标签:str spider src 电影 log png 内容 http 分享
本篇主要介绍通过scrapy 框架来豆瓣电影
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
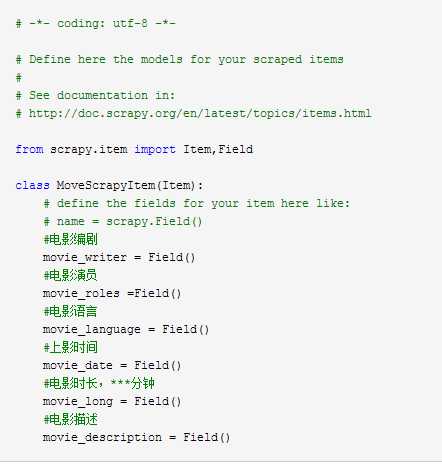
2、编辑在spiders目录下DoubanSpider文件

3、编辑pipelines.py文件,可以通过它将保存在MoveScrapyPipeline中的内容写入到数据库或者文件中
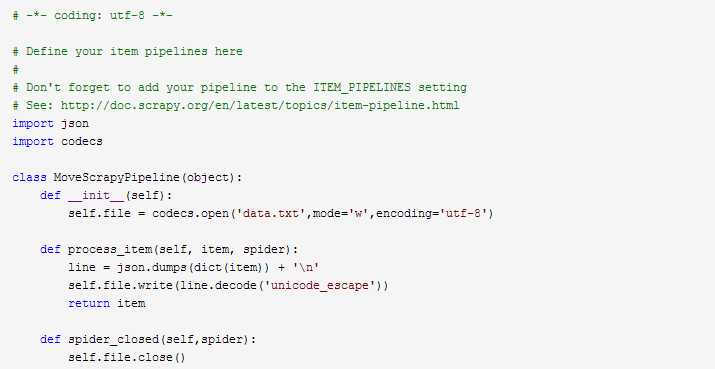
标签:str spider src 电影 log png 内容 http 分享
原文地址:http://www.cnblogs.com/shaosks/p/6903874.html