标签:技术分享 文件的 contain master 磁盘 map 统计 导致 检索
一、hadoop的起源
Apache Lucene
开源的高性能全文检索工具包
Apache Nutch
开源的web搜索引擎
google的三篇论文
GFS -> HDFS
MapReduce -> MapReduce
BigTable -> HBase
Apache Hadoop
大规模数据处理
二、hadoop的发展
* Common
工具、服务
hadoop1.x
* MapReduce
对海量数据的处理
分布式
思想:分而治之
大数据集分为小的数据集
每个数据集,进行逻辑业务处理(map)
合并统计数据结果(reduce)
* HDFS
存储海量数据
分布式
数据安全性
副本数据(3份)
数据是以block的方式进行存储的
NameNode
* 内存
* 本地磁盘
* fsimage:镜像文件
* edites:编辑日志
hadoop2.x
* YARN
分布式资源管理框架
* 管理整个集群的资源(内存、CPU核数)
* 分配调度集群的资源
三、hadoop模块
Hadoop项目主要包括一下四个模块:
Hadoop Common:
为其他Hadoop模块提供基础设施
Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统
Hadoop MapReduce:
一个分布式的离线并行计算框架
Hadoop YARN:
一个新的MapReduce框架,任务调度与资源管理
四、HDFS系统架构
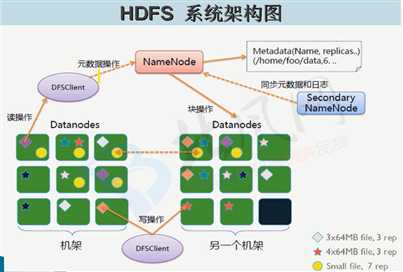
主节点:NameNode
用它来存储文件的元数据(文件目录、文件属性、每个文件的块列表和块所在DataNode等)
从节点:DataNode
在本地文件系统存储文件块数据,以及数据块的校验和
Secondary NameNode
辅助Namenode,获取HDFS元数据的快照(合并fsimage和edites文件)
五、YARN架构图
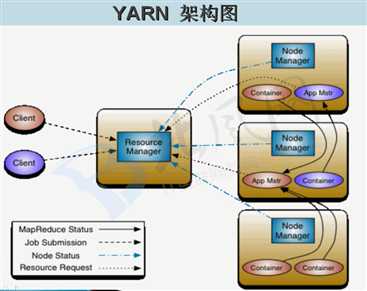
ResourceManager 资源管理
* 处理客户端请求
* 启动/监控ApplicationMaster
* 监控NodeManager
* 资源分配与调度
NodeManager 节点资源管理
* 单个节点上的资源管理
* 处理来自ResourceManager的命令
* 处理来自ApplicationMaster的命令
ApplicationMaster 应用的管理者
* 数据切分
* 为应用程序申请资源,并分配给内部的任务
* 任务监控与容错
Container 资源容器
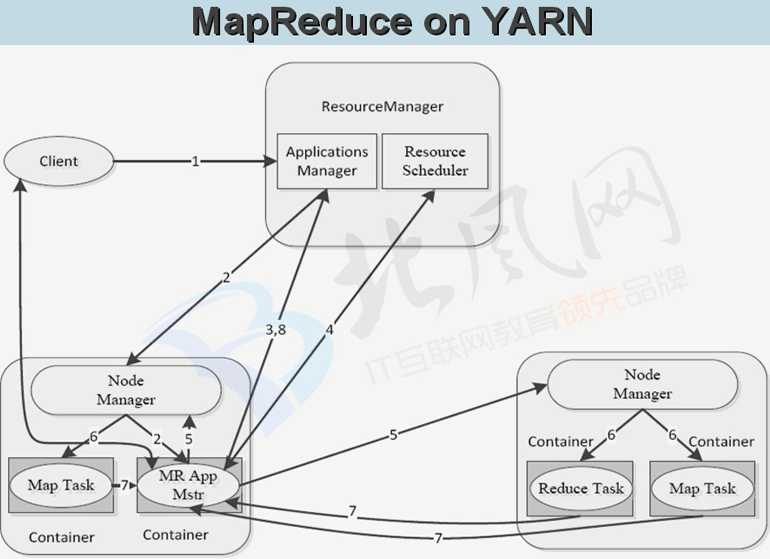
六、离线计算框架 MapReduce
计算分两个阶段:
* Map 处理
* Reduce 汇总
shuffle(洗牌)连接Map和Reduce两个阶段
* Map Task 将数据写到本地磁盘
* Reduce Task 从每个Map Task上读取一份数据
仅适合离线批处理
* 具有很好的容错性和扩展性
* 适合简单的批处理任务
缺点明显
* 启动开销大、过多使用磁盘导致效率低下等
七、MapReduce在YARN上执行的原理图
标签:技术分享 文件的 contain master 磁盘 map 统计 导致 检索
原文地址:http://www.cnblogs.com/share100/p/6886638.html