标签:finish .exe 基础 爬虫 arch 输入 覆盖 目录结构 sqlt
我们都知道大名鼎鼎的爬虫框架scrapy,它是基于twisted框架基础上进行的封装,它是基于异步调用,所以爬取的速度会很快,下面简单介绍一下scrapy的组成.
首先我们先安装scrapy,如果是基于python3.x 安装scrapy会出错因为依赖的twisted不兼容现有的python版本导致的,我们使用wheel单独安装twisted,然后输入 pip3 install scrapy,安装成功
如果在windows环境下调试,记得安装pywin32(pip3 install pypiwin32)
安装完成之后我们要开始新建project, 在当前的终端中切换目录到project的路径(例如:将和爬虫有关的project都放在e:\python\spider中)在终端中输入
startproject ArticleSpider创建爬虫工程,创建完工程之后,创建模板,输入
scrapy genspider jobbole blog.jobbole.com前一个是域名后一个是要爬取的url
我们的project准备工作就完毕了
项目的目录结构如下
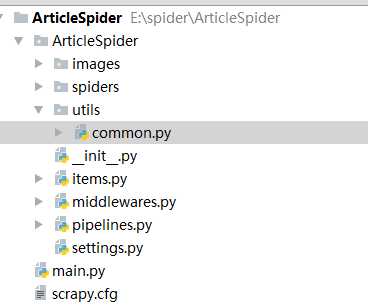
scrapy.cfg是总的控制文件,一般不用改动
settings.py是project的配置文件
piplines.py是存放数据的有关操作
middleware.py存放的中间件
items.py 定义数据类型
spiders文件件 存放爬虫的文件
 这个文件会在生成模板的时候自动创建,主要是用来解析网页中的字段和url
这个文件会在生成模板的时候自动创建,主要是用来解析网页中的字段和url
下面我们正式开始将http://blog.jobbole.com/all-posts/下的所有文章按照标题,日期,url,....等字段进行解析,然后将解析后的数据保存在远程的mysql数据库中
首先配置域名和要爬取的url

然后是定义爬取规则和解析的字段
这里我们使用css的方式来解析字段,同理还可以使用xpath来进行解析(jobble.py)
from urllib import parse
from scrapy.http import Request
def parse(self, response):
#获取文章的父级链接(在类中)
post_nodes = response.css(‘#archive .floated-thumb .post-thumb a‘)
for post_node in post_nodes:
#获取图片的路径
image_url = post_node.css(‘img::attr(src)‘).extract_first("")
post_url = post_node.css(‘a::attr(href)‘).extract_first("")
yield Request(url = parse.urljoin(response.url,post_url),meta={‘front_image_url‘:image_url},callback=self.parse_detail)
#获取下一页的链接,让爬虫可以自动爬去下一页的文章数据
next_url = response.css(‘.next.page-numbers::attr(href)‘).extract_first("")
if next_url:
yield Request(url=parse.urljoin(response.url,next_url),callback=self.parse)
在items.py中定义要爬取的数据,类型,格式,字段默认值
import scrapy
import datetime
import re
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose,TakeFirst,Join
class ArticleItemLoader(ItemLoader):
#改变默认的获取方式,将返回数据有列表改为字符串
default_output_processor = TakeFirst()
def date_convert(value):
#create_date转成date类型(该函数和类平级)
try:
create_date = datetime.datetime.strptime(value,‘%Y/%m/%d‘).date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date
def get_nums(value):
#过滤点赞数(和类平级)
match_re = re.match(‘.*?(\d+).*‘, value)
if match_re:
nums = int(match_re.group(1))
else:
nums = 0
return nums
def remove_tag_comment(value):
#去除tag里面的评论(和类平级)
if ‘评论‘ in value:
return ‘‘
else:
return value
def return_value(value):
#把图片的url变成覆盖默认的string类型,因为在scrapy底层,图片的url是列表,否则会报错(和类平级)
return value
class JobBoleArticleItem(scrapy.Item):
#标题,日期,url,url_obj_id,图片url,图片路径,点赞数,收藏数,评论数,标签,正文
title = scrapy.Field()
create_date = scrapy.Field(
#定义日期的格式
input_processor = MapCompose(date_convert)
)
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field(
output_processor=MapCompose(return_value)
)
front_image_path = scrapy.Field()
praise_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
comment_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
fav_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
