标签:base 哪些 期望 重要 同义词 引入 平均值 图像特征 收集
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字。应用场景:比如说用户在拍了一张照片后,利用Image Caption技术可以为其匹配合适的文字,方便以后检索或省去用户手动配字;此外它还可以帮助视觉障碍者去理解图像内容。类似的任务还有Video Caption,输入是一段视频,输出是对视频的描述。
目前来说,Image Caption任务主要集中在英文上,数据集包括COCO(CodaLab组织了一个排行榜)、Flickr8k、Flickr30k和SBU等,其中除了SBU外,每个图片都有5个人工参考描述,并且SBU来自用户上传时所配,噪声较大。
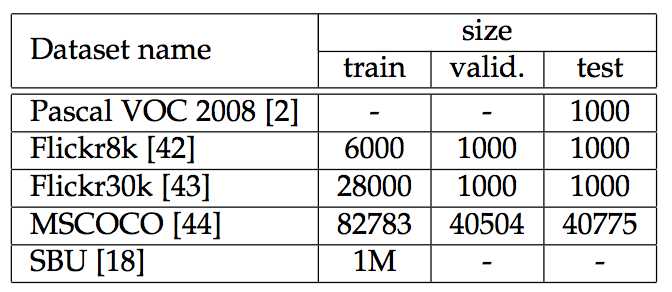
此外,今年ACL上出现了日文的数据集。
根据 [1] ,将理解图片和生成描述这两个子任务统一到一起的话,那么Image Caption任务的训练过程可以描述为这个形式:对于训练集的一张图片 $I$ ,其对应的描述为序列 $S=\{S_1,S_2,...\}$(其中 $S_i$ 代表句子中的词)。对于模型 $\theta$ ,给定输入图片$I$ ,模型生成序列 $S$ 的概率为
$$P(S|I)=\prod_{t=0}^NP(S_t|S_0,S_1,...,S_{t-1},I;\theta)$$
将似然函数取对数:
$$\log P(S|I)=\sum_{t=0}^N\log P(S_t|S_0,S_1,...,S_{t-1},I;\theta)$$
模型当然希望最大化以上概率(对数似然)。模型的训练目标就是最大化全部训练样本的对数似然之和:
$$\theta^*=\arg\max_{\theta}\sum_{(I,S)}\log P(S|I)$$
式中 $(I,S)$ 为训练样本。这种极大似然估计的方式等价于使用对数损失函数的经验风险最小化。
训练好模型后,对于生成过程,则是根据输入的一张图片 $I$ ,推断出最可能的序列来输出:
$$\arg\max_{S}P(S|I;\theta^*)$$
当然,计算全部序列的概率然后选出概率最大的序列当然是不可行的,因为每个位置都有词表规模的词作为候选,搜索规模会随序列的长度而指数级增长,所以需要用beam search来缩小搜索空间。
看到这,想到了什么?是不是机器翻译,自动摘要,encoder-decoder……
ok,下面说一下自动评价方法的评价指标。在2015 COCO的排行榜上,可以看到常用的指标是BELU、Meteor、ROUGE、CIDEr和SPICE。前两个是评测机器翻译的,第三个是评测自动摘要的,最后两个应该是为caption定制的。下面简单介绍一下前四个。
对于英文来说,模型生成的caption和人工给出的参考caption都经过了预处理:词条化(tokenization),去除标点。一般来说,评价生成的序列与参考序列的差异时,都是基于 n-gram 的,而且COCO官方提到 n-gram 中的词没有经过词干还原(stemming,启发式地去掉单词两端词缀)这个步骤。
1. BLEU(BiLingual Evaluation Understudy)
