标签:通过 序列 启发式 ref 分支 决策树 最大的 开始 样本
Classification And Regression Tree, 分类回归树,简称CART。通过前面文章的介绍知道了决策树的几种生成方法比如ID3, C4.5等。CART是决策树有一种常见生成方法,既可以用于分类,也可以用于回归。CART假设决策树是二叉树,即,特征取值为“是”或者“否”,且约定左分支为取值“是”,右分支为取值“否”。通过递归二分每个特征,将输入空间划分为有限个区块,每个区块对应某一个输出值。
那么如何划分呢?
对回归树采用平方误差最小化原则,对分类树采用基尼指数(前面文章有介绍)最小化原则,进行特征选择生成二叉树。
回归树对应输入空间(特征空间)的一个划分,以及划分的区域上的输出值。假设将输入空间划分为M个区域(Region)R1, R2, ... , RM,每个区域上的输出值为cm,m=1,2, ... , M,于是回归树的模型,即函数为
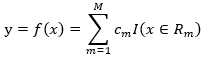 (1)
(1)
其中 I 函数在输入值x属于区域Rm时为1,否则为0。
注意回归中输出也是连续值(虽然这里得到还是离散值,不过可以看作是阶跃函数),所以可以采用平方误差,在输入空间的划分确定后,对于某一个区域Rm,平方误差为输出真实值与模型值差的平方和(当然可以用开平方和,这里为了计算方便),
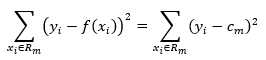 (2)
(2)
将平方误差最小化,则可以求得每个区域上的输出cm最优解,所以求(2)的极值,假设Rm上有n个样本点(虽然是回归是考虑的特征变量是连续型,但实际得到的样本都是离散的有限值),
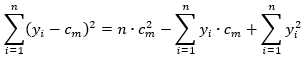 (3)
(3)
将(3)式求导,并令其等于0,
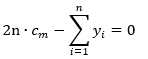
可以知道最优解为
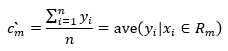 (4)
(4)
如此,就能求得每个区域Rm上的输出值。
以上是假设输入空间的划分已经确定之后所作的推导,那么问题来了,如何划分输入空间?这里采用启发式方法。
先任意选一输入特征,比如选择选择xj(注意,这里与前面保持相同的约定,上标表示维度,即输入的第j个特征),以及这个特征的一个取值s,作为切分变量和切分点,于是得到两个区域R1,R2
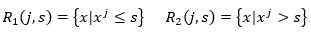
然后寻找最优切分变量j 和最优切分点s,具体地,就是为了让平方误差最小,求解
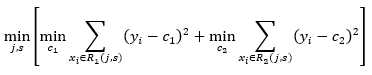 (5)
(5)
上式的含义是寻找j, s, c1, c2使得 R1, R2两个区域的平方误差最小,其中c1, c2分别是 R1, R2的输出值,根据(4)式,我们已经知道c1, c2的最优解为
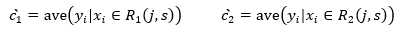
也就是说c1, c2是由 j, s 确定,所以问题最终变为寻找最优 j, s
由于特征维度有限,且样本点也有限,所以 j, s 的可能值个数也是有限的,所以一种简单的方法是,遍历所有可能的j, s 组合,寻找 (5)值,得到最优 j, s,于是将输入空间划分为 R1, R2,然后,再分别对这两个区域重复相同的过程,各自再划分为两个区域,直到满足停止条件(比如区域中只剩一个数据样本,或者区域中所有样本输出值相等,或者样本输出值的波动在一个很小的阈值之内),这样就生成了一棵回归树,这样的回归树通常称为最小二乘回归树(least squares regression tree)。
算法
输入:训练数据集D
输出:回归树f(x)
分类树使用基尼指数选择最优特征,同时确定该特征对应的切分点。
前面讲决策树的时候介绍过基尼指数了,这里再啰嗦一下,省得翻到前面的文章中查看。对于一个分类问题,假设共有K个分类值,输入系统中属于k分类的概率为pk,则系统的基尼指数为
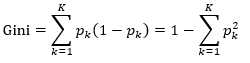 (6)
(6)
其含义是系统中本该是某一分类但实际又分类错误的可能性。基尼指数表征系统的不确定性,基尼指数越大,系统越不确定。比如抛硬币,正面向上概率为p,则反面向上概率为1-p,基尼指数为
Gini(0-1)=2*p*(1-p) (7)
当p=0.5时,基尼指数最大,此时正面和反面向上概率均为0.5,不确定性达到最大,不知道抛硬币是正面还是反面向上,而当p=0.9时,基尼指数减少,系统不确定性也减小,抛硬币倾向于认为正面向上,极端地,p=1,基尼指数达到最小(为0),此时系统不确定性也最小,因为每次抛硬币,毫无疑问,正面向上。
对于样本集D而言,基尼指数为
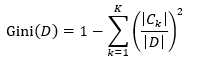 (8)
(8)
其中,|D|表示样本集D的数量,Ck表示分类值为ck的样本子集,|Ck|表示Ck的数量。
条件基尼指数
如果样本集合D根据特征A取值是否为a而被二分得到两个子集,
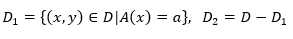
则给定特征A的条件下,集合D经过A=a分割后的条件基尼指数为
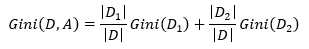 (9)
(9)
算法
输入:训练数据集D
