标签:des style blog http color os java 使用 io
1.Tachyon简介
Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样。通过利用信息继承,内存侵入,Tachyon获得了高性能。Tachyon工作集文件缓存在内存中,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件。因此,Tachyon可以减少那些需要经常使用的数据集通过访问磁盘来获得的次数。
2.Tachyon能解决什么问题:(摘自Tachyon 分布式内存文件系统)
1.不同FrameWork之间共享内存数据Slow问题
给定一个场景,MapReduce任务的输出结果会存入到Tachyon里,Spark的Job会从Tachyon里读取MapReduce任务的输出作为输入。如果把Disk当作文件的落地,那么写的性能是十分低下的。但是如果把Memory当作落地,写的性能是非常高的,fast write,以便Spark Job不会感觉到这是2个计算框架的操作,因为写和读的速度都非常快。同样的,你可以用Impala的输出结果当作Spark的输入。
2.Spark的Executor Crash问题
Spark的执行引擎和存储引擎都是在Executor进程里,即在一个Executor内会有多个Task在运行,并且这个Executor的内存会放入cache的RDD里。
问题来了,一旦我的Executor挂了,那么Tasks会失败,并且这些cache的RDD的Block也会丢失,这就会有ReCompute的过程,重新去取数据,根据血缘关系递归的去计算丢失的数据,这当然会很耗费资源,而且性能低下。
3.内存冗余问题
这里说的内存冗余是说,Spark中不同Job之间可能同时读取了同一个文件,比如:job1和job2的计算任务都需要读取到账号信息表中的数据,那么我们都在他们各自的Executor里都cache了这一张账号表,是不是就出现了一个数据,2个内存副本,其实这样做是完全没有必要的,是冗余的。
4.GC时间过长
有时候影响程序执行的并不是代码本身,而是由于内存中存了太多的Java Objects,如果Executor这个Jvm里cache的对象太多,比如:达到80G UP,这个时候出现几次FULL GC,你就会很纳闷我的程序怎么不动了?你去看GC log,原来在GC。
3.基于Zookeeper的Fault Tolerant Tachyon Cluster 实现
3.0 配置前提
集群情况:
| Cluster | Masters | Slaves |
| Tachyon | bigdata001,bigdata002 | bigdata001,bigdata002,bigdata003,bigdata004,bigdata005,bigdata006,bigdata007,bigdata008 |
zookeeper url: bigdata001:2181,bigdata002:2181,bigdata003:2181
3.1 HA架构
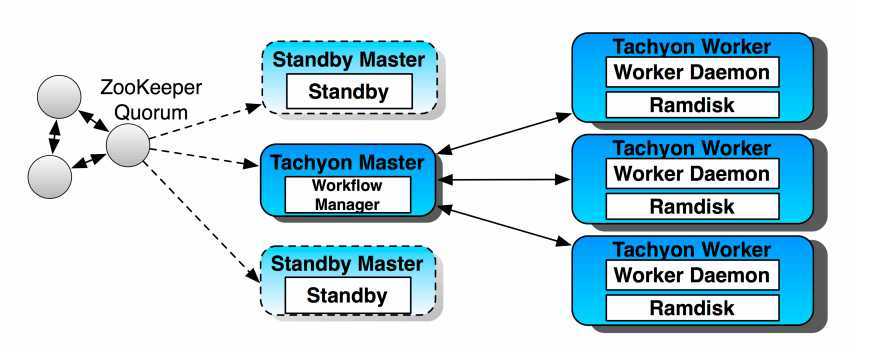
3.2 配置(conf/tachyon-env.sh )
1.参考官方文档:Fault Tolerant Tachyon Cluster
①HDFS
export TACHYON_UNDERFS_ADDRESS=hdfs://[namenodeserver]:[namenodeport]
②ZooKeeper:
| Property Name | Example | Meaning |
|---|---|---|
| tachyon.usezookeeper | true | Whether or not Master processes should use ZooKeeper. |
| tachyon.zookeeper.address | localhost:2181 | The hostname and port ZooKeeper is running on. |
③Master Node Configuration
export TACHYON_MASTER_ADDRESS=[externally visible address of this machine]
TACHYON_JAVA_OPTS to include:
-Dtachyon.master.journal.folder=hdfs://[namenodeserver]:[namenodeport]/tachyon/journal
④Worker Node Configuration
export TACHYON_MASTER_ADDRESS=[address of one of the master nodes in the system]
2.集群配置
Master节点配置:bigdata001节点的tachyon/conf/tachyon-env.sh添加如下(下划线部分)
export TACHYON_MASTER_ADDRESS=192.168.1.101
export TACHYON_UNDERFS_ADDRESS=hdfs://192.168.1.101:8020 export TACHYON_JAVA_OPTS+=" -Dlog4j.configuration=file:$CONF_DIR/log4j.properties -Dtachyon.debug=false -Dtachyon.underfs.address=$TACHYON_UNDERFS_ADDRESS -Dtachyon.underfs.hdfs.impl=$TACHYON_UNDERFS_HDFS_IMPL -Dtachyon.data.folder=$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/data -Dtachyon.workers.folder=$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/workers -Dtachyon.worker.memory.size=$TACHYON_WORKER_MEMORY_SIZE -Dtachyon.worker.data.folder=$TACHYON_RAM_FOLDER/tachyonworker/ -Dtachyon.master.worker.timeout.ms=60000 -Dtachyon.master.hostname=$TACHYON_MASTER_ADDRESS -Dtachyon.master.journal.folder=$TACHYON_UNDERFS_ADDRESS/tachyon/journal/ -Dtachyon.master.pinlist=/pinfiles;/pindata -Dorg.apache.jasper.compiler.disablejsr199=true -Dtachyon.user.default.block.size.byte=67108864 -Dtachyon.user.file.buffer.bytes=8388608 -Dtachyon.usezookeeper=true -Dtachyon.zookeeper.address=bigdata001:2181,bigdata002:2181,bigdata003:2181 "
配置同步到所有的slave节点:bigdata002,bigdata003,bigdata004,bigdata005,bigdata006,bigdata007,bigdata008
由于我们要将bigdata002作为另外一个master,因此,此节点的配置需要做修改TACHYON_MASTER_ADDRESS的值,如下
export TACHYON_MASTER_ADDRESS=192.168.1.102 export TACHYON_UNDERFS_ADDRESS=hdfs://192.168.1.101:8020 export TACHYON_JAVA_OPTS+=" -Dlog4j.configuration=file:$CONF_DIR/log4j.properties -Dtachyon.debug=false -Dtachyon.underfs.address=$TACHYON_UNDERFS_ADDRESS -Dtachyon.underfs.hdfs.impl=$TACHYON_UNDERFS_HDFS_IMPL -Dtachyon.data.folder=$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/data -Dtachyon.workers.folder=$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/workers -Dtachyon.worker.memory.size=$TACHYON_WORKER_MEMORY_SIZE -Dtachyon.worker.data.folder=$TACHYON_RAM_FOLDER/tachyonworker/ -Dtachyon.master.worker.timeout.ms=60000 -Dtachyon.master.hostname=$TACHYON_MASTER_ADDRESS -Dtachyon.master.journal.folder=$TACHYON_UNDERFS_ADDRESS/tachyon/journal/ -Dtachyon.master.pinlist=/pinfiles;/pindata -Dorg.apache.jasper.compiler.disablejsr199=true -Dtachyon.user.default.block.size.byte=67108864 -Dtachyon.user.file.buffer.bytes=8388608 -Dtachyon.usezookeeper=true -Dtachyon.zookeeper.address=bigdata001:2181,bigdata002:2181,bigdata003:2181 "
3.启动集群
[root@bigdata001 tachyon]# ./bin/tachyon-stop.sh
Killed processes
Killed processes
192.168.1.103: Killed processes
192.168.1.101: Killed 0 processes
192.168.1.102: Killed processes
192.168.1.104: Killed processes
192.168.1.106: Killed processes
192.168.1.105: Killed processes
192.168.1.107: Killed processes
192.168.1.108: Killed processes
[root@bigdata001 tachyon]# ./bin/tachyon format
192.168.1.101: Formatting Tachyon Worker @ bigdata001
192.168.1.102: Formatting Tachyon Worker @ bigdata002
192.168.1.103: Formatting Tachyon Worker @ bigdata003
192.168.1.104: Formatting Tachyon Worker @ bigdata004
192.168.1.105: Formatting Tachyon Worker @ bigdata005
192.168.1.106: Formatting Tachyon Worker @ bigdata006
192.168.1.107: Formatting Tachyon Worker @ bigdata007
192.168.1.102: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.101: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.103: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.104: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.108: Formatting Tachyon Worker @ bigdata008