BLEU是事实上的机器翻译评测标准,n 常取1到4,基于准确率(precision)的评测。我们首先看一下它在机器翻译里是怎么做的。
需要明确,在机器翻译中,翻译的评测通常是以句子为单位的。
(1) 首先来看一个最简单的思路:对于一个源语言句子,计算模型生成的译文中的 n-gram 的个数,然后再计算这些 n-gram 中有多少是同时出现在了参考译文(不止一句)中,从而计算出一个百分比来作为 precision 。
但这样的做法存在一些问题:比如说参考句子1是“the cat is on the mat”,参考句子2是“there is a cat on the mat”,而模型生成的句子是“the the the the the the the”,那么按照上述定义,考察 n=1 的情况,也就是unigram,模型生成的句子包含7个 unigram ,这7个 unigram 全部出现在了参考句子集合中,所以将得到7/7这样的满分,但是这样的译文显然没有意义。为了获得较高的指标,模型完全可以在任何位置都去生成一个“百搭”的词,使得分子随着分母的增长而增长。
(2) 为了解决这个问题,需要修正 precision 的计算方式。考虑模型生成的句子 $c$ 的全部 n-gram ,考察其中的任一 n-gram :首先计算其在 $c$ 中出现的次数 $Count(n\text{-gram})$ ;然后统计其在所有参考句子中出现次数的最大值,将该值与 $Count(n\text{-gram})$ 的较小者记作该 n-gram 的匹配次数 $Count_{\text{clip}}(n\text{-gram})$ 。之后,再把每个 n-gram 的计算结果累加起来,得到句子的结果。所以precision可以用如下方式计算:
$$p_n=\frac{\displaystyle\sum_{c\in\{\text{Candidates}\}}\sum_{n\text{-gram}\in c}Count_{\text{clip}}(n\text{-gram})}{\displaystyle\sum_{c\in\{\text{Candidates}\}}\sum_{n\text{-gram}\in c}Count(n\text{-gram})}$$
式中 $\{\text{Candidates}\}$ 代表需要评测的多句译文的集合。当n取1时,$\displaystyle\sum_{n\text{-gram}\in c}Count(n\text{-gram})$ 就是句子 $c$ 的长度。
回过头来看上面那个例子,译文句子的unigram只有“the”,它在译文中出现了7次,而在参考句子中出现次数的最大值是2(在参考句子1中出现2次,参考句子2中出现1次),所以“the”的匹配次数为 min{2, 7}=2 ,因此precision为2/7。
(3) 但是这样的计算方式仍然存在问题:比如模型生成的句子是“the cat is on”,那么从n取1到n取4,得分都是1。换言之,由于评价的是precision,所以会倾向于短句子,如果模型只翻译最有把握的片段,那么就可以得到高分,因此要对短句子进行惩罚。
