标签:fit 文件 ima 聚类算法 r语言 查看 1.2 max 效果
本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤。
1. 载入并了解数据集;
2. 调用聚类函数进行聚类;
3. 查看聚类结果描述;
4. 将聚类结果图形化展示;
5. 选择最优center并最终确定聚类方案;
6. 图形化展示不同方案效果并提交分析报表。
1. 载入并了解数据集
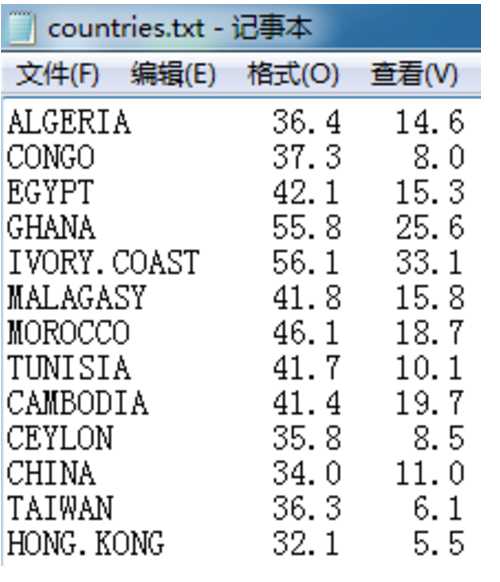
1.1 从网上下载一份txt格式的关于人口出生率统计的数据(countries.txt)。其内容大致如下:
1.2 载入数据集countries.txt:

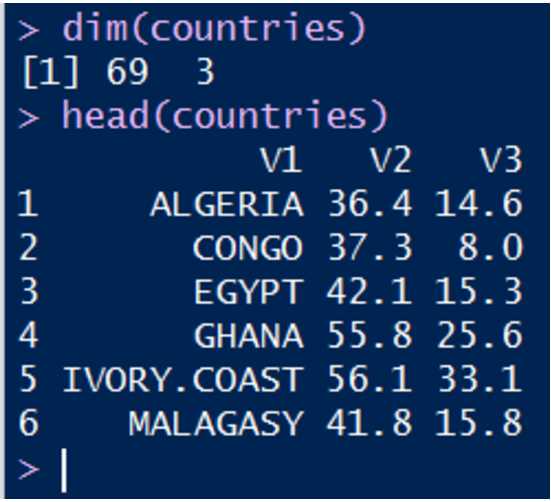
1.3 查看相关文件信息,如维度,文件具体内容:
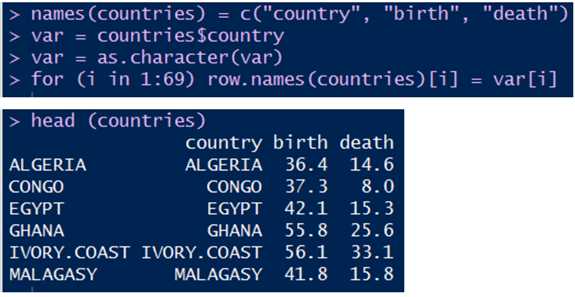
1.4 给数据集行列改名,并查看改名后的结果:
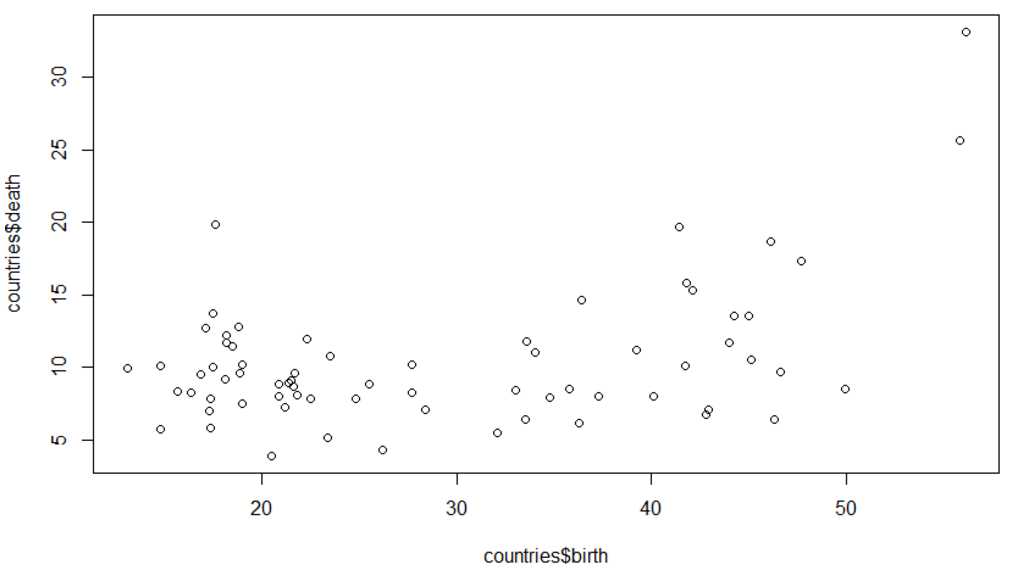
1.5 画出所有样本点:
2. 调用聚类函数进行聚类

