标签:获取 读取数据 table 自己的 block 提交 相关 clu com
看到这个题目,我们会有很多疑问:什么是分布式大数据系统中的全局数据管理?为什么要从全局对数据进行管理?这种对数据从全局进行分布和调度的策略是在什么样的背景下产生的?如果我们不解决全局数据管理的问题,分布式大数据系统中将会面临一些什么样的风险?
总的来说:基于大数据,云计算的需求,加快了分布式系统的发展;开源分布式系统的发展,让海量数据存储和处理变的简单;产生了很多为了解决特定问题,服务特定业务的专有集群;集群之间数据无法共享,存在冗余甚至重复,迁移和复制代价高昂,同时还面临数据校验,验证和生命周期等各种复杂问题;如何实现多集群之间的数据共享,去重,逻辑上的规划,物理上的分布成为一个无法回避又急需解决的问题。
在如今的很多大数据应用场景中,由于不同的业务线和数据来源,不同的数据可能分布在不同的大数据系统中。这些数据彼此之间有着关联,却无法从大数据系统层面实现共享。不同的系统中,如果要访问到其他集群的数据,需要将数据进行来回的拷贝和传输,即数据搬迁。即使有了数据搬迁,数据在全局上仍然存在重复冗余、一致性、数据校验、生命周期等等一系列的问题。怎么样解决在不同系统之间数据和计算在全局上的优化、管理和调度?
全局数据管理要解决的是存储的问题,而目前所有大数据系统的底层解决存储问题无一例外都是使用分布式文件系统(以下简称为DFS)计数。
一个典型的DFS通常分为三个大的组件:
最左边是Client,即客户端,用来提供用户访问DFS的组件,通过Client用户可以在DFS中创建目录;
中间是DFS的Master组件,通常一个DFS中肯定会有一个Master节点, DFS中必然会有很多的目录、子目录、文件等等,且通常都是按照树型的结构一层一层地向子目录和最终的叶子节点(文件)延伸,所以DFS的Master中缓存了DFS的整个目录数;
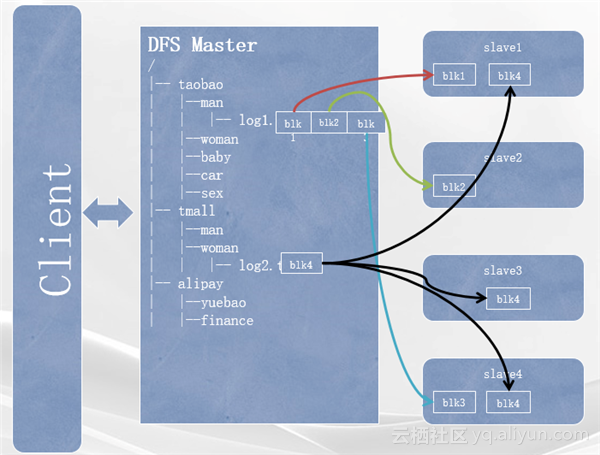
如图中中间方框所示,log1.txt这个文件就是在根——淘宝——man这个目录下。由于DFS中文件的存储是分块存储,所以Master节点还保存了所有文件的分块信息以及这些分块都是存在哪些slave节点的位置信息。如图,log1.txt这个文件有三个分块数据,分别叫做block1、block2、block3,并且这几个block实际的数据块是分别存储在slave1、slave2 和slave4这三个slave节点上。
图中的右边就是DFS中的slave节点。通常一个DFS中至少会有一台到多台(不固定,两台甚至成千上万台)的slave节点。slave节点就是DFS中文件的数据存储的最终地点,即属于某些文件的分块。这些分块跟其他机器上的某些分块按照一定的顺序组合起来就能拼凑成一个完整的数据文件。另外在DFS中数据块的存储副本是可以进行控制的。比如图中的log2.txt文件只有一个block4,但是这个block被分别存储在slave1、slave3、slave4这三台slave机器上。那么这个log2.txt文件的副本数就是三。也就是说DFS中有这个文件所有block的三个副本。
由于DFS通常都是在多机的环境下,而机器越多,某一时间有机器发生故障的概率就越高。当集群规模达到一定的程度的时候,比如几千上万台磁盘或机器每天发生故障甚至宕机几乎就成了常态。即使在这种情况,DFS通常也是能够保证任何一个文件的完整性的。
数据冗余策略就是将一份数据分别在不同的机器上进行多份的冗余存储。数据丢失的时候并不会造成数据的根本丢失。而一旦DFS发现某个文件的某个block在整个集群中的副本数小于其期望的数字的时候(比如刚才的例子中三),那么DFS就会自动地将剩余的副本重新拷贝到其他的slave节点上直到其冗余数达到期望的副本数。
