标签:src abi 并且 ati 最优 bat em算法 width 问题
1.最小二乘法
注:这里假定你了解向量的求导公式,并且知道正态分布和中心极限定律(不知道的可以去数学知识索引翻翻)
(线性)最小二乘回归解法:

损失函数:平方损失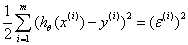 ,这里的误差可能是多种独立因素加和造成的,所以我们假定其符合均值为0的高斯分布,继而可以推出平方损失。参考Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降的Probabilistic interpretation,概率解释 部分
,这里的误差可能是多种独立因素加和造成的,所以我们假定其符合均值为0的高斯分布,继而可以推出平方损失。参考Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降的Probabilistic interpretation,概率解释 部分
适用场合:
优缺点:维数过高时,求逆效率过低
2.梯度下降法
这是一种迭代方法,先随意选取初始θ,然后不断的以梯度的方向修正θ,最终使J(θ)收敛到最小,当然梯度下降找到的最优是局部最优,也就是说选取不同的初值,可能会找到不同的局部最优点
常见的3终梯度下降算法:
1.批梯度下降(BGD)算法:

2.随机梯度下降(SGD)算法:

3.mini-batch随机梯度下降
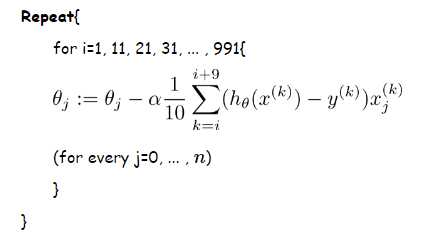
同样可以参照Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降的梯度下降(gradient descent)部分
3.最大(对数)似然估计(MLE)
参照:数理统计与参数估计杂记
4.最大后验估计(MAP)
引入了先验分布对参数做规范化,其参数估计是对贝叶斯后验概率求极值,而预测过程和最大似然估计一样
5.期望最大化算法(EM)
6.拟牛顿迭代(BFGS)
同时利用梯度和二阶导数做优化,相当于在当前点处进行二阶的泰勒展开,并找到二次曲面的极小值点。
迭代公式为: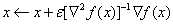
实际的优化问题中很难保证每一点的Hessian矩阵(二阶导数对应的矩阵)都正定(可逆),而拟牛顿法构造了一个不太精确,但是可以保证正定的矩阵
Hessian矩阵的逆的更新公式是:
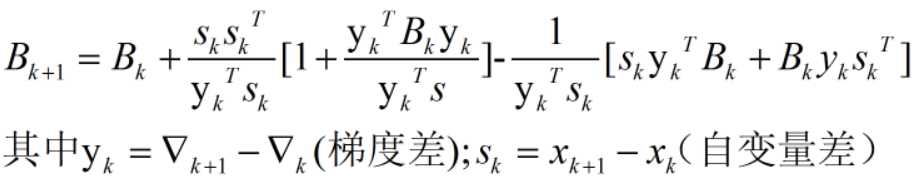
当学习速率满足Wolfe条件时,可以保证找到比现有函数更优的一个点;
Wolfe条件:
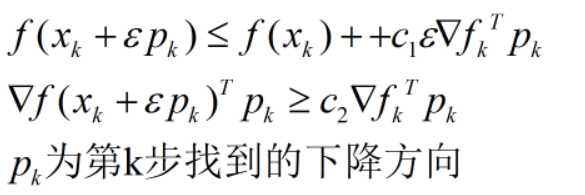
标签:src abi 并且 ati 最优 bat em算法 width 问题
原文地址:http://www.cnblogs.com/arachis/p/tools.html