tags = scrapy.Field(
input_processor=MapCompose(remove_tag_comment),
#定义输出数据的格式
output_processor = Join(‘,‘)
)
content = scrapy.Field()
#封装sql语句,将获取到的值插入到数据库中(在类中)
def get_insert_sql(self):
insert_sql = ‘‘‘
insert into jobbole_article(title, url,url_object_id, create_date, fav_nums, front_image_url, front_image_path,
praise_nums, comment_nums, tags, content)
VALUES (%s, %s, %s,%s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(fav_nums)
‘‘‘
fron_image_url = ""
#图片可能有很多,在插入的时候必须把列表转为字符串,只获取第一个图片链接
if self[‘front_image_url‘]:
fron_image_url = self[‘front_image_url‘][0]
params = (
self["title"], self["url"], self["url_object_id"], self["create_date"], self["fav_nums"],
fron_image_url, self["front_image_path"], self["praise_nums"], self["comment_nums"],
self["tags"], self["content"]
)
return insert_sql,params
在jobbole.py中继续定义带解析的字段
def parse_detail(self,response):
#使用css方式单独从网页获取每个每个元素的值(不建议使用,使得代码变得很多,可维护性差)
# title = response.css(‘.entry-header h1::text‘).extract()[0]
# create_date = response.css(‘p.entry-meta-hide-on-mobile::text‘).extract()[0].strip().replace(‘·‘,‘‘).strip()
# praise_nums = response.css(‘.vote-post-up h10::text‘).extract()[0]
# fav_nums = response.css(‘bookmark-btn::text‘).extract()[0]
# match_re = re.match(‘.*?(\d+).*‘,fav_nums)
# if match_re:
# fav_nums = int(match_re.group(1))
# else:
# fav_nums = 0
# comment_nums = response.css(‘a[href="#article-comment"] span::text‘).extract()[0]
# match_re = re.match(‘.*?(\d+).*‘, comment_nums)
# if match_re:
# comment_nums = int(match_re.group(1))
# else:
# comment_nums = 0
#
# content = response.css(‘div.entry‘).extract()[0]
# tag_list = response.css(‘p.entry-meta-hide-on-mobile a::text‘).extract()
# tag_list = [element for element in tag_list if not element.strip().endswith(‘评论‘)]
# tags = ‘,‘.join(tag_list)
#
#
# article_item[‘url_object_id‘] = get_md5(response.url)
# article_item[‘title‘] = title
# article_item[‘url‘] = response.url
# try:
# create_date = datetime.datetime.strptime(create_date,‘%Y/%m/%d‘).date()
# except Exception as e:
# create_date = datetime.datetime.now()
#
# article_item[‘create_date‘] = create_date
# article_item[‘front_image_url‘] = [front_image_url]
# article_item[‘praise_nums‘] = praise_nums
# article_item[‘comment_nums‘] = comment_nums
# article_item[‘fav_nums‘] = fav_nums
# article_item[‘tags‘] = tags
# article_item[‘content‘] = content
# yield article_item
#获取各个字段的值,
article_item = JobBoleArticleItem()
front_image_url = response.meta.get("front_image_url", "")
#通过items.py获取字段的loader
item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
#某些字段通过页面css获取,有些通过response获取
item_loader.add_css("title", ".entry-header h1::text")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url", [front_image_url])
item_loader.add_css("praise_nums", ".vote-post-up h10::text")
item_loader.add_css("comment_nums", "a[href=‘#article-comment‘] span::text")