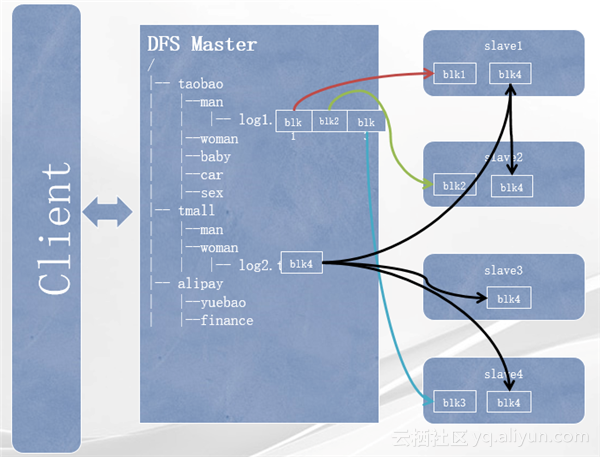
如上图,log1.txt文件被切成三个block,每个block都只有一个副本,分别存储在三台slave机器上。此时当slave2这台机器宕机的时候,我们就会发现集群中所有其他机器都已经没有block2这个数据块的数据。此时如果用户来读取log1文件,就会发现读完block1以后无法再获取block2的数据。相当于log1.txt中出现了一个数据断层,这个文件的数据完整性就遭到了破坏,除非按图中所示,slave2这台机器恢复并且数据没有丢失,此时用户在读取数据的时候就会从slave2上找到block2数据块。在很多情况下,机器宕机很也可能无法像这里所说的slave2恢复。在这种情况下,如log1.txt这样block副本只有1,并且block在slave2这台机器上的文件就可能用户无法恢复,集群出现丢失数据的情况。
数据冗余策略能够很大程度缓解这个问题。图中的log2.txt文件,由于它的副本数是3,所以假设当slave3这台机器宕机,此时block4这个数据块的副本数变成了2,但是并不影响这个数据的完整,因为slave1和slave4上分别都含有这份数据的block副本。此时DFS发现block4只有两个副本,小于其期望的三个副本,于是DFS会从其他拥有这个block的机器上将这份数据进行一次拷贝,拷贝到另外的一台机器上。这样 block4这个数据块的冗余度重新达到三,数据的完整性没有遭到破坏,同时数据的可靠性也跟宕机前是一样的。
在分布式系统中,分布式节点间的距离反映了两台机器之间在某个层面上的远近程度。比如,两台机器之间的网络带宽越宽,可以理解为距离越近,反之则越远。这个距离对于数据本身的分布策略起着非常重要的指导作用。在DFS中最简单的距离计算法则是步长计算法则。其原理就是在网络拓扑图中从当前节点走到指定的节点需要在拓扑图上走几步即为这两个节点之间的步长。在实际的环境中,会在步长的计算法则的基础上根据实际的物理集群环境来调整一些权重,才能形成能够描述整个集群环境下的距离抽象模型。分布式节点间的距离计算法则对数据分布起着非常重要的指导作用,是决定数据分布的一个非常重要的决定因素。
在DFS中,数据并不是像普通的单机文件系统那样整块地进行文件全部数据的存储,而是将文件数据进行切块然后分别存储。比如一个193MB的文件,如果按照64MB进行划分,那么这个文件就会被切成四个block,前三个64MB,最后一个1MB。冗余存储策略导致每个block就会有多个副本,分布在集群的各个机器上。常见的分布式策略通常遵循如下的一些原则:让同一个block的多个副本尽量分布在不同的磁盘、不同的机器、不同的机架以及不同的数据中心。
分布式计算的就近原则(既计算调度的localization):将计算发送到数据所在的节点上运行;将计算发送到离数据最近的节点上运行;将计算发送到数据所在的IDC运行。
分布式环境中,机器宕机可能是常态,当某些正在运行的计算任务的机器宕机的时候,分布式计算系统是怎么进行容错的?分布式计算作业中,每一个计算任务只处理整个计算作业中某一部分数据,而这一部分数据通常就是分布在某些slave节点上的block块。而由于DFS中的block都是冗余的,也因此对某个block进行计算的机器宕机的时候,由于这块数据在其他节点上仍然有完好的副本,分布式计算系统完全可以将终端的任务重新发送到另外一台机器上进行计算。某些个别机器的宕机就不会影响到计算本身的完整性。
考虑一种最极端的情况,那就是数据不仅分布在不同的集群上,而且集群还分布在不同的数据中心甚至不同的地域的情况。在这样的情况下,我们通过什么样的方式来规划集群,达到数据共享并减少冗余和重复、高效访问的目的?
