标签:hdf span history etc targe 伪分布 adf com direct
| 本文介绍的主要是Hadoop的伪分布式的搭建以及遇到的相关问题的解决,做一下记录,jdk的安装这里就不做太多的介绍了,相信大家根据网上的安装介绍很快就能安装成功。 |
| 操作系统 | Oracle VM VirtualBox-rhel-6.4_64 | |
| 本机名称 | yanduanduan | |
| 本机IP | 192.168.1.102 | |
| JDK | 1.7.0_79 | |
| hadoop | 2.7.3 | 点此下载 |
| Hadoop 有两个主要版本,Hadoop 1.x.y 和 Hadoop 2.x.y 系列,比较老的教材上用的可能是 0.20 这样的版本。Hadoop 2.x 版本在不断更新,本教程均可适用。如果需安装 0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。如果用的jdk为1.8.x,本教程同样适用。 |
解压到/usr/local/目录下
vi /etc/profile
maven、jdk、Hadoop所有添加的相关配置如下:
1 #set java enviroment 2 export JAVA_HOME=/usr/local/jdk7 3 export HADOOP_HOME=/usr/local/hadoop 4 export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH 5 export classpath=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar 6 HADOOP_OPT="-Dfile encoding=UTF-8" 7 8 MAVEN_HOME=/usr/local/maven3 9 export MAVEN_HOME 10 export PATH=${PATH}:${MAVEN_HOME}/bin 11 12 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native 13 14 export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
如果只是针对Hadoop则只加入如下配置
1 export HADOOP_HOME=/usr/local/hadoop 2 export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH 3 4 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native 5 export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
命令行输入命令
1 hadoop version
成功则显示
1 Hadoop 2.7.3 2 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff 3 Compiled by root on 2016-08-18T01:41Z 4 Compiled with protoc 2.5.0 5 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 6 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar
| 大家要是在这一步没有成功,可以考虑换个目录安装Hadoop,可以和我一样在/usr/local目录下安装,或者是在根目录下其他可以访问的目录下安装。看好你啊。 |
至此,Hadoop安装完成。
| Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。 |
Hadoop 的配置文件位于 /$HADOOP_HOME/etc/hadoop/ 中,伪分布式至少需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
1 vi /etc/hosts
添加到最后一行
1 192.168.1.102 yanduanduan
1 <configuration> 2 3 <property> 4 <name>hadoop.tmp.dir</name> 5 <value>file:/usr/local/hadoop/tmp</value> 6 <description>Abase for other temporary directories.</description> 7 </property> 8 9 <property> 10 <name>fs.defaultFS</name> 11 <value>hdfs://yanduanduan:9000</value> 12 </property> 13 14 </configuration>
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 7 <property> 8 <name>dfs.namenode.name.dir</name> 9 <value>file:/data/dfs/name</value> 10 </property> 11 12 <property> 13 <name>dfs.datanode.data.dir</name> 14 <value>file:/data/dfs/data</value> 15 </property> 16 </configuration>
伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
修改mapred-site.xml
文件默认不存在,只有一个模板,复制一份
1 cp mapred-site.xml.template mapred-site.xml
configration下添加
1 <property> 2 <name>mapreduce.framework.name</name> 3 <value>yarn</value> 4 </property> 5 <property> 6 <name>mapreduce.jobhistory.address</name> 7 <value>master:10020</value> 8 </property> 9 <property> 10 <name>mapreduce.jobhistory.webapp.address</name> 11 <value>master:19888</value> 12 </property>