输出:CART分类树
与使用ID3或者C4.5策略生成的决策树一样,CART决策树也需要剪枝,使决策树变小(简单),从而避免过拟合,提高对未知数据的预测。这里剪枝过程是自下而上进行,从生成的决策树T0底端开始剪枝,直到T0的根节点变成一个单节点,形成一个子树序列{T0, T1,... , Tn}(具体如何剪枝请继续阅读下文)。通过交叉验证法在独立的验证数据集上对剪枝后的树进行测试,从中选择最优子树。显然,这是对任意子树整体来考虑损失函数,最选择损失函数最小的那个子树作为最优子树。(这里的子树指的是对决策树T0做某种剪枝后形成的新的决策树)
计算子树的损失函数
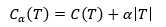 (10)
(10)
其中, T为子树序列中的任一子树。C(T)为子树对数据集的预测误差(如基尼指数),|T|为子树的叶节点个数,α>=0为参数,Cα(T)为子树T的整体损失,包含预测误差和模型复杂度两部分。参数α权衡数据集的拟合程度和模型复杂度。
假设固定α,则一定存在损失函数最小的子树,将其表示为Tα,容易验证这样的最优子树是唯一的(可以通过对上面那个子树序列进行验证)。因为剪枝前C(T)比剪枝后C(T‘)小(这一点我们前面就已经有过说明,简单来说就是,剪枝前更多的子节点可以有更多的分类来表示不同分类值的数据点,而剪枝后只能用一个分类表示不同分类值的数据点),而剪枝前模型复杂度|T|比剪枝后模型复杂度|T‘|大,也就是说C(T)与|T|变化趋势相反,所以固定α后,我们可以找到C(T)与α|T|的一个平衡,在某个子树上使得(10)式最小,这个子树就是最有子树。当α增大时,打破C(T)与α|T|的平衡,使得偏重α|T|,此时需要通过剪枝,降低α|T|从而重新找到平衡(虽然C(T)会增大,但是没关系,总会找到一个新的平衡),所以α增大时,最优子树Tα变小;反过来,α减小时,最优子树Tα变大。极端地,当α=0时,T0就是最优的(相当于此时没有考虑模型复杂度,生成的决策树是最优的,不需要剪枝,当然,这很理想);当α->无穷大时,根节点组成的单节点树是最优的(此时模型复杂度必须降到最低,当然,这是懒癌重症者嫌麻烦搞的最简单的树)。
所以我们得到这个结论:
α增大时,最优子树Tα变小;α减小时,最优子树Tα变大。
Breiman等人证明:可以用递归的方法对树进行剪枝。将α从小增大,0=α0<α1<...<αn<+∞,产生一些列的区间[αi,αi+1), i = 0,1, ... , n。剪枝得到的子树序列,序列中每个子树对应着区间α∈[αi,αi+1) 时的最优子树,即,α在不同区间中取值时的最优子树序列就是剪枝得到的子树序列,且序列中的子树是嵌套的(即T1是T0的子树,T2是T1的子树...这句话可以通过阅读下文对剪枝过程的阐述来理解)。
具体地,从整体树T0开始剪枝,对T0的任意内部节点t,考虑是否对节点t进行剪枝,
以t为单节点树的损失函数为
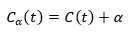
以t为根结点的子树Tt的损失函数为
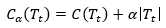
根据上面的讨论,当α足够小时,
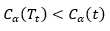
当α增大时,在某一αt处找到平衡,有
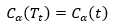
此后α继续增大,则有
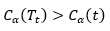
当α=αt时,Tt与t有相同的损失函数,而t的节点少,所以对Tt进行剪枝(α>αt时,同样是对Tt进行剪枝,下文可以看到我们其实要求的是最小的g(t),也就是最小的α,所以这里我们只关心α=αt的情况,αt也可以看成是一个阈值,我们关心这个阈值),
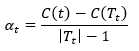
对T0中每一内部节点t,计算
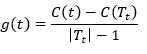 (11)
(11)
在T0中减去g(t)最小的Tt,得到的子树作为T1,同时将此时的g(t)记为α1,则T1就是区间[α1,α2)上的最优子树。
所以我们可以归纳一下,T0就是对应区间[α0,α1)上的最优子树,其中α0是已知的,为α0=0,增加α,当α达到min{g(t)}时,此时需要剪枝,根据上面的分析,此时的最优子树为次大的(仅比T0小),记为T1,所以T1就是区间[α1,α2)上的最优子树。然后对T1的所有内部节点,计算最小的g(t),此为α2,从T1中减去α2对应的内部节点,得到T2,所以T2就是区间[α2,α3)上的最优子树,如此剪枝下去,直到根节点(且没有内部节点可以剪枝,此时根节点必然有两个子节点,因为CART是二叉树),得到子树序列。
输入:CART算法生成的决策树T0
输出:最优决策树Tα
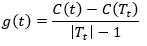 ,
,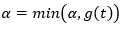
自下而上的访问各内部节点t,如果有g(t)=α,则进行剪枝,并对新的叶节点t以多数表决决定其类,得到树T
k=k+1,αk=α,Tk = T
ref
标签:通过 序列 启发式 ref 分支 决策树 最大的 开始 样本
原文地址:http://www.cnblogs.com/sjjsxl/p/6915477.html