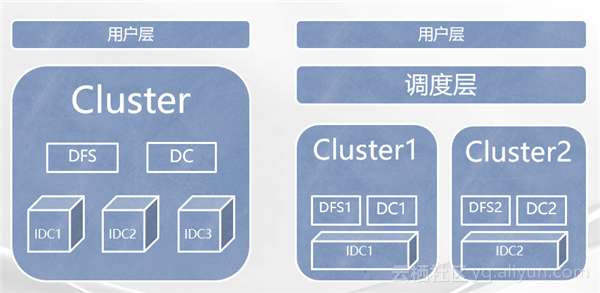
在实践中,阿里使用过两种集群规划的形式,分别如上图所示。如左图,在多个数据中心之间架设统一的分布式文件系统和分布式计算系统,让这些数据中心里的所有机器像一个整体一样,组成一个统一的分布式系统,让系统屏蔽掉内部跨数据中心的物理细节,并通过智能的数据、分布策略和计算调度策略来规避由于跨数据中心的物理网络限制。如右图所示,其方案是分别在每一个数据中心上架设独立的分布式文件系统和分布式计算系统,组成多个独立的分布式系统组合。但在这些系统的上层架设一个屏蔽掉下面多系统环境的调度层来达到跨数据中心的系统统一提供给用户层服务的目的。
云梯集群使用的是上述第一种集群规划方案。下图就是云梯跨集群方案的架构图。
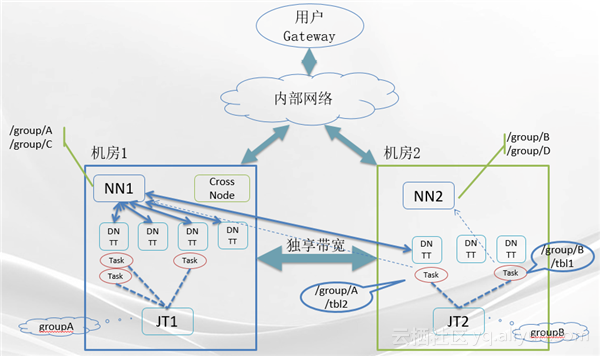
从架构图中可以看出,云梯集群跨越了两个数据中心,也就是机房一和机房二。机房一和机房二的所有机器构成了一个统一的分布式文件系统。其中一部分文件系统的Name space在机房一的Master上,另外一部分的Name space在机房二的Master上。机房二中运行的计算作业如果需要访问数据就在机房二,那么就直接从机房二的Master上进行访问,不需要跨越机房间的带宽。而如果机房二中的计算作业要访问的是机房一中的数据,则有两种选择:第一是直接通过机房间的独享网络带宽来直读,这种方式对数据的访问次数很少的情况下是可行的,但如果对同一份数据要跨机房的访问数据很多就会产生多次访问的带宽叠加,代价下就会成倍地上升;第二则是让机房一中需要被机房二中访问到的数据将其中一个或多个副本放置在机房二,这样当机房二中的计算任务需要访问机房一中的数据时会发现这份数据在机房二上也有副本,于是计算会发送到机房二中的计算节点上进行计算,大大节约了数据跨机房直读的带宽和效率。
ODPS集群使用的是上述第二种集群规划方案。
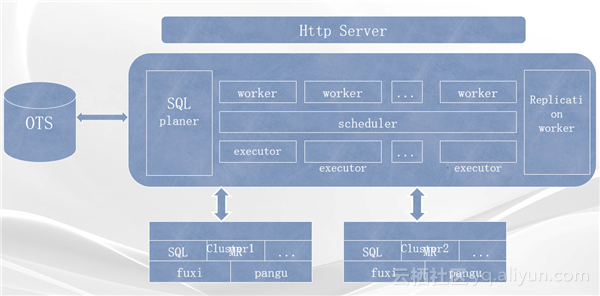
如上图中所示,下面是分别叫做伏羲的分布式计算系统和叫做盘古的分布式文件系统。在机制上提供了多种分布式计算模型如SQL、流式计算、内存计算等多种计算模型的ODPS集群。ODPS提供多种计算模型如分布式的SQL、MyProduce等。所有这些计算任务都在这套架构中进行调度和管理并最终提交到底层的伏羲调度系统,处理存储在盘古分布式文件系统上的数据。在ODPS的下方是多个独立的分布式集群,分别叫做Cluster1和Cluster2等等。这些系统都是一些独立的分布式文件系统和分布式计算系统的组合,但他们都是为ODPS服务。中间方框最右边的Replication worker组件就是用来管理ODPS中跨集群数据分布和管理策略的组件