1 <configuration> 2 3 <!-- Site specific YARN configuration properties --> 4 <property> 5 <name>yarn.nodemanager.aux-services</name> 6 <value>mapreduce_shuffle</value> 7 </property> 8 <property> 9 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> 10 <value>org.apache.hadoop.mapred.ShuffleHandler</value> 11 </property> 12 <property> 13 <name>yarn.resourcemanager.address</name> 14 <value>yanduanduan:8032</value> 15 </property> 16 <property> 17 <name>yarn.resourcemanager.scheduler.address</name> 18 <value>yanduanduan:8030</value> 19 </property> 20 <property> 21 <name>yarn.resourcemanager.resource-tracker.address</name> 22 <value>yanduanduan:8035</value> 23 </property> 24 <property> 25 <name>yarn.resourcemanager.admin.address</name> 26 <value>yanduanduan:8033</value> 27 </property> 28 <property> 29 <name>yarn.resourcemanager.webapp.address</name> 30 <value>yanduanduan:8088</value> 31 </property> 32 </configuration>
将原有的注释掉,改为绝对路径
1 #export JAVA_HOME=${JAVA_HOME} 2 export JAVA_HOME="/usr/local/jdk7"
1 [hadoop@yanduanduan hadoop]$ hdfs namenode –format
进入该目录
1 /usr/local/hadoop/sbin
输入命令
1 ./start-all.sh
输入jps命令
1 10514 Jps 2 8706 SecondaryNameNode 3 8528 DataNode 4 8382 NameNode 5 9158 NodeManager 6 8866 ResourceManager
如果少了哪一个就要看日志了。
用命令查看日志
1 cat /usr/local/hadoop/logs/hadoop-root-namenode-yanduanduan.log
显示如下
1 2017-05-30 16:32:22,517 INFO org.mortbay.log: Stopped HttpServer2$SelectChannelConnectorWithSafeStartup@0.0.0.0:50070 2 2017-05-30 16:32:22,517 WARN org.apache.hadoop.http.HttpServer2: HttpServer Acceptor: isRunning is false. Rechecking. 3 2017-05-30 16:32:22,517 WARN org.apache.hadoop.http.HttpServer2: HttpServer Acceptor: isRunning is false 4 2017-05-30 16:32:22,518 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping NameNode metrics system... 5 2017-05-30 16:32:22,519 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NameNode metrics system stopped. 6 2017-05-30 16:32:22,519 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NameNode metrics system shutdown complete. 7 2017-05-30 16:32:22,519 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode. 8 java.io.IOException: NameNode is not formatted. 9 at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:225) 10 at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:975) 11 at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:681) 12 at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:585) 13 at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:645) 14 at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:812) 15 at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:796) 16 at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1493) 17 at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1559) 18 2017-05-30 16:32:22,522 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1 注:1代表失败,0代表成功。 19 2017-05-30 16:32:22,524 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG: 20 /************************************************************ 21 SHUTDOWN_MSG: Shutting down NameNode at yanduanduan/192.168.1.102 22 ************************************************************/
解决办法
删除core-site.xml配置文件中配置的tmp目录下的所有文件;
将hadoop所有服务停止;
再次启动hadoop。
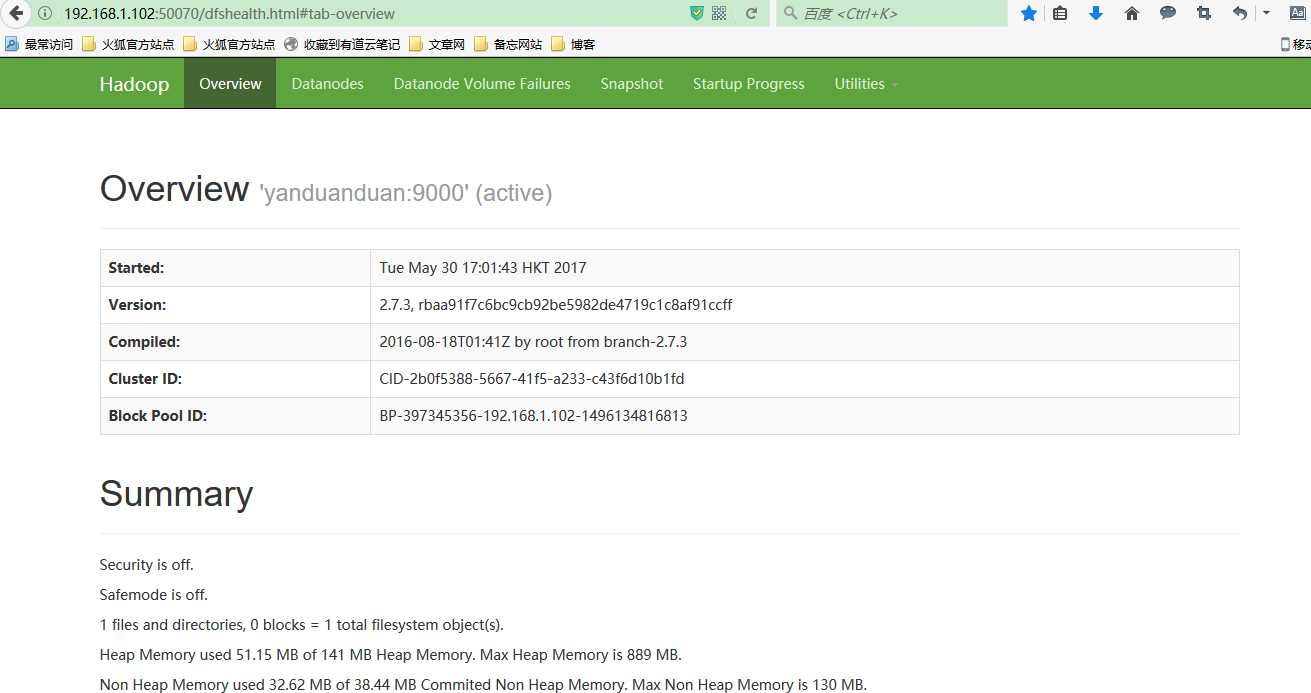
发现无法访问,本地可以访问.
锦囊妙计:
本机直接访问50070是可以访问到,但是别的机子ip:端口无法访问到,
原因是装了Hadoop的机子的防火墙是打开的,将防火墙关闭即可访问。
关闭防火墙方法:
查看防护墙状态
service iptables status
关闭
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭开机启动
chkconfig iptables off
再次访问就可以了
标签:hdf span history etc targe 伪分布 adf com direct
原文地址:http://www.cnblogs.com/yanduanduan/p/6921051.html