kmeans 函数的原型为:kmeans (x, centers, iter.max=10, nstart=1, alogorithm=c("Hartigan-Wong", "Lloyd", "For-gy", "MacQueen"))。
这里解释下函数 kmeans 中的几个形参:
- x:进行聚类分析的数据集;
- centers:簇个数;
- iter.max:最大迭代次数;
- nstart:选择随机中心点的次数 (选择结果最优的那次随机质心);
- alogorithm:具体实现算法。默认为Hartigan-Wong。
3. 查看聚类结果
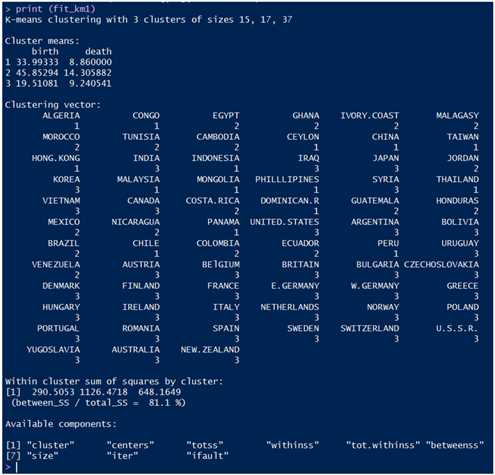
结果内容从上至下分别为:
- 每个簇的样本数;
- 每个簇的质心;
- 每个样本的聚类结果;
- 本次聚类的相关统计信息:包含组内平方和,总平方和,组间平方和,以及组间平方和/总平方和。显然它越大越好;
- 最下面的那部分是指聚类结果数据集fit_km1中的各个变量(也即上面的那些信息,如fit_km1$size就等于3)。
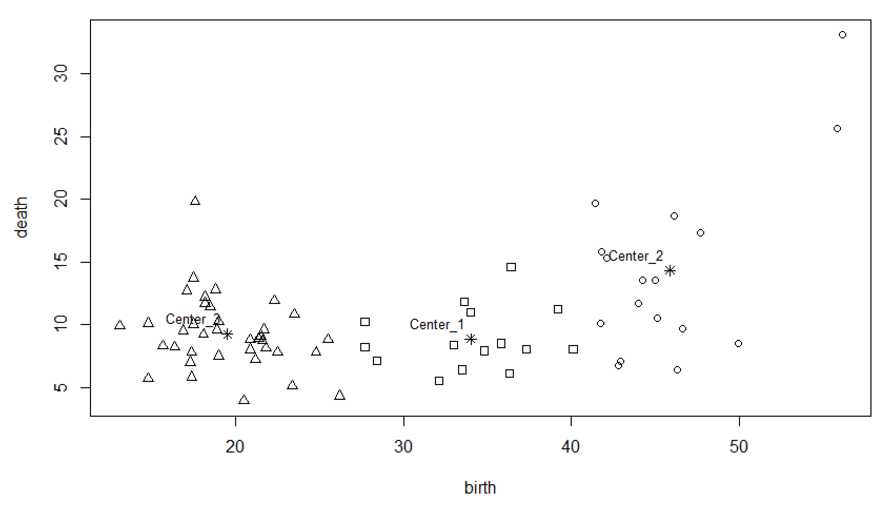
4. 将聚类结果图形化展示