惩罚的方式就是在原先的评价指标值上乘一个惩罚因子(brevity penalty factor):当模型给出的译文句子 $c$ 的长度 $l_c$ 要比参考句子的长度 $l_s$ 长时,就不进行惩罚,即惩罚因子为1,比如说有三个参考句子的长度分别为12、15、17,模型给出的译文句子长度为12,那么就不进行惩罚;否则就惩罚:
$$BP=\begin{cases}1, & l_C>l_S;\\\exp(1-\dfrac{l_S}{l_C}), & l_C\leq l_S\end{cases}$$
式中的 $l_C$ 代表模型给出的测试集全部句子译文的长度总和,$l_S$ 代表与模型给出译文句子长度最接近的参考译文的长度(语料级别)。
综合起来,BLEU的评分公式采用的是对数加权平均值(这是因为当n增大时评分会指数级减小),再乘上惩罚因子:
$$BLEU@N=BP\cdot \exp(\sum_{n=1}^Nw_n\log p_n)$$
式中的 N 通常取4,权重 $w_n$ 通常取 $\dfrac1N$(几何平均)。最终评分在0到1之间,1表示完全与人工翻译一致。
BLEU的优点是它考虑的粒度是 n-gram 而不是词,考虑了更长的匹配信息;缺点是不管什么样的 n-gram 被匹配上了,都会被同等对待。比如说动词匹配上的重要性从直觉上讲应该是大于冠词的。
(4) 在caption任务中,处理方式和机器翻译是一样的:多张图片就相当于翻译里的多个源语言句子。为了描述清楚还是给一下公式:
对于测试集的一张图片 $I_i$ ,模型生成的caption记为 $c_i\in C$( $C$ 是全部 $c_i$ 构成的集合),且将任一 n-gram 记作 $\omega_k$ ;人工给出的参考caption的集合为 $S_i=\{s_{i1},s_{i2},...,s_{im}\}\in S$( $S$ 是全部 $S_i$ 构成的集合),$s_{ij}$ 为句子,$m$ 为参考caption的数量(数据集里的一张图片通常会有多个参考caption,比如Flickr、COCO数据集上每张图片都有5个参考caption)。将某个 n-gram $\omega_k$ 出现在句子 $c_i$ 中的次数记作 $h_k(c_i)$ ,类似地,可定义 $h_k(s_{ij})$ 。
在整个测试集上,precision值为
$$p_n(C,S)=\frac{\displaystyle\sum_i\sum_k\min\{h_k(c_i),\max_{j\leq m}h_k(s_{ij})\}}{\displaystyle\sum_i\sum_kh_k(c_i)}$$
惩罚因子的值为
$$BP(C,S)=\begin{cases}1, & l_C>l_S;\\\exp(1-\dfrac{l_S}{l_C}), & l_C\leq l_S\end{cases}$$
所以BLEU@N的值为
$$BLEU@N(C,S)=BP(C,S)\cdot \exp(\sum_{n=1}^Nw_n\log p_n(C,S))$$
2. ROUGE
ROUGE是出于召回率来计算,所以是自动摘要任务的评价标准。详情可见之前写过的一篇关于摘要的博客。
3. Meteor
Meteor也是来评测机器翻译的,对模型给出的译文与参考译文进行词对齐,计算词汇完全匹配、词干匹配和同义词匹配等各种情况的准确率、召回率和F值。
