标签:html exp 技术 sel roc pac 含义 max line
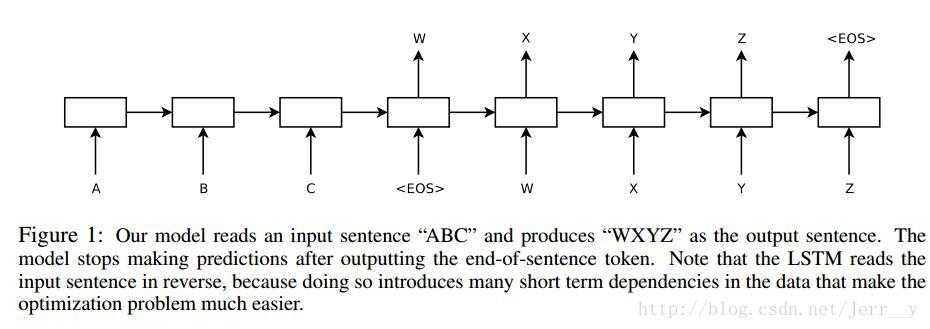
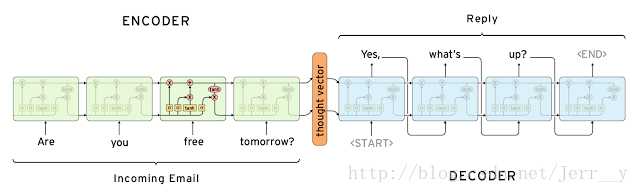
从图上可以看出来,decode的过程其实都是从encode的最后一个隐层开始的,如果encode输入过长的话,会丢失很多信息,所以设计了attation机制。
attation机制的decode的过程和原来的最大的区别就是,它输出的不只是基于本时刻的h,而是基于本时刻的h和C的concat矩阵。
那么C是什么,C就是encode的h的联合(见最后一张图的公式),含义非常明显了,就是我在decode的时候,不但考虑我现在decode的隐层的情况,同时也考虑到encode的隐层的情况,那么关键是encode的隐层那么多,你该怎么考虑了,这就是attation矩阵的计算方式。。目前的计算方式是,这个时刻decode的隐层和encode的所有隐层做个对应,最后一张图非常明白
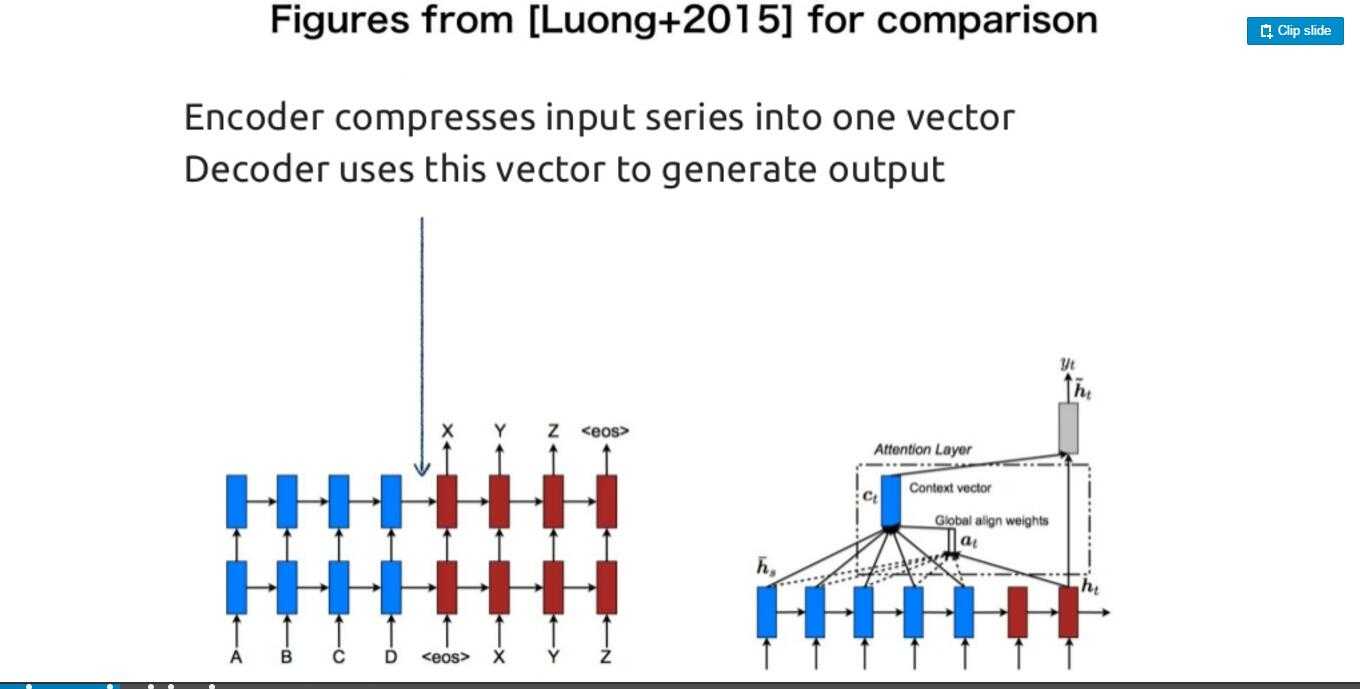

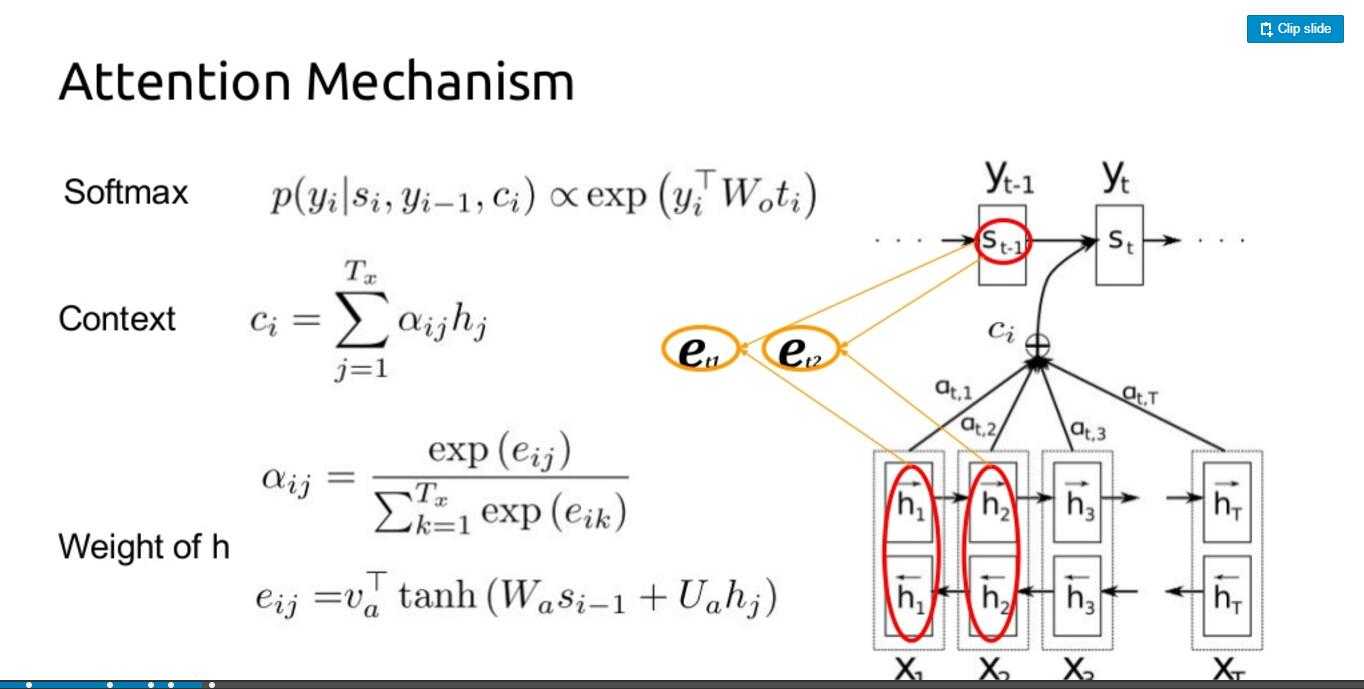
如果你还没有理解,看这个公式,输入的d‘t就是我上面说的C,把这个和dt concat就是本时刻输出的隐层
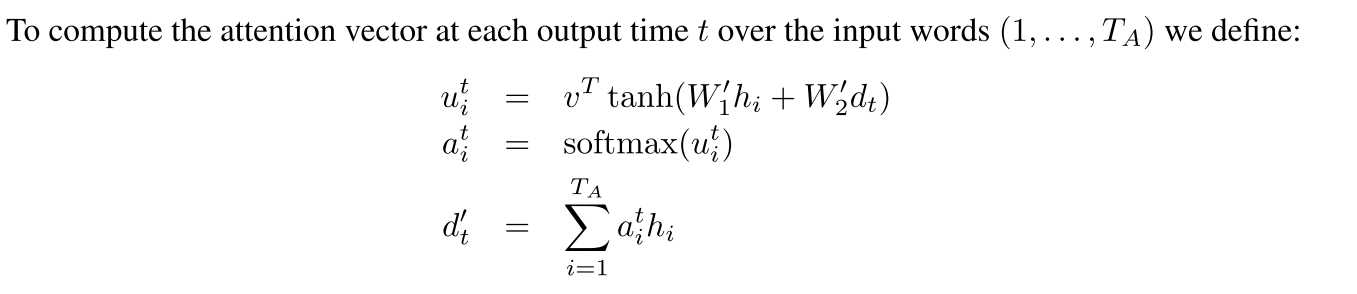
其实实现起来不复杂,就是在decode的时候,隐层和encode的隐层对应一下,然后concat一下:
下面这个代码是在github上找的,两个隐层对应的方式可能跟上面说的不一样,但是原理都差不多,看这个代码感受一下这个流程。
