标签:数据 display 正态分布 www sigma img native 维数 xpl
一、背景知识
1. Discriminant Learning Algorithms(判别式方法) and Generative Learning Algorithms(生成式方法)
现在常见的模式识别方法有两种,一种是判别式方法;一种是生成式方法。可以这样理解生成式方法主要是数据是如何生成的,从统计学的角度而言就是模拟数据的分布distribution;而判别式方法,不管数据是如何生成而是通过数据内在的差异直接进行分类或者回归。举个例子你现有的task是去识别一段语音属于哪一种语言。那么生成式模型就是你先让你的model先去学习各种可能性的语言,然后使用你学到的知识来对你要识别的语音做分类;而判别式模型是根据语音中的lingustic characteristic语言学特点来识别这段语音。July_Zh1博文认为生成式方法主要反映同类数据之间的相似度,判别式方法反映数据之间的的差异度。Fihser Kernel结合了二者的差异。PRML中有更加理论的阐述,有兴趣可以参考。
2. Fisher Information matrix
设一随机变量$x$
如果$x$ 为连续型随机变量,那么$x$的分布$p(x|\theta)$可以用正态分布模拟: $p(x|\theta) = \frac{1}{\sqrt{2\pi\sigma^2}}exp\left\{-\frac{(x-u)^2}{2\sigma^2}\right\}$
如果$x$是离散型随机变量,那么$x$的分布可以可以用类别分布categorical distribution模拟: $p(x|\theta) = \prod_{k=1}^{K}\theta_k^{x_k}$
式中: $0 \leq \theta_k \geq 1, \sum_k \theta_k = 1$
定义Fisher Score 为: $g(\theta,x) = \triangledown_\theta ln(p|\mathbf{\theta}) $
定义Fisher Information Matrirx 为: $ F = E_x\left[g(\theta,x),g(\theta,x)^T\right] $
二、 Fisher Kernel Methods
假设我们训练数据集为 $ X_t$,对应的Label 为 $S_t $(±1)(先考虑只有两类样本的情况) 。设 $X$ 为测试样本,$\hat{S} $为对测试样本预测值。
我们有:$\hat{S}$ = $sign\left (\sum_t S_t\lambda_t K(X_t,X)\right )$;
而对核函数有以下形式: $ K(X_i,X_i) = \phi_{X_i}^T \phi_{X_j} $.
对于每一个新样本的预测值$\hat{S}$是由原来样本的Label $S_t$ ”加权”得到。而“加权”由两部分组成:1)$\lambda_t$ 2) $K(X_t,X) $
这个Kernel描述的是训练样本$X_t$ 和测试样本$X$之间的相似度,Kernel有很多种,这里选择的是Fisher Kernel. 使用$U_x$代表Fisher Score, $F_\lambda$ 代表 Fisher Information Matrix。
如果将函数数看作一种映射方式,那么这个等式代表着我们不需要将每个样本真的映射到核空间进行计算,而只要确定核函数对应的$\phi_x$直接对函数进行计算就可以得到将样本映射到核空间的效果。(这也是支持向量机最重要的trick之一)
$\phi_x$ 就是我们定义的Fisher Vector
对于Fisher Kernel我们有: $\phi_x = F_\lambda^{-\frac{1}{2}}U_x$
对应的样本生成模型为:GMM(Gaussian Mixture Model) 即$X$服从的分布为GMM模型。此时$X = x_1,...,x_N$ 代表GMM中一系列变量。
二、对图像使用Fisher Encoding
Fisher encoding 的基本思想就是用GMM去构建一个视觉字典,本质上是用似然函数的梯度来表达一幅图像。
1. GMM构建视觉词典
对于图像而言$x$可以代表图像的特征(比如SIFT特征),一幅图像有很多特征$X = x_1,...x_T$
对于GMM model $X$的分布为:
$$p(X|\omega,\mu,\sum)$$
$\omega,\mu,\sum$分别为GMM中每个特征的权重,均值,协方差。
2. 计算Fisher Vector
首先定义:
$$L(X|\lambda) = logp(X|\lambda) = \sum_{t=1}^{T} logp(x_t|\lambda)$$.