在ODPS中数据并不一定是以最原始的分布式文件的方式呈现给用户,而是以一种更加抽象的方式提供数据视角,用这种方式将用户从简单的文件操作中解放出来,只需要关心自己业务逻辑相关的数据视图。其中最常用的两种数据视图分别是:Table,适用于用户是SQL用户,用户运行分布式作业的方式是通过提交SQL语句来执行,这样用户通常来说并不关心数据的物理存储而是以表这样的视图来看自己的数据;Volume,也就是原始文件数据,这样用户能够通过Volume看到自己需要处理的原始文件并通过自己写MyPreduce或者其他类型的分布式作业来对数据进行处理。
对于一些SQL作业,可能需要读到不同表里的数据,而这些表的数据又不属于同样的业务部门,将这些表进行关联计算能够挖掘出一些更加有价值的商业数据,也因此这些表之间就产生了关系,称之为数据表之间的血缘关系。对于这种场景,如果这些表刚好又分布在不同的物理集群或者不同的数据中心,于是就产生了数据的跨集群依赖问题。
如果这种跨集群数据依赖的数据量非常大,势必会对两个数据中心之间的带宽造成很大的压力,进而拖慢很多跨集群读取作业的计算速度。如果对同一个表的数据进行反复地读取,那么造成的网络流量就会成倍地增加。有没有一种降低网络带宽消耗的同时又能满足跨集群数据依赖需求的解决方案呢?
ODPS中引入了跨集群复制系统,也就是刚刚提到的ODPS架构中最右边的Replication worker所做的工作,其运行的本质就是当发现某一份数据被跨集群的其他数据依赖,并且依赖程度非常高的时候,Replication system会发现这种依赖并在这份数据被跨集群使用之前将这份数据跨集群地拷贝到其依赖的其他集群上,并设置这份数据在其他集群上的生命周期。通过这种智能的方式就解决了数据被跨集群依赖同时又被多次跨集群读取造成了网络带宽过度消耗的问题。也因为生命周期的引入也不会对数据造成过多的副本而造成存储空间的浪费。ODPS Replication system就是用来做上述这种动态跨集群的复制和生命周期回收的系统,其内部系统结构如下图所示。
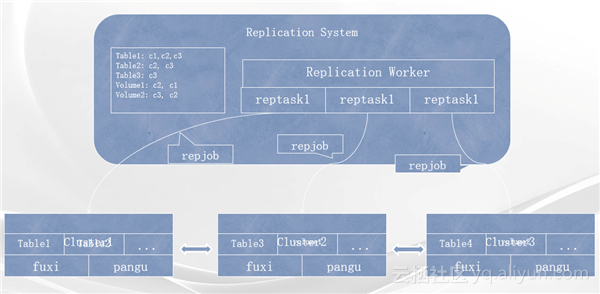
从架构图中可以看到,下面不管有多少独立的集群,Replication system能够在他们之间自动地进行数据的拷贝。Replication worker能够智能地扫描所有的表和Volume。当发现其中一些表或者Volume中的部分数据被跨集群的其他数据依赖的时候,就会发起一个Replication task,每一个Replication task就会提交一系列的Replication job到cluster中,进行这些数据从源集群到目的集群的拷贝。同时在每一次扫描中,当发现一些已经跨集群拷贝的数据超过了其生命周期,则表示这份数据已经不再被其他集群的数据依赖,这个时候就回收这部分数据,也就是将些已经跨集群拷贝到其他集群的数据进行删除,以回收存储空间。
标签:获取 读取数据 table 自己的 block 提交 相关 clu com
原文地址:http://www.cnblogs.com/liangyan/p/6878653.html