s = self.encoder.zero_state(self.batch_size, tf.float32) encoder_hs = [] with tf.variable_scope("encoder"): for t in xrange(self.max_size): if t > 0: tf.get_variable_scope().reuse_variables() x = tf.squeeze(source_xs[t], [1]) x = tf.matmul(x, self.s_proj_W) + self.s_proj_b h, s = self.encoder(x, s) encoder_hs.append(h) encoder_hs = tf.pack(encoder_hs) s = self.decoder.zero_state(self.batch_size, tf.float32) logits = [] probs = [] with tf.variable_scope("decoder"): for t in xrange(self.max_size): if t > 0: tf.get_variable_scope().reuse_variables() if not self.is_test or t == 0: x = tf.squeeze(target_xs[t], [1]) x = tf.matmul(x, self.t_proj_W) + self.t_proj_b h_t, s = self.decoder(x, s) h_tld = self.attention(h_t, encoder_hs) oemb = tf.matmul(h_tld, self.proj_W) + self.proj_b logit = tf.matmul(oemb, self.proj_Wo) + self.proj_bo prob = tf.nn.softmax(logit) logits.append(logit) probs.append(prob) def attention(self, h_t, encoder_hs): #scores = [tf.matmul(tf.tanh(tf.matmul(tf.concat(1, [h_t, tf.squeeze(h_s, [0])]), # self.W_a) + self.b_a), self.v_a) # for h_s in tf.split(0, self.max_size, encoder_hs)] #scores = tf.squeeze(tf.pack(scores), [2]) scores = tf.reduce_sum(tf.mul(encoder_hs, h_t), 2) a_t = tf.nn.softmax(tf.transpose(scores)) a_t = tf.expand_dims(a_t, 2) c_t = tf.batch_matmul(tf.transpose(encoder_hs, perm=[1,2,0]), a_t) c_t = tf.squeeze(c_t, [2]) h_tld = tf.tanh(tf.matmul(tf.concat(1, [h_t, c_t]), self.W_c) + self.b_c) return h_tld
参考文章:
https://www.slideshare.net/KeonKim/attention-mechanisms-with-tensorflow
https://github.com/dillonalaird/Attention/blob/master/attention.py
http://www.tuicool.com/articles/nUFRban
http://www.cnblogs.com/rocketfan/p/6261467.html
http://blog.csdn.net/jerr__y/article/details/53749693
标签:html exp 技术 sel roc pac 含义 max line
原文地址:http://www.cnblogs.com/dmesg/p/6884622.html