标签:核心 开源 步骤 scala 分布式 接受 依赖 style redis
Kafka介绍
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
KAFKA + STORM +REDIS
1、Apache Kafka是一个开源消息系统,用Scala写成。
2、Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
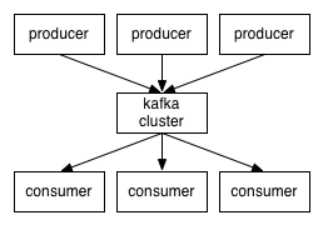
3、Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接收者成为Consumer,此外Kafka集群由多个Kafka实例组成,每个实例(server)称为broker。
4、无论是kafka集群,还是Producer和Consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
Kafka核心组件
Topic :消息根据Topic进行归类
Producer:发送消息者
Consumer:消息接受者
broker:每个kafka实例(server)
Zookeeper:依赖集群保存meta信息。
Kafka集群的搭建步骤
标签:核心 开源 步骤 scala 分布式 接受 依赖 style redis
原文地址:http://www.cnblogs.com/ahu-lichang/p/6906378.html