首先计算 unigram 情况下的准确率P和召回率R(计算方式与BLEU、ROUGE类似),得到调和均值F值
$$F=\frac{(\alpha^2+1)P}{R+\alpha P}$$
看到这可能还没有什么特别的。
Meteor的特别之处在于,它不希望生成很“碎”的译文:比如参考译文是“A B C D”,模型给出的译文是“B A D C”,虽然每个unigram都对应上了,但是会受到很严重的惩罚。惩罚因子的计算方式为
$$Penalty=\gamma (\frac{\#chunks}{\#unigrams\_matched})^{\theta}$$
式中的 $\#chunks$ 表示匹配上的语块个数,如果模型生成的译文很碎的话,语块个数会非常多;$\#unigrams\_matched$ 表示匹配上的unigram个数。所以最终的评分为
$$Meteor=(1-Penalty)\cdot F$$
用于机器翻译评测时,通常取 $\alpha=3$ ,$\gamma=0.5$ 和 $\theta=3$ 。
4. CIDEr(Consensus-based image description evaluation)
这个指标将每个句子都看作“文档”,将其表示成 tf-idf 向量的形式,然后计算参考caption与模型生成的caption的余弦相似度,作为打分。换句话讲,就是向量空间模型。考虑一张图片 $I_i\in I$( $I$ 是全部测试集图片的集合):
对于一个 n-gram $\omega_k$ 和参考caption $s_{ij}$ ,tf-idf 计算方式为
$$g_k(s_{ij})=\frac{h_k(s_{ij})}{\displaystyle\sum_{\omega_l\in\Omega} h_l(s_{ij})}\log\biggl(\frac{|I|}{\displaystyle\sum_{I_p\in I}\min\{1,\sum_qh_k(s_{pq})\}}\biggr)$$
式中的 $\Omega$ 是全部 n-gram 构成的词表。可以看出 idf 的分母部分代表的是 $\omega_k$ 出现于参考caption的图片个数。
那么,CIDEr的值可以用余弦相似度的平均值来计算:
$$CIDEr_n(c_i,S_i)=\frac1m\sum_j\frac{\boldsymbol{g^n}(c_i)^{\top}\boldsymbol{g^n}(s_{ij})}{||\boldsymbol{g^n}(c_i)||\cdot ||\boldsymbol{g^n}(s_{ij})||}$$
类似于BLEU的做法:
$$CIDEr(c_i,S_i)=\sum_{n=1}^Nw_nCIDEr_n(c_i,S_i)$$
泛读了几篇论文,这是第一篇,也是很简单的一篇:
[1] NICv2模型:Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
这篇文章的原型是2015年CVPR的那篇show and tell,NIC模型。这篇增加了一些内容,讲了相比于原先的模型都做了哪些改进,进而取得了2015年COCO比赛的第一名。
