、Length()、ByteLength()、ReadFromStream()、WriteToStream()、LoadString()、ToLower()、ToUpper() 运算符重载:!,!=,==,<,>,&,+=,+,=,BSTR | 太多了,但从函数名称不能看出其基本功能。详细资料,查看MSDN 吧。另外,左侧函数,有很多是 ATL 7.0 提供的,VC6.0 下所带的 ATL 3.0 不支持。 由于我们将来主要用 ATL 开发组件程序,因此使用 ATL 的 CComBSTR 为主。VC也提供了其它的包装类 _bstr_t。 |
各种字符串类型之间的转换:
函数 WideCharToMultiByte(),转换 UNICODE 到 MBCS。
函数 MultiByteToWideChar(),转换 MBCS 到 UNICODE。
使用 ATL 提供的转换宏:
| A2BSTR | OLE2A | T2A | W2A |
| A2COLE | OLE2BSTR | T2BSTR | W2BSTR |
| A2CT | OLE2CA | T2CA | W2CA |
| A2CW | OLE2CT | T2COLE | W2COLE |
| A2OLE | OLE2CW | T2CW | W2CT |
| A2T | OLE2T | T2OLE | W2OLE |
| A2W | OLE2W | T2W | W2T |
上表中的宏函数,其实非常容易记忆:
| 2 | 好搞笑的缩写,to 的发音和 2 一样,所以借用来表示“转换为、转换到”的含义。 |
| A | ANSI 字符串,也就是 MBCS。 |
| W、OLE | 宽字符串,也就是 UNICODE。 |
| T | 中间类型T。如果定义了 _UNICODE,则T表示W;如果定义了 _MBCS,则T表示A |
| C | const 的缩写 |
使用 ATL 转换宏,由于不用释放临时空间,所以使用起来非常方便。但是考虑到栈空间的尺寸(VC 默认2M),使用时要注意几点:
1)只适合于进行短字符串的转换;
2)不要试图在一个次数比较多的循环体内进行转换;
3)不要试图对字符型文件内容进行转换,因为文件尺寸一般情况下是比较大的;
4)对情况 2 和 3,要使用 MultiByteToWideChar() 和 WideCharToMultiByte();
4.VARIANT
C++、BASIC、Java、Pascal、Script......计算机语言多种多样,而它们各自又都有自己的数据类型,COM产生目的,其中之一就是要跨语言(注3)。而 VARIANT 数据类型就具有跨语言的特性,同时它可以表示(存储)任意类型的数据。从C语言的角度来讲,VARIANT其实是一个结构,结构中用一个域(vt)表示------该变量到底表示的是什么类型数据,同时真正的数据则存贮在 union空间中。结构的定义太长了(虽然长,但其实很简单)大家去看 MSDN 的描述吧。
VARIANT有一个变量vt, 类型为VARTYPE,指定了数据类型:比如:VT_I2,VT_I4,VT_R4,VT_R8等,分别表示short,long,float,double,对应的值分别存在iVal,lVal,fltVal,dblVal中。
注意表示bool值时:
要写成:VARIANT v; v.vt=VT_BOOL; v.boolVal=VARIANT_TRUE;
不能写成:v.boolVal=true;
| 类型 | 字节长度 | 假值 | 真值 |
| bool | 1(char) | 0(false) | 1(true) |
| BOOL | 4(int) | 0(FALSE) | 1(TRUE) |
| VT_BOOL | 2(short int) | 0(VARIANT_FALSE) | -1(VARIANT_TRUE) |
v.boolVal=true 这样赋值,那么将来 if(VARIANT_TRUE==v.boolVal) 的时候会出问题(-1 != 1)。但是你注意观察,任何布尔类型的“假”都是0,因此作为一个好习惯,在做布尔判断的时候,不要和“真值”相比较,而要与“假值”做比较。
VARIANT 保存字符串:VARIANT v; v.vt=VT_BSTR; v.bstrVal=SysAllocString(L"Hello,你好");
(1)VARIANT的初始化
VARIANT va;
va.vt=VT_I4;
va.lVal=5;
或者:
VARIANT va;
VariantInit(&va);
(2)VARIANT的拷贝 VariantCopy
VARIANT va;
VARIANT va2;
va.vt=VT_I4;
va.lVal=5;
VariantCopy(&va2,&va);
这样就将 va的内容,拷贝到va2了。它会根据不同的数据类型,执行深拷贝或者浅拷贝。
(3)VARIANT的销毁 VariantClear
VariantClear(&va);
标签:bit tcl 台湾 执行 copyto == iunknown var 加法
原文地址:http://www.cnblogs.com/xiaojianliu/p/6877930.html