item_loader.add_css("fav_nums", ".bookmark-btn::text")
item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text")
item_loader.add_css("content", "div.entry")
item_loader.add_value(‘front_image_path‘,‘‘)
#将字段封装到item中
article_item = item_loader.load_item()
#使得该方法变成可迭代对象,只要有数据便可不停的调用
yield article_item
pipeline.py中定义数据存储的格式(这里使用mysqldb进行数据插入,同理可测试sqlachemy)
mport codecs,json
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exporters import JsonItemExporter
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class ArticleImagePipeline(ImagesPipeline):
#获取图片url的路径,保存到item中
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item
class JsonExportPipeline(object):
#将文件导出成json格式
def __init__(self):
self.file = open(‘articleexport.json‘,‘wb‘)
self.exporter = JsonItemExporter(self.file,encoding=‘utf8‘,ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
class MysqlTwistedPipeline(object):
#异步插入数据,如果是异步的方式,插入数据就无需等待数据是否commit,这样就不会导致数据已经爬取完毕但是数据没有插入到数据库造成的阻塞问题,不需要手动提交数据
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,settings):
dbparams = dict(
host = settings[‘MYSQL_HOST‘],
db = settings[‘MYSQL_DBNAME‘],
user = settings[‘MYSQL_USER‘],
passwd = settings[‘MYSQL_PASSWORD‘],
charset=‘utf8‘,
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool(‘MySQLdb‘,**dbparams)
return cls(dbpool)
def process_item(self,item,spider):
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider)
def do_insert(self,cursor,item):
insert_sql,params = item.get_insert_sql()
print(insert_sql,params)
cursor.execute(insert_sql,params)
def handle_error(self,failure,item,spider):
print(failure)
class MysqlPipeline(object):
#采用同步的机制写入mysql,有可能造成数据阻塞
def __init__(self):
self.conn = MySQLdb.connect(‘192.168.0.106‘, ‘root‘, ‘root‘, ‘article_spider‘, charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
self.conn.commit()
在settings.py中配置pipiline,数据库连接信息
# Obey robots.txt rules
#可以爬取非结构的url
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
#数字越小,优先级越高
#‘ArticleSpider.pipelines.JsonExportPipeline‘: 2,
#‘scrapy.pipelines.images.ImagesPipeline‘: 1,
#‘ArticleSpider.pipelines.ArticleImagePipeline‘:1,
‘ArticleSpider.pipelines.ArticleImagePipeline‘: 1,
‘ArticleSpider.pipelines.MysqlTwistedPipeline‘: 2,
}
#定义图片url的路径,在project下创建images文件夹
IMAGES_URLS_FIELD = ‘front_image_url‘
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,‘images‘)
#虚拟机数据库信息(数据库的字符集一定要是utf8否则content保存会出错)
MYSQL_HOST = ‘192.168.17.54‘
MYSQL_DBNAME = ‘article‘
MYSQL_USER = ‘root‘
MYSQL_PASSWORD = ‘oldboy‘
测试在project下新建main.py文件
import os
import sys
from scrapy.cmdline import execute
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
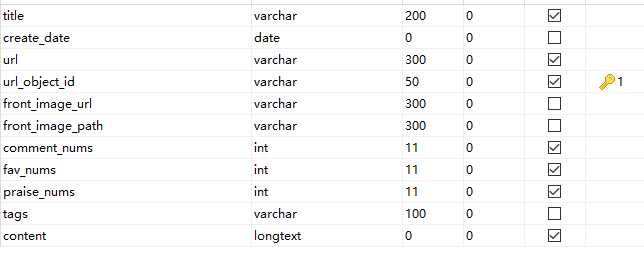
数据库表结构设计
测试成功之后
select title,tags from jobbole_article;
看是否有数据
标签:finish .exe 基础 爬虫 arch 输入 覆盖 目录结构 sqlt
原文地址:http://www.cnblogs.com/luhuajun/p/6917819.html