图像中每个特征都是相互独立的:
$$p(x_t|\lambda) = \sum_{i=1}^{N}w_ip_i(x_t|\lambda)$$.
$p_i$位GMM中第i个component的pdf,$w_i$为其权值, $\sum_{i=1}^Nw_i=1$.
每个component $p_i$是多元高斯函数,期pdf如下:
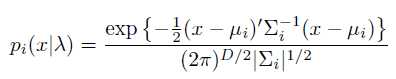
D是特征向量的维数,$\sum_i^-1位协方差矩阵
再定义特征$x_t$由第i个Gaussian component生成概率,这里使用了贝叶斯公式:
$$\gamma_t(i) = p(i|x_t,\lambda) = \frac{w_ip_i(x_t|\lambda)}{\sum_{j=1}^Nw_jp_j(x_t|\lambda)}$$
然后对各个参数求偏导:
$$U_x = \left[ \frac{\partial L(X|\lambda)}{\partial{\omega_i}}, \frac{\partial{L(X|\lambda)}}{\partial{\mu_i^d}}, \frac{\partial{L(X|\lambda)}}{\partial{\sigma_i^d}} \right]$$
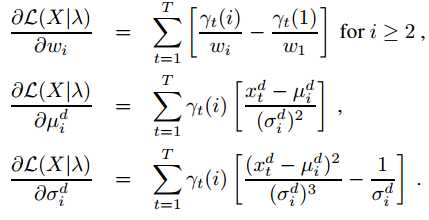
这里i是指第i个component,d是指特征$x_t$的维度,偏导是对每个componnet求,每个特征的维度都要计算,$U_X$维度是(2*D+1)*N,又由于$\omega_i$有约束$\sum_i \omega_i=1$,所以会少一个自由变量,所以$U_x$ 最终的维度是(2D+1)*N-1.
对上面的三个公式分别引入三个对应的fisher matrix:
$$ f_{w_i} = T\left(\frac{1}{w_i} + \frac{1}{w_1} \right) $$
$$ f_{u_i^d} = \frac{Tw_i}{\sigma_i^d)^2} $$
$$ f_{\sigma_i^d} = \frac{2T\omega_i}{(\sigma_i^d)^2}$$
之后便可求得归一化的fisher vector.
三、如何使用vl_feat进行fisher kernel encoding
参考资料:
1. 【Paper】: The Devil is in the details: an evaluation of recent feature encoding methods
比较了在目标识别领域不同encoding feature 的效果
2. 如何使用vl_feat计算Fisher Vectors:
http://www.vlfeat.org/overview/encodings.html
3. 如何使用vl_feat实现GMM
http://www.vlfeat.org/overview/gmm.html
4. Fisher information matrix for Gaussian and categorical distributions
https://www.ii.pwr.edu.pl/~tomczak/PDF/%5bJMT%5dFisher_inf.pdf
5. Fisher Vector Encoding
http://www.cs.ucf.edu/courses/cap6412/spr2014/papers/Fisher-Vector-Encoding.pdf
6. 【Paper】: Exploiting generative models in discriminative classifiers
Fisher Kerner 的推导和阐述
7【Paper】: Fisher Kernels on Visual Vocabularies for Image Categorization
http://www.cs.ucf.edu/courses/cap6412/spr2014/papers/2006-034.pdf
8. 【Paper】: Improving the Fisher Kernel for Large-Scale Image Classification
Fisher Kernel的优化
7. Fisher Vector and Fisher Score
http://blog.csdn.net/happyer88/article/details/46576379
Fisher Vector Encoding and Gaussian Mixture Model
标签:数据 display 正态分布 www sigma img native 维数 xpl
原文地址:http://www.cnblogs.com/vincentcheng/p/6885243.html