标签:purge 状态 efault 操作 切换 tor more tar rest api
Hadoop 2.6.3
HBase 1.0.3
JDK 1.8
Zookeeper 3.4.9
RDFMaster 192.168.0.41 (Hadoop主节点,zk节点,HBase主节点)
RDFSlave01 192.168.0.42 (Hadoop备份主节点,从节点,zk节点,HBase的RegionServer)
RDFSlave02 192.168.0.43 (从节点,zk节点,HBase的RegionServer)
RDFSlave03 192.168.0.44 (从节点,zk节点,HBase的RegionServer)
RDFSlave04 192.168.0.45 (从节点,zk节点,HBase的RegionServer)
注解:由于环境资源有限,正常情况下Hadoop备份主节点应该是一台单独的机器比较好
参考以前的一篇文章即可,没有多大的改变
http://www.cnblogs.com/ocean7code/p/5734289.html
修改配置文件zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/develop/yun/workspace/zk/data dataLogDir=/home/develop/yun/workspace/zk/datalog # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=RDFMaster:2888:3888 server.2=RDFSlave01:2888:3888 server.3=RDFSlave02:2888:3888 server.4=RDFSlave03:2888:3888 server.4=RDFSlave04:2888:3888
配置文件中设置了两个路径,分别是dataDir和dataLogDir
在每个节点上,都要创建对应的文件夹,并且在文件夹中创建myid文件,文件内容上写本机在节点上的编号,例如:RDFMaster的myid内容就是1
启动Zookeeper:在每个节点上都执行如下操作:
sh zkServer.sh start
使用jps指令可以查看线程是否启动,或者使用 sh zkServer.sh status 查看当前节点的状态
1.修改 core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/develop/yun/workspace/hadoop/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>RDFMaster:2181,RDFSlave01:2181,RDFSlave02:2181,RDFSlave03:2181,RDFSlave04:2181</value> </property> </configuration>
解释:ns表示的是一个主节点的集合名称,在hdfs-site.xml中的配置会详细介绍这个集群的内容
修改 hadoop-env.sh
#这个是你的JDK路径,别设置错了,整个文件只需要改这个地方
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_101
解释:这个只需要修改JDK路径就可以了
2.修改 hdfs-site.xml
<configuration> <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!-- ns下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>RDFMaster:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>RDFMaster:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>RDFSlave01:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>RDFSlave01:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://RDFMaster:8485;RDFSlave01:8485;RDFSlave02:8485;RDFSlave03:8485;RDFSlave04:8485/ns</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/develop/yun/hadoop-2.6.4/journal</value> </property> <!-- 开启NameNode故障时自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled.ns</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/develop/yun/workspace/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/develop/yun/workspace/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
