标签:des style blog http color ar 数据 2014 log
第二章 感知机
感觉感知机这东西还是很简单的,随便写点。
感知机(perceptron)是二分类的线性分类器。
输入x表示实例的特征向量,输出y为实例的类别,由如下函数表示:
![]()
其中w为权值(weight)或权值向量(weight vector),b表示偏置(bias),sign为符号函数,里面的东西大于0就是1,否则是-1。
感知机属于判别模型(直接寻找输入到输出的映射函数,不关心联合概率什么的)。
感知机的解释:wx + b = 0 对应于特征空间中的一个超平面S(超平面这个东西在二维上表示为线,三维上表示为面,跟上面就不知道是个鬼了,那就叫超平面吧,超过平面的意思神马的)。w为法向量,b为截距(具体可以从欧式空间中的一条直线的情况去理解)。
线性可分与线性不可分:即对数据集,如果能够找到这么一个超平面wx + b = 0,使得正负实例点能够完全正确的划分到超平面的两侧,则称为线性可分,否则不可分。
感知机的学习目标就是要找到一个能够将正负实例点完全正确分类的分离超平面(这不就是说感知机只能用在线性可分的数据集上吗(T_T)),然后...就是找符合的w和b了。学习策略就是最小化损失函数了。
损失函数选什么呢,我们往往会首先想到:误分类的个数!感觉不错,但是个数这种东西,对w和b的调整似乎没有什么帮助,如何调整w,b才能使误分类个数下降呢,好像比较难吧,认真点说就是这样的损失函数不是w,b的连续可导函数。so,聪明的先人就想到了误分类点到超平面的总距离,这样就好算了,这个总距离被写成了这个东西:
![]()
为什么有个负号呢,因为对于误分类数据(x,y)来说,有-y(wx+b)>0(佛曰:懒得说)。然后,就有损失函数出现了(证明什么的去死去死):
![]()
然后就是最小化损失函数了(-_-ZZZ):
![]()
感知机学习算法是误分类驱动的(”驱动“这个词听起来很高端的样子),采样随机梯度下降法(stochastic gradient descent,这个以后会写的),分别对w和b求偏导:
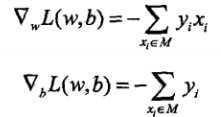
求完之后是更新(感觉这里也什么好说的,看一眼就过去了):
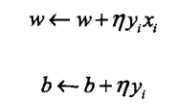
那个跟n长的很想的东西是学习速率(learning rate),大了参数跑的快点,但容易跑过头,小的慢点不会过头,但容易太慢。
然后是完整算法(懒得打了,直接盗图):

然后书后面就是各种例子啊,算法收敛性的证明啊,对偶形式什么的,懒的写了,懂这些也就差不多了。
额,大概就是这样了,这章还是比较简单的,先试试水。
标签:des style blog http color ar 数据 2014 log
原文地址:http://www.cnblogs.com/imczxj/p/3940175.html