标签:ascii 概念 还需要 数据 语言 自己 整数 x64 数据类型
先看这段代码

通过指针可以直接访问内存,而在C#中这属于不安全操作,为了能让代码编译运行因此都要带上unsafe,这个不用管它。这段代码主要是借助单字节数据类型byte,直接访问内存,查看各种数据类型的数据在内存的存放情况。在往常认为整数0,1,2,3,4,5……之类的存放在内存的就是转换成二进制再放进去;而字符则是先通过字符编码转换,比如ASCII码A,B,C,D转换成01000001,01000010,01000011再放进去。当然这个层次还不够细。想当年在大学时代知道这些还算过得去了。直到最近再去看计算机科学之类的书籍才加深了自己对这方面的认知。
在学C的时候都有提过无符号数,而我们通常使用的都是有符号数。在整形而言有符号整形而无符号整形已是两套不同的编码:无符号整形是直接把十进制数转换成二进制;有符号整形需要把数转换成补码。补码原码反码之类的在大学里经常接触。但是记忆中老师好像没提到补码是存无符号整形的,倒是想再翻翻以前的教材里有没有提到。由于整形有short,int,long三种不同长度,如果二进制值超出了所存放类型的长度就会把高位舍去,这就造成所谓的数据溢出。有符号和无符号数的区别在于多了个符号,所以补码是把最高位留着作为符号位,既然二进制位的长度是定的,所以补码中表示数据的位数就少了一位,因此有符号数的最大正数会比无符号数的最大整数要小了。这好像扯远了。
虽然这些数字和字符转换成0101这样的二进制编码后就能存放在内存中,比如无符号整数12345,它转换成二进制就是0011 0000 0011 1001太长了,为了方便显示就转换成16进制表示30 39,而int类型是4个字节,1个字节8个位。这个值实际只占了2个字节,剩余的字节用0来补全,那么实际上是00 00 30 39。在无符号整数123456在内存中是否就以00 00 30 39来存放呢?运行一下代码

查看结果
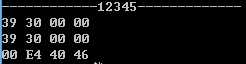
发现刚好跟猜想相反。对于00 00 30 39 这串数据而言,00是高位,39是低位,测试的结果发现数字存放在内存中被高低位互换了。不过也不能妄下定论说数据经过高低位互换才放到内存中,实际上这里还涉及到字节顺序中大端法和小端法的概念。如果一个数据,它存放在内存中的字节顺序是从数据的高位一直到低位的,比如上面12345,存放顺序是 00 00 30 39。那这种就称为大端法,我理解是"大位靠前端法";与之相反,数据存放内存中字节顺序从低位到高位存放的,比如上面12345,存放顺序是39 30 00 00,这种称之为小端法,"小位靠前法"。C语言是移植性很强的语言。C#依靠DotNet Core也可以实现跨平台,我倒是没有在别的平台上运行过上面的代码。C语言也没有,但据说与上面类似的代码在Sun,Linux32,Linux64上运行,仅有Sun是显示00 00 30 39。也就是说只有Sun是使用了大端法来存储数据,其他平台都使用小端法来存储数据。当我们在主机与主机与间进行数据交互时,就要注意双方平台所用的字节顺序。鄙人在使用串口通讯时就遇到过这个场景,发送或接收一串数据,其中某几个字节是有用的数据,把数据取出来之后还需要高低位互换,才是所需要的数据。这就是一个很好的例子了。
标签:ascii 概念 还需要 数据 语言 自己 整数 x64 数据类型
原文地址:http://www.cnblogs.com/HopeGi/p/6901880.html