解释:这里配置了 dfs.ha.fencing.ssh.private-key-files 用于切换的时候使用ssh
3.修改 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <!--这个保持原样不要动,写提示是怕你乱动--> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>4096</value> <!--这个保持原样不要动,写提示是怕你乱动--> </property> </configuration>
4.修改 slaves
RDFSlave01
RDFSlave02
RDFSlave03
RDFSlave04
5.修改 yarn-env.sh
#这个是你的JDK路径,别设置错了,整个文件只需要改这个地方
export JAVA_HOME=export JAVA_HOME=/usr/local/jdk/jdk1.8.0_101
6.修改 yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <!--别动--> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>RDFSlave02</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> <!--别动--> </property> </configuration>
解释:这里配置的ResourceManager是RDFSlave02,所以启动集群的时候用的 start-yarn.sh 应该在RDFSlave02中
到这里配置文件就写完了,然后进行下一步操作
7.首先启动zookeeper,命令上面已经说了
8.启动journalnode(在hdfs-site.xml中配置了所有的节点都有journalnode,所以如下命令要在左右节点中执行)
sbin/hadoop-daemon.sh start journalnode
解释:使用jps命令就可以看到JournalNode线程了
9.格式化主节点(只需要在RDFMaster上执行)
hdfs namenode -format
10.格式化ZKFC(只需要在RDFMaster上执行)
hdfs zkfc -formatZK
11.进行NameNode信息的同步(这个要在RDFSlave01上执行,也就是做备份的主节点中)
hdfs namenode -bootstrapstandby #验证 tmp下生成dfs #如果执行失败(这个是因为备份主节点不能访问所有从节点导致的,我没有遇到过,这个是从别的博客看到的,放到这里,以备不时之需) ssh-keygen -f "~/.ssh/known_hosts" -R RDFSLave01 #验证 tmp下生成dfs
12.启动整个集群
#在RDFMaster上启动 start-dfs.sh #在RDFSlave02上启动 start-yarn.sh
13.启动ZookeeperFailoverController(在RDFMaster和RDFSlave01上都运行一下)
hadoop-daemon.sh start zkfc
#验证
jps
#显示DFSZKFailoverController
解释:在进行到12的时候,你会发现RDFMaster和RDFSlave01都是standby状态的,执行13命令后,就会有一个变成active状态了,我在搭建环境的时候,百度到过这个问题,在这里特别说明一下
14.到这里基本就结束了,展示一下最后的成果:
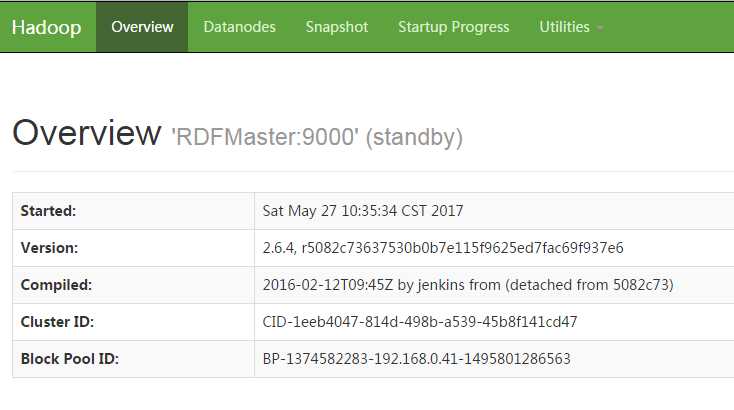
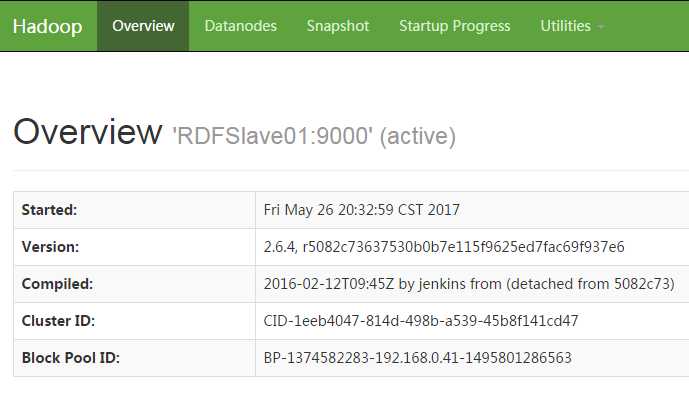
这个问题困扰很久了,HBase的备份主节点机制比较简单,很容易就弄懂了,这是第一次搭建Hadoop HA的机制,当把主节点NameNode关闭,备份主节点的NameNode状态变成active的时候,内心是很激动的,自己一个人搭建了一天,也算是有些收获了,下一篇文章会写到HBase的配置,也打算使用一下Phoneix,也会把这个内容附加上去,对于Hadoop的JournalNode和利用zookeeper实现的这种方式本人也不是很懂,只是知道利用共享的journalnode来同步信息,监控集群情况,后续了解了之后再发或者转载一下,作为笔记。
Hadoop HA + HBase环境搭建(一)————zookeeper和hadoop环境搭建
标签:purge 状态 efault 操作 切换 tor more tar rest api
原文地址:http://www.cnblogs.com/ocean7code/p/6915252.html