5. 选择最优center并最终确定聚类方案
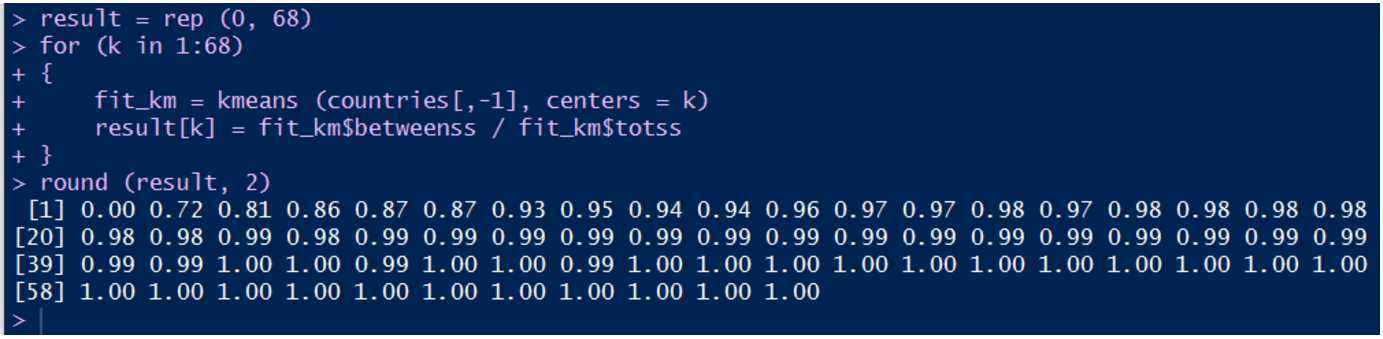
很显然,当k超过了8之后,聚类的结果波动就不大了。
可做图形象化的展示此现象:

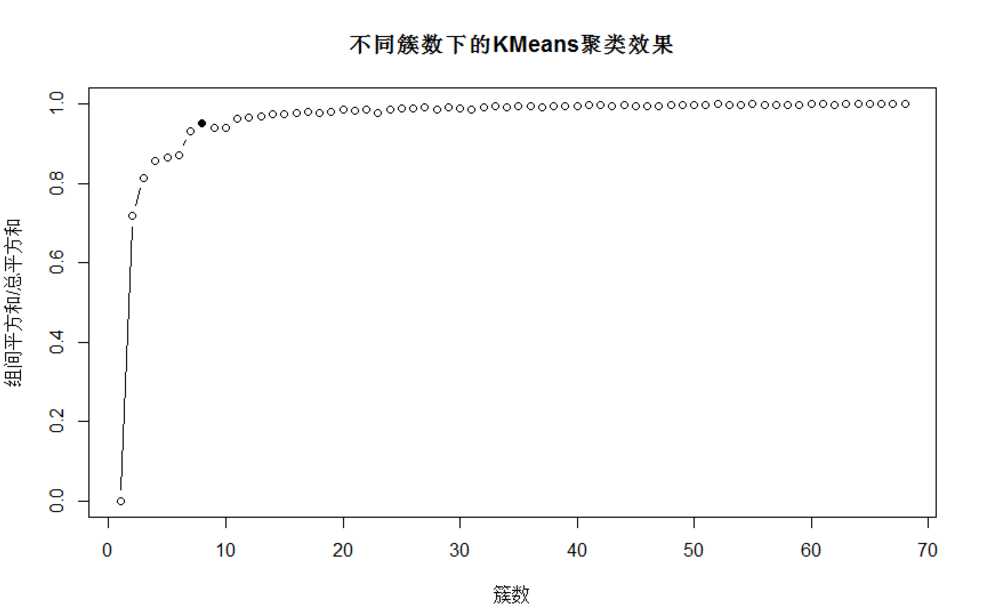
6. 用 k=8 进行聚类,然后看看和中国属于一类的国家有哪些。

除了 k 的大小,还可以通过调整迭代次数、选择中心点次数、重新实现算法等方式实现最优聚类。
另外,本文所讲的只是最为经典的KMeans聚类,更多更好玩的聚类算法,请查阅相关论文或相关R语言包的说明文档。
标签:fit 文件 ima 聚类算法 r语言 查看 1.2 max 效果
原文地址:http://www.cnblogs.com/muchen/p/6883342.html