标签:style http os ar 2014 问题 sp line on
本站有个翻译的文章,名字叫Ukkonen 的后缀树算法的清晰解释。这篇文章写得不错,但是还是犯了错误的。
我按照这篇文章的说明实现了所谓的Ukkonen算法,但是在测试时出现了错误,事后,进行了大量的排查(因为我一开始认为肯定不是文章的问题是我的问题,花了2天没解决,最后抛开“文章正确”的观点才解决)
下面,是我重新整理后的Ukkonen算法,采用的例子还是"abcabxabcd"。
生成后缀数和绘图的C++源码在http://www.oschina.net/code/snippet_593413_38384
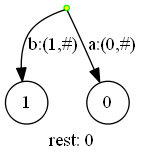
一开始依次插入‘a‘、‘b‘、‘c‘三个字符时,后缀树如下:

 、
、
图中,绿色的节点表示活动节点;节点内填充黄色,表示为根节点;没有活动边,说明活动长度为零。
图中的黑色箭头表示的边,x:(n,#)格式的,表示一个指向叶节点的边,x为该边第一个字符,n为该边起始的位置。正常的边会列出其包含的所有字符。
叶节点的值,表示该叶节点代表的后缀的起始位置。
从上面的例子说明,当向一个活动长度为零的活动点插入已有的边(的首字符)不存在的字符时,会插入新的边和叶节点。剩余后缀数会在扫描前+1,插入后-1,因此保持为0。
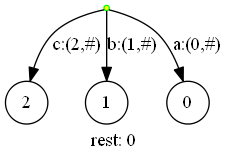
下一步,插入‘a‘(当前扫描位置3):

因为字符‘a‘已经存在于某个边中,于是我们就将活动三元组置为(root,‘a‘,1),剩余后缀数,并完成本次字符的扫描,事实上,活动边不是表示为‘a‘,而是3——这表示活动边是以文本的索引为3的字符起始的。即,活动三元组为(root,3,1)。剩余后缀数在扫描前+1,而本次没有插入后缀,因此剩余后缀数为1。
图中,绿色箭头表示一个活动边,而该边最后冒号后面的数字表示活动长度。
下一步,插入‘b‘(当前扫描位置4):
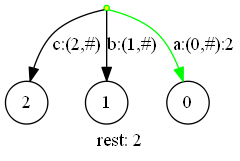
因为字符‘b‘也已经存在于活动边的下一个位置,于是我们就将活动三元组置为(root,3,2),剩余后缀数为2,并完成本次字符的扫描。
下一步,插入‘x‘(当前扫描位置5):
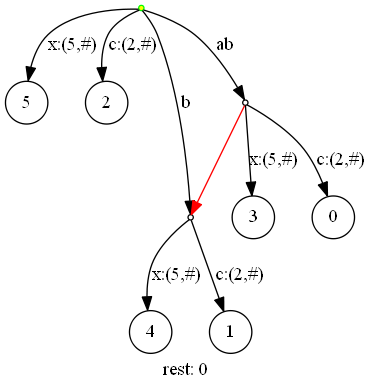
要插入‘x‘,当前边为"abcabx",而活动长度为2,该边下一个字符是‘c‘不是‘x‘,因此我们将该边分割开,也就是图中的ab边和c:(2,#)边及两者间的节点,并且向该节点添加一个新的边x:(5,#)和叶节点3。
为啥叶节点是3?因为当前后缀数为3,表示我们插入的后缀是"abx",在该后缀前面的部分是"abc",因为"ab"是隐含在已有后缀树里的,实际插入的边是从‘x‘开始的,但是叶节点却是从第二个‘a‘开始的,其索引为3。简化计算的话,就是:当前扫描位置+1-剩余后缀数。
在插入新的边之后,剩余后缀树-1;因为剩余后缀数>0,我们要重复插入后缀的操作,直到剩余后缀数==0或者遇到该后缀被隐含的情况。
在插入新的边和节点后,需要更新活动三元组。因为活动节点是根节点,操作为:活动边(索引)+1,活动长度-1,因此新的三元组为(root,4,1)。
文本索引4的位置,字符为‘b‘,据此,我们确定新的边为b:(1,#)。
因为循环,我们将该边分割、插入了新的边x:(5,#)和叶节点4。
同时,根据规则,我们要添加后缀指针,后缀指针会添加到扫描一次字符的过程中,因为分割边出现的新的内部节点之间(从旧到新)。假设一次扫描中,因分割出现的新节点依次为a,b,c;则应添加后缀指针,a -> b和b -> c。
图中,后缀指针用红色箭头表示。
此时,更新三元组为(root,5,0),而剩余后缀数为1。
下一次插入操作,和插入索引1、2、3位置的字符时一样的规则,在根节点(活动节点)添加了新的边x:(5,#)和叶节点5。
剩余后缀数为0,本次扫描结束。
下一步,插入‘a‘(当前扫描位置6):
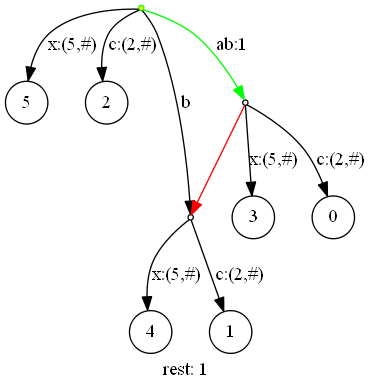
更新三元组为(root,6,1),剩余后缀数1
下一步,插入‘b‘(当前扫描位置7):
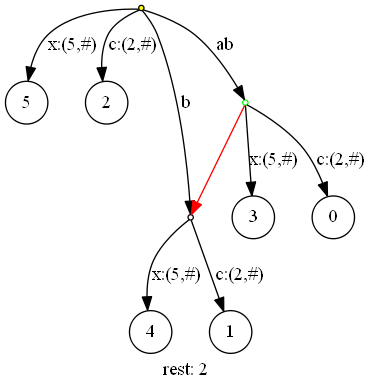
更新三元组为(root,6,2),剩余后缀数2;因为抵达了新的点,三元组重置为(green,6,0)
下一步,插入‘c‘(当前扫描位置8):