NIC模型的结构非常“简单”:就是利用encoder-decoder框架,首先利用CNN(这里是GoogLeNet)作为encoder,将softmax之前的那一层固定维数的向量作为图像特征;再使用LSTM作为decoder,其中图像特征作为decoder第一个时刻的隐层状态。模型的训练就是和任务描述那里介绍的一样,使用最大化对数似然来训练,然后在测试阶段采用beam search来减小搜索空间。
由此可看出,encoder-decoder这个框架非常灵活,不限制输入和输出的模态,也不限制使用何种神经网络;缺点就是encode过程中将输入信息保存为固定维度的向量带来了信息损失,但是这个缺点早已被attention机制所解决了(诸如RNN难以训练之类的不属于这个框架的缺点,是RNN自身的局限性),此外对于输入端是文本的情况,如何能够encode篇章级别的信息也是一个问题。
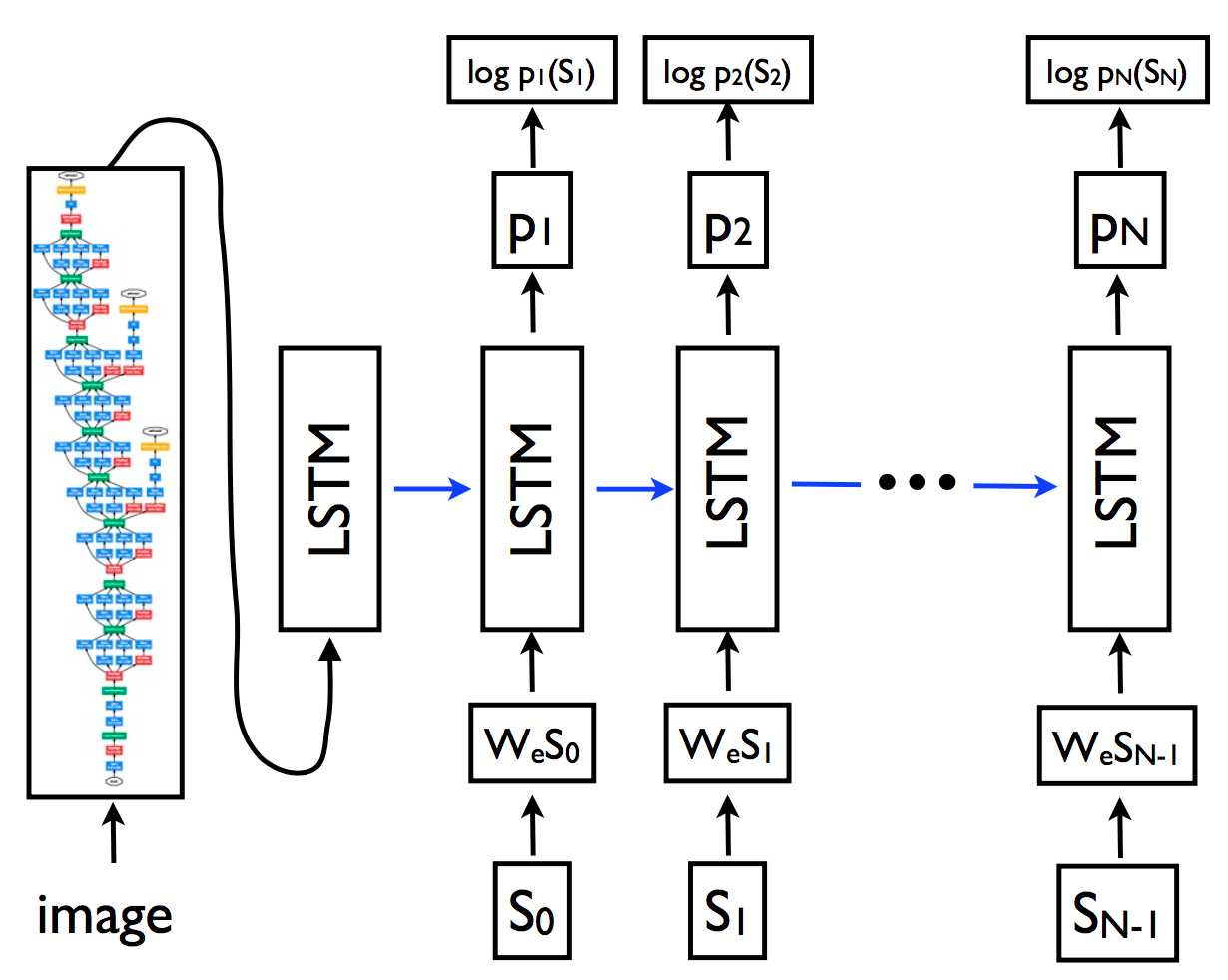
1. 训练细节
在训练过程中,固定学习率且不加动量(momentum);词条化后去掉了词频小于5的词;在ImageNet上预训练GoogLeNet,并且在训练caption模型时这部分的参数保持不变;在大型新闻语料上预训练词向量,但是效果并没有明显提升;使用dropout和模型ensemble,并权衡模型的容量:隐层单元个数与网络深度;512维词向量;使用困惑度(perplexity)来指导调参。
个人觉得,这种简单粗暴的模型结构,参数的设置真的太重要了。
2. 自动评价与人工评价
作者在论文中多次强调,需要更好的自动评价计算方式。
3. 迁移学习与数据标注的质量
一个很容易想到的问题是,是否可以把在某个数据集下训练的模型迁移到另一数据集?高质量的标注数据和更多的数据可以补偿多少领域错配问题?
首先来看迁移学习的问题,作者首先指出,在Flickr8k和Flick30k这两个数据集上,如果用Flickr30k来训练,效果会提升4个BLEU,更大量的数据带来了更好的效果,凸显data-driven的价值。但是如果用COCO做训练,尽管数据量五倍于Flickr30k,但由于收集过程不统一,带来了词表的差别以及较大的领域错配,效果下降了10个BLEU。PASCAL数据集没有提供训练集,使用COCO训练的效果要比使用Flickr30k的效果要好。
然后再看标注质量的问题。此前已经提到过,SBU数据集的噪声较大,所以可以看作是“弱标注”的(weak labeling),但尽管如此,如果使用COCO来训练,效果依旧会下降。
4. 生成的caption是否具备多样性
作者探讨了模型生成的描述是否有新颖性,是否同时具备多样性和高质量。

首先来看多样性(diversity)。作者挑了测试集里的三个图片的caption,每张图片都有模型生成的3-best描述(加粗的是没在训练集中出现过的),可以看出这些描述可以展现图像的不同方面,因此作者认为该模型生成的caption具备多样性。
再来看质量。如果只考虑模型生成的最佳候选caption,那么它们中的80%在训练集中出现过;如果考虑top15,则有一半是完全新的描述,但仍然具备相似的BLEU分,因此作者认为该模型生成的caption兼具了多样性和高质量。
