标签:服务 pack jobs 运行 scrapy 名称 程序 sts dev
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行
scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
安装扩展
pip install scrapyd
pip install scrapyd-client
首先修改项目的 scrapy.cfg 文件
原始内容为
[deploy]
#url = http://localhost:6800/
project = funsion
修改为
[deploy:funsion]
url = http://localhost:6800/
project = funsion
执行 nohup scrapyd > /dev/null 2>&1 &
检查配置, 列出当前可用的服务器 scrapyd-deploy -l
列出服务器上所有的项目, 需要确保服务器上的scrapyd命令正在执行,否则会报连接失败.首次运行的话,可以看到只有一个default项目
scrapyd-deploy -L funsion
在爬虫项目根目录下执行下面的命令, 其中target为上一步配置的服务器名称,project为项目名称,可以根据实际情况自己指定。
用法 scrapyd-deploy <target> -p <project>
在项目根目录下输入 scrapyd-deploy funsion -p funsion
得到以下结果
Packing version 1496109534
Deploying to project "funsion" in http://localhost:6800/addversion.json
Server response (200):
{"status": "ok", "project": "funsion", "version": "1496109534", "spiders": 1, "node_name": "localhost.localdomain"}
部署操作会打包你的当前项目,如果当前项目下有setup.py文件,就会使用它,没有的会就会自动创建一个。
如果后期项目需要打包的话,可以根据自己的需要修改里面的信息,也可以暂时不管它。
从返回的结果里面,我们可以看到部署的状态,项目名称,版本号和爬虫个数,以及当前的主机名称
检查部署结果 scrapyd-deploy -L funsion
调度爬虫,在项目根目录下
curl http://localhost:6800/schedule.json -d project=funsion -d spider=funsion
如果配置了多个服务器的话,可以将项目直接部署到多台服务器
scrapyd-deploy -a -p <project>
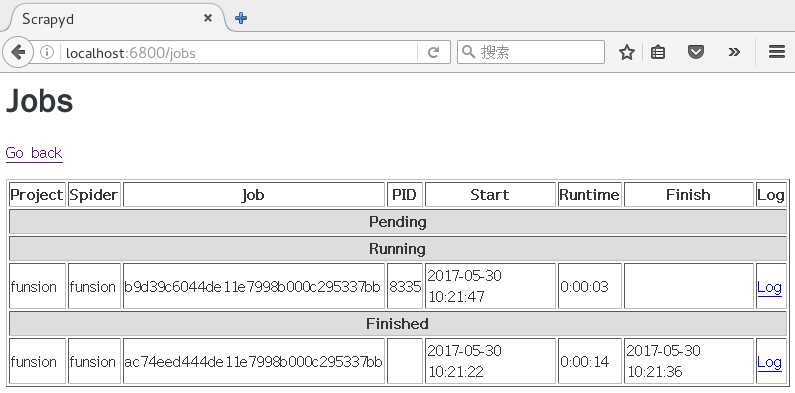
然后访问 http://localhost:6800/jobs 可以查询图像化界面,成功后应该和下图类似
更多参考
Scrapyd 项目爬虫部署
标签:服务 pack jobs 运行 scrapy 名称 程序 sts dev
原文地址:http://www.cnblogs.com/funsion/p/6919856.html