更新三元组为(green,8,1),剩余后缀数3;
下一步,插入‘d‘(当前扫描位置9):
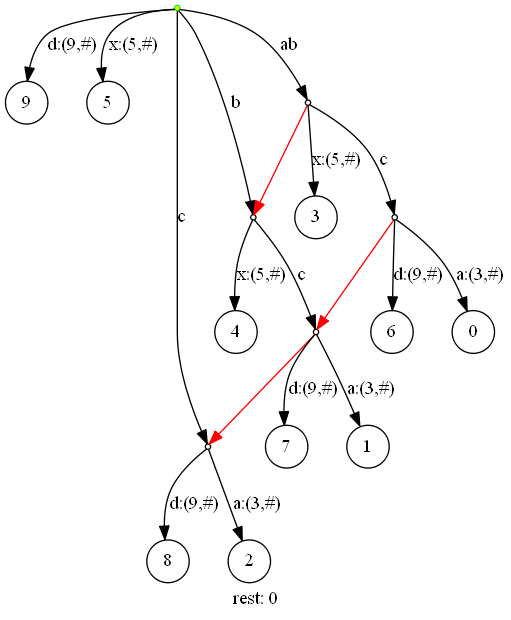
进行了一系列的后缀插入:
剩余后缀数+1;
分割c:(2,#)=>0边,然后因为活动点有后缀指针,因此活动点重置为该点(root经边b到达该点),而活动边和活动长度保持为8和1
分割c:(2,#)=>1边,生成新的后缀指针。此时,活动点没有后缀指针了。活动点也不是根节点。为了找到下一个活动点,有两种方法。
1)总而言之,我们知道剩余后缀数和当前扫描位置,换句话说,我们知道当前要插入的后缀,因此从根节点沿着该后缀查找就是了。
当前扫描位置9,剩余后缀数2,因此当前要插入的后缀从8起始,插入的是[8,9]即"cd",重置活动三元组为(root,8,1):即根节点、当前扫描位置-剩余后缀数+1,剩余后缀数-1
然后对这个三元组进行修正,也就是沿着后缀树走,直到活动长度为0或者小于活动边的长度。
因此,我们找到了root经边c到达的节点。
2)将活动三元组更新为(当前活动点,当前扫描位置-当前活动长度,当前活动长度)
从该活动点向父节点走,每次移动到父节点,都要让活动边(索引)减去经过的边的长度,而当前活动长度加上经过的边的长度
直到根节点,此时的操作和活动节点本来就在根节点是一样的:活动边(索引)+1,活动长度-1
或者移动到的节点有后缀指针,那么,我们沿着后缀指针移动一次活动节点,活动边和活动长度不变
到达根节点或者言后缀指针移动后,也要进行修正,沿着后缀树走,直到活动长度为0或者小于活动边的长度。
这两种方法不管采用哪一种,都会到达同一个点。一般说,树较小时,第一种更简单,而树比较复杂的时候,第二种更好。
分割c:(2,#)=>1边,生成新的后缀指针。活动三元组更新为(root,9,0),剩余后缀数1
插入新的边d:(9,#)和新的点9
本次扫描结束。
…………
这个过程可以一直持续下去,知道接受了一个终止标识符,或者进行结束操作。
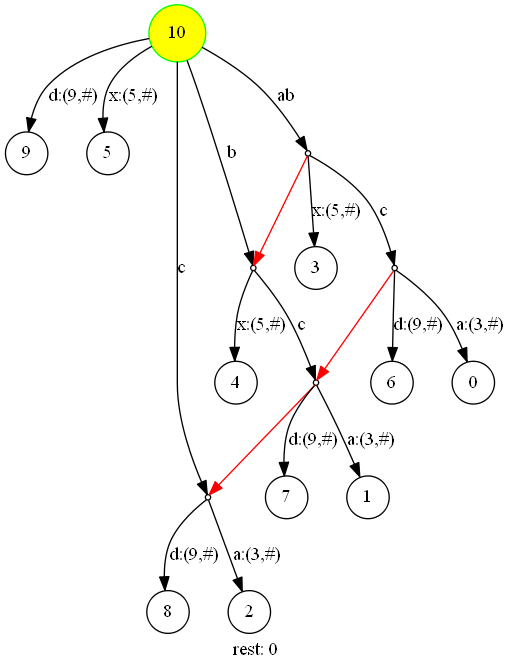
因为扫描‘d‘后,剩余后缀数已经减少到0了,我们的结束操作只是将根节点设置为一个后缀标识节点,代表空后缀。
事实上,因为‘d‘在字符串中仅在最后出现了一次,它的行为和扫描终止标识符是相同的。如果我们并不真的插入终止标识符(甚至我们都不用去比较终止标识符和活动位置下一个字符),将每一次添加仅含终止标识符的边和叶节点的操作替换为修改节点的属性,那么就是一个标准的结束操作了。
总的来说,我们只做了一个修改,那就是活动三元组的更新规则。
确切地说,是活动点不是根节点且没有后缀指针的时候的更新规则。
本文中的图都是用graphviz生成的。
标签:style http os ar 2014 问题 sp line on
原文地址:http://my.oschina.net/u/593413/blog/307421