标签:sans 搜索字符串 dal pad 中文 null 查找 mat 大小写
正则表达式的概念Regular Expression RE优势:简洁 一行胜千言
用于对字符串的匹配
在文本处理中十分常用
表达文本类型的特征(病毒,入侵检测)
同时查找或替换一组字符串
匹配字符串的局部和全部
正则表达式的使用首先将符合正则表达式语法的字符串转化成正则表达式 特征
p = re.compile(regx)
| 操作符 | 说明 | 实例 |
| . | 表示任何单个字符 |
|
| [ ] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c,[a-z]表示所有的小写字母 |
| [^] |
| [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab,abc,abcc,abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc,abcc,abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示ab,abc |
| | | 左右表达式任意一个 | abc|def表示abc或def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc,abbc |
| ^ | 匹配字符串开头 | ^abc表示abc在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc在一个字符串的结尾 |
| () | 分组标识,内部只能使用|操作符 | (abc)表示abc,(abc|def)表示abc,def |
| \d | 数字,等价于[0-9] |
|
| \w | 单词字符等价于[A-Za-z0-9_] |
|
| ^[A-Za-z]+$ | 由26个字母组成的字符串 |
| ^[A-Za-z0-9]+$ | 由26个字母和数字组成的字符串 |
| ^-?\d+$ | 数据形式的字符串 |
| ^[0-9]*[1-9][0-9]*$ | 正整数形式的字符串 |
| [1-9]\d{5} | 中国境内的邮政编码 |
| [\u4e00-\u9fa5] | 匹配中文字符 |
| \d{3}-\d{8}|\d{4}-\d{7} | 国内电话号码 |
| (([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]) | IP地址 |
Re库是python的标准库
import re
re库采用raw string类型表示正则表达式,表示为
r‘text‘
如: r‘[1-9]\d{5}‘
r‘\d{3}-\d{8}|\d{4}-\d{7}‘
raw string是不包括对转义字符再次转义的字符串,建议使用raw string
Re库的主要功能函数
| 函数 | 说明 |
| re.search(pattern,string,flags=0) | 在一个字符串中匹配正则表达式的第一个位置,返回match对象 |
| re.match(pattern,string,flags=0) | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall(pattern,string,flags=0) | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split(pattern,string,maxsplit=0,flags=0) | 将一个字符串按照正则表达式匹配结果进行侵害,返回列表类型, maxsplit表示最大分割数,剩余部分作为最后一个元素输出 |
| re.finditer(pattern,string,flags=0) | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub(pattern,repl,string,count=0,flags = 0) | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串,repl为替换匹配字符串的字符串,count为最大替换次数 |
| re.compile(pattern,flags = 0) | 将正则表达式的字符串形式编译所正则表达式对象 |
| flags | 说明 |
| re.I re.IGONRECASE | 忽略正则表达式的大小写,[A-Z]能匹配小写字符 |
| re.M re.MULTILINE | 正则表达式的中的^操作符能够将给定字符串的每行当作匹配开始位置 |
| re.S re.DOTALL | 正则表达式的中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符 |
re库的另一种等价用法
函数式用法,一次性操作
rst = re.search(r‘[1-9]\d{5}‘,‘BIT 10081‘)
面向对象用法,编译后多次操作
pat = re.compile(r‘[1-9]\d{5}‘)
rst = pat.search(‘BIT 10081‘)
Match对象 是一次匹配的结果,包含匹配的很多信息
Match对象的属性
| 属性 | 说明 |
| .string | 待匹配的文本 |
| .re | 匹配进使用pattern对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
| 方法 | 说明 |
| .group(0) | 获得匹配的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start(),.end()) |
Re库的贪婪匹配和最小匹配
贪婪匹配:re库默认采用贪婪匹配,即输出匹配最长的子串
如:
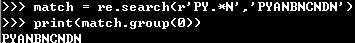
最小匹配:如何输出最短的子串
| 操作符 | 说明 |
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 前一个字符m至n次(含n),最小匹配 |
正则表达式库的使用
标签:sans 搜索字符串 dal pad 中文 null 查找 mat 大小写
原文地址:http://www.cnblogs.com/blackclody/p/6925697.html