标签:factor 机制 ppa getx ima 标准化 树结构 格式 soft
要处理XML文档,就要先解析(parse)他,解析器时这样一个程序,读入一个文件,确认整个文件具有正确的格式,然后将其分解成各种元素,使得程序员能够访问这些元素,Java库提供了两种XML解析器:
DOM解析器对于实现我们的大多数目的来说都更容易一些,如果需要处理很长的文档,用他来生成树结构会消耗大量的内存,或者只需要对于某些元素感兴趣,而不关心他们的上下文,那么可以考虑使用SAX解析器。DOM解析器的接口已经被W3C标准化了,org.w3c.dom包中包含了这些接口类型的定义,比如:Document、Element等,不同的实现者都编写了实现这些接口的DOM解析器,Java XML 处理API(Java API for XML Processing,JAXP)库使得实际上可以以插件形式使用这些解析器中的任意一个。要读入一个XML文档,首先需要一个DocumentBuilder对象,可以从 DocumentBuilderFactory 中得到这个对象,代码如下:
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
现在,可以从文件中读入某个文档:
?File f = …;
Document doc = builder.parse(f);
或者,可以用一个URL:
URL u = …;
Document doc = builder.parse(u);
甚至可以使用一个任意的输入流:
InputStream in = …;
Document doc = builder.parse(in);
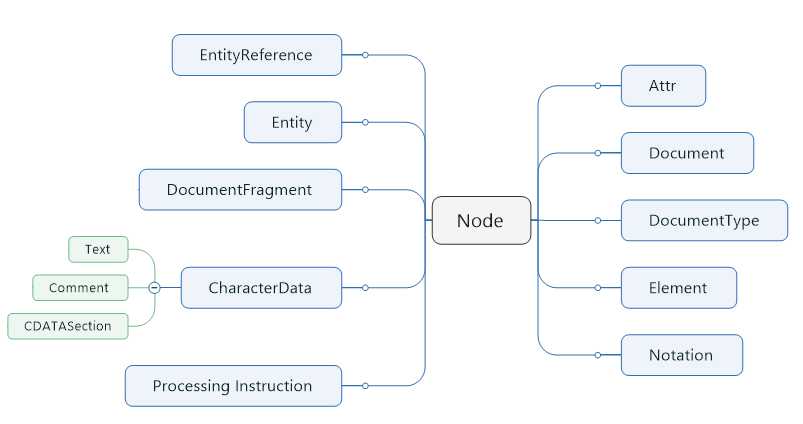
Document 对象时XML文档的树型结构在内存的表现,他由实现了 Node 接口及其各子接口的类对象构成,子接口层次结构如下:
DOM 解析XML文档的代码示例如下:
<?xml version="1.0" encoding="utf-8" ?>
<root>
????????<title>
????????????????<font enabled="false">
????????????????????????<!-- 字体名称 -->
????????????????????????<name>Helvetica</name>
????????????????????????<size>36</size>
????????????????</font>
????????????????<data>
????????????????????????<![CDATA[xml document root node <root.../>]]>
????????????????</data>
????????</title>
</root>
public static void main(String[] args) {
????????????????DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
????????????????try {
????????????????????????DocumentBuilder builder = factory.newDocumentBuilder();
????????????????????????Path xmlPath = Paths.get("E:\\IDEA Workspace\\exampleiostream\\src\\main\\java\\org\\drsoft\\examples\\xml", "appParse.xml");
????????????????????????InputStream xmlStream = Files.newInputStream(xmlPath, StandardOpenOption.READ);
????????????????????????Document xmlDocument = builder.parse(xmlStream);
????????????????????????StringBuilder sb = new StringBuilder();
????????????????????????sb.append("<?xml version=\"" + xmlDocument.getXmlVersion() + "\" encodin=\""
+ xmlDocument.getXmlEncoding() + "\" ?>");
????????????????????????Element root = xmlDocument.getDocumentElement();
????????????????????????sb.append("<" + root.getTagName() + ">");
????????????????????????NodeList nodeList = root.getChildNodes();
????????????????????????for (int i = 0; i < nodeList.getLength(); i++) {
????????????????????????????????if (nodeList.item(i) instanceof Element) {
????????????????????????????????????????sb.append(parseChildNodes((Element) nodeList.item(i)));
????????????????????????????????}
????????????????????????}
????????????????????????sb.append("</" + root.getTagName() + ">");
????????????????????????System.out.println(sb.toString());
????????????????} catch (ParserConfigurationException e) {
????????????????????????e.printStackTrace();
????????????????} catch (IOException ex) {
????????????????????????ex.printStackTrace();
????????????????} catch (SAXException e) {
????????????????????????e.printStackTrace();
????????????????}
????????}
? ?
????????private static String parseChildNodes(Element element) {
????????????????StringBuilder sb = new StringBuilder();
????????????????sb.append("<" + element.getTagName());
????????????????NamedNodeMap map = element.getAttributes();
????????????????for (int j = 0; j < map.getLength(); j++) {
????????????????????????sb.append(" " + map.item(j).getNodeName() + "=\"" + map.item(j).getNodeValue() + "\"");
????????????????}
????????????????sb.append(" >");
????????????????if (element.hasChildNodes()) {
????????????????????????NodeList list = element.getChildNodes();
????????????????????????for (int i = 0; i < list.getLength(); i++) {
????????????????????????????????if (list.item(i) instanceof Element) {
????????????????????????????????????????Element curElement = (Element) list.item(i);
????????????????????????????????????????sb.append(parseChildNodes(curElement));
????????????????????????????????????????continue;
????????????????????????????????}
????????????????????????????????if (list.item(i) instanceof CDATASection) {
????????????????????????????????????????CDATASection cdataSection = (CDATASection) list.item(i);
????????????????????????????????????????sb.append("<![CDATA[").append(cdataSection.getData()).append("]]>");
????????????????????????????????????????continue;
????????????????????????????????}
????????????????????????????????if (list.item(i) instanceof Comment) {
????????????????????????????????????????Comment comment = (Comment)list.item(i);
????????????????????????????????????????sb.append("<!-- "+comment.getData()+" -->");
????????????????????????????????????????continue;
????????????????????????????????}
????????????????????????????????if (list.item(i) instanceof Text) {
????????????????????????????????????????Text curText = (Text) list.item(i);
????????????????????????????????????????sb.append(curText.getData().trim());
????????????????????????????????????????continue;
????????????????????????????????}
????????????????????????}
????????????????}
????????????????sb.append("</" + element.getTagName() + ">");
????????????????return sb.toString();
????????}
? ?
标签:factor 机制 ppa getx ima 标准化 树结构 格式 soft
原文地址:http://www.cnblogs.com/li3807/p/6921466.html