标签:driver 工作流程 hadoop2 tar 默认 ogr ppm 优点 nod
MRv1:
- JobTracker: 资源管理 & 作业控制
- 每个作业由一个JobInProgress控制,每个任务由一个TaskInProgress控制。由于每个任务可能有多个运行实例,因此,TaskInProgress实际管理了多个运行实例TaskAttempt,每个运行实例可能运行了一个MapTask或ReduceTask。每个Map/Reduce Task会通过RPC协议将状态汇报给TaskTracker,再由TaskTracker进一步汇报给JobTracker。
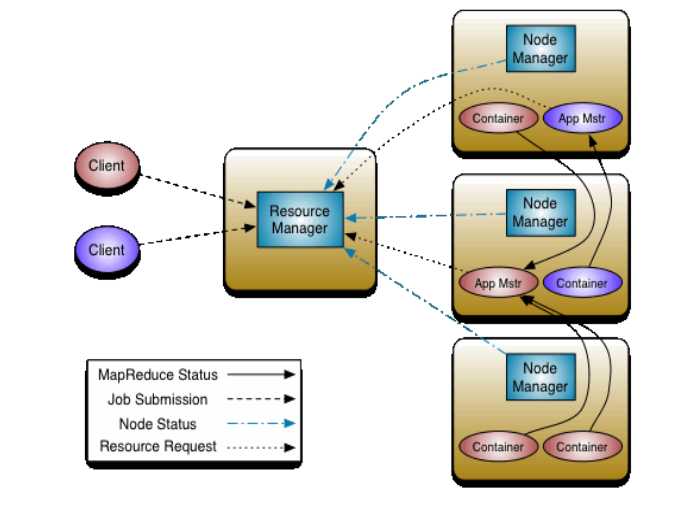
MRv2 / YARN:
- ResourceManager: 资源管理
- MRAppMaster:作业控制。MRAppMaster只负责管理一个作业,包括该作业的资源申请、作业运行过程监控和作业容错等。MRAppMaster会与ResourceManager、NodeManager通信,以申请资源和启动任务。
public class MRAppMaster extends CompositeService{
public void start(){
...
job = createJob(getConfig()); // 创建Job
...
}
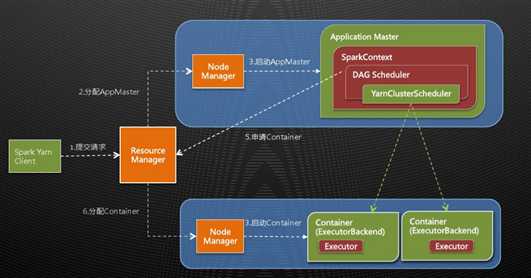
Yarn中的App Master可以理解为Spark中Standalone模式中的driver。
Container中运行着Executor,在Executor中以多线程并行的方式运行Task。工作流程大体与MRv2相同。
标签:driver 工作流程 hadoop2 tar 默认 ogr ppm 优点 nod
原文地址:http://www.cnblogs.com/wttttt/p/6925127.html