5. NIC模型的改进:NICv2
作者列举了使他们成为2015COCO比赛第一名的几点重要改进。
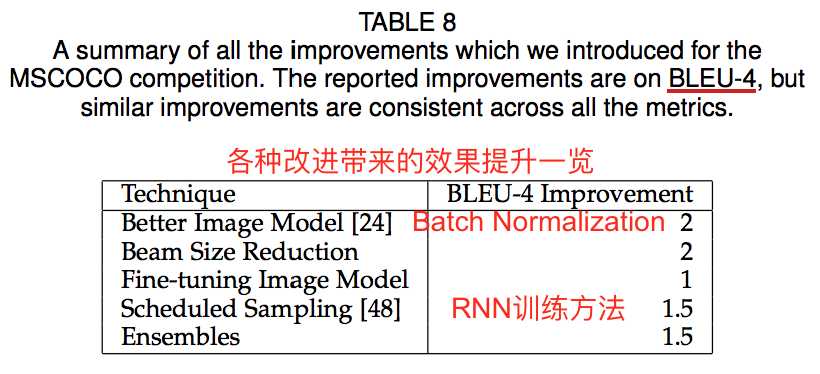
(1)在encoder的GoogLeNet中引入了Batch Normalization
(2)encoder端的fine-tuning
刚才提到,encoder端的CNN在预训练后,是不参与caption模型的训练的,其参数值是保持不变的。而这里他们进行了微调:首先固定encoder的参数,训练500k步decoder,以得到一个不错的LSTM;然后encoder和decoder联合训练100k步。作者特别强调,CNN不能陪着LSTM一起从头开始就联合训练,而必须在LSTM已经不错的情况下再进行联合训练,否则预训练的CNN也会被“带跑”。另外,作者说使用K20单机训练了超过三周,而并行训练时会使效果变差。
CNN的fine-tuning带来的效果是,一些例子可以正确描述颜色。作者认为,在ImageNet预训练的过程,使得“颜色”这样的和分类无关的特征被抛弃了。
(3)Scheduled Sampling:RNN的训练trick
RNN的训练和测试过程其实存在不统一的地方:训练时,每生成一个词时,所利用到的“前一个词”都是准确的;测试时,所有的词都是模型生成的,这就带来了训练和测试的不统一。Scheduled Sampling是指RNN训练时会随机使用模型真实输出来作为下一个时刻的输入,而不像原先那样只会使用期望输出(label)。
(4)模型ensemble:改变一些训练条件,训练出多个模型。作者训练了5个Scheduled Sampling模型和10个fine-tuning CNN模型。
(5)减小beam search的候选结果个数(k)
在NIC模型中,作者只取了1和20两个值。在改进过程中,发现k取3是最好的搜索规模。按道理说,k越大应该越好,但实际上是较小的k取得了最好的结果,说明目标函数与人工的标准不匹配,或者模型过拟合;作者同时发现,减少k可以提升新颖性(生成的caption出现在训练集的比例从80%降到了60%),所以认为模型是过拟合了。这样的话,减少k可以视作一种正则化。
6. 展望
作者提到,一个方向是希望模型能够给出有针对性的描述,例如根据用户提问来给出caption,这就成了一种VQA任务;另外一个就是需要更好的自动评价指标。
最后给出例子欣赏一下~~

参考:
[1] Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge(前一个版本在2015CVPR)
[2] Deep Visual-Semantic Alignments for Generating Image Descriptions
[4] 统计自然语言处理
[5] 由RNN的Discrepancy现象联想到深度学习与GAN
DL4NLP —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
标签:base 哪些 期望 重要 同义词 引入 平均值 图像特征 收集
原文地址:http://www.cnblogs.com/Determined22/p/6910277.html