192.168.1.105: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.106: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.107: Removing local data under folder: /mnt/ramdisk/tachyonworker/
192.168.1.108: Removing local data under folder: /mnt/ramdisk/tachyonworker/
Formatting Tachyon Master @ 192.168.1.101
Formatting JOURNAL_FOLDER: hdfs://192.168.1.101:8020/tachyon/journal/
Formatting UNDERFS_DATA_FOLDER: hdfs://192.168.1.101:8020/tmp/tachyon/data
Formatting UNDERFS_WORKERS_FOLDER: hdfs://192.168.1.101:8020/tmp/tachyon/workers
[root@bigdata001 tachyon]# ./bin/tachyon-start.sh all Mount
Killed 0 processes
Killed 0 processes
192.168.1.103: Killed 0 processes
192.168.1.101: Killed 0 processes
192.168.1.105: Killed 0 processes
192.168.1.102: Killed 0 processes
192.168.1.107: Killed 0 processes
192.168.1.106: Killed 0 processes
192.168.1.104: Killed 0 processes
192.168.1.108: Killed 0 processes
Starting master @ 192.168.1.101
192.168.1.101: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.102: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.101: Starting worker @ bigdata001
192.168.1.103: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.102: Starting worker @ bigdata002
192.168.1.103: Starting worker @ bigdata003
192.168.1.104: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.105: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.104: Starting worker @ bigdata004
192.168.1.105: Starting worker @ bigdata005
192.168.1.106: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.106: Starting worker @ bigdata006
192.168.1.107: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.107: Starting worker @ bigdata007
192.168.1.108: Formatting RamFS: /mnt/ramdisk (2gb)
192.168.1.108: Starting worker @ bigdata008
[root@bigdata001 tachyon]# jps
可以看到Master和Worker的进程号:8315 Master 8458 Worker
在另个master节点bigdata002上启动另外一个master:
[root@bigdata002 tachyon]# ./bin/tachyon-start.sh master
Starting master @ 192.168.1.102
4.测试HA
web界面查看:http://bigdata001:19999
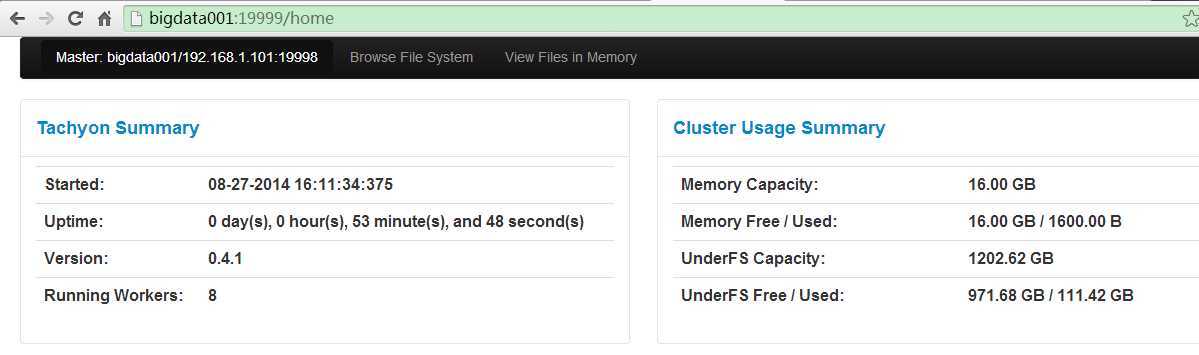
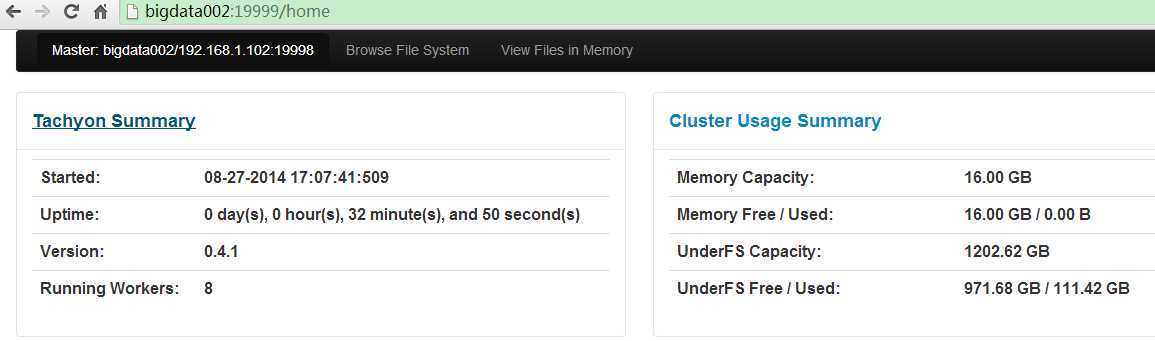
kill掉bigdata001的master进程,切换时间大概需要20s,再次查看新的Web UI:http://bigdata002:19999/home
5.Zk上查看
[root@bigdata002 conf]# zkCli.sh
[zk: localhost:2181(CONNECTED) 61] ls /election
[_c_ae6213f4-a2e3-46f9-8fc0-5c5c64d7e773-lock-0000000027, _c_12297d87-56fc-4cd9-8f8d-7312a6af4cc2-lock-0000000026]
[zk: localhost:2181(CONNECTED) 63] ls /leader
[bigdata001:19998, bigdata002:19998]
Tachyon Cluster: 基于Zookeeper的Master High Availability(HA)高可用配置实现
标签:des style blog http color os java 使用 io
原文地址:http://www.cnblogs.com/byrhuangqiang/p/3940017.html