标签:apach cti cli 声明 size png 文件系统 config ble
目录
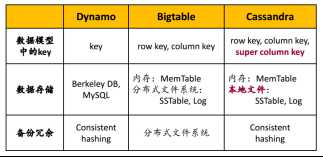
一、Key-value store
1.Dynamo
1.1 consistence hash
1.2 Quorum机制保证无主节点正确性
1.3 Eventual Consistency
2.Bigtable/Hbase
3.Cassandra
二、Distributed Coordination:Zookeeper
1.概念
2.数据模型
3.基本原理
4.应用案例
(本文为陈世敏老师课程笔记)
-----------------------------------------------
一、Key-value store
sql不能满足所有公司应用需求,所以有了no-sql的数据库,key-value 是典型代表之一。
1.Dynamo
亚马逊家的系统
1.1 consistence hash
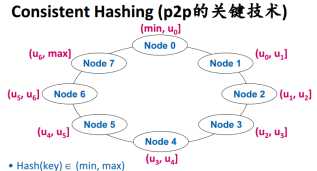
在三个备份的情况下,Node j上实际存储的数据是(uj-3, uj]
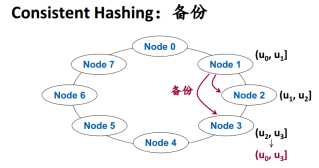
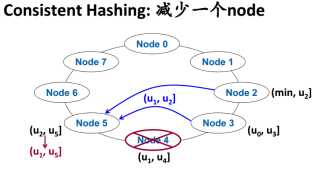
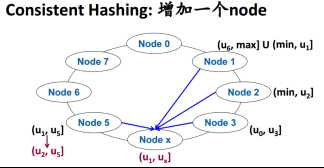
1.2 Quorum机制保证无主节点正确性
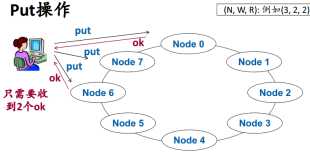
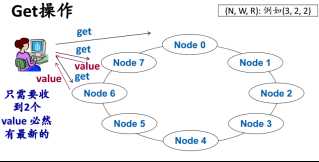
如果有N个副本,写的时候保证至少写w个副本,读的时候至少从R个副本读了数据,R+W>N,可以确保读到最新数据。
1.3 Eventual Consistency
put为了提高效率,不等待n个节点全部写完,但系统总会保证最终所有节点都写成功。
2.Bigtable/Hbase
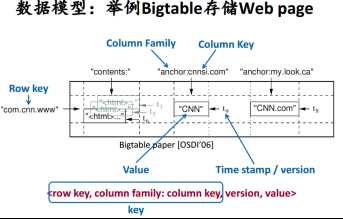
column family:需要事先声明,种类有限
column key:可以有很多
row key:按顺序存储
存储时候,每个列分开,类似列式数据库
3.Cassandra
facebook 公司在apache上面的开源项目,与可以看成是前两者的结合:
二、Distributed Coordination:Zookeeper
1.概念
Yahoo!研发的分布式协调系统,对master有很好的容错,多台机器运行master节点,一台为主,其余为备份,主master故障时候某台备份 成为主mater.Zookeeper可以和cleint在同一台机器上。2f+1台机器可以容忍f个节点故障.
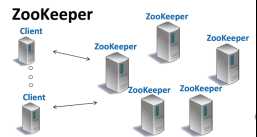
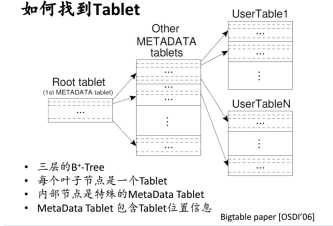
2.数据模型-Data Tree 和API
是一个简化的文件系统,每个顶点成为znode,从跟路径唯一确定。
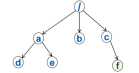
一个client连接到zookeeper,就开始一个session,结束时候client主动关闭,经过一个Timeout没有收到任何通信,zookeeper也关闭。
API-创建、删除、判断znode存在、找孩子
create(path, data, flags) flag:Regular/Ephemeral 临时数据在session结束会删除,返回znode的name
delete(path, version) version一致,才能delete
exists(path, watch) 返回true/false,可以设置watch,znode被删除/新建,收到通知
getChildren(path, watch) 返回所有children的name,可以设置watch
API-读/修改数据:
getData(path, watch) 返回数据和version,可以设置watch,修改时候通知
setData(path, data, version) 只有version一样时候才可以修改
等待前面操作完成:
sync() 等待,直到之前的写操作都完成
3.基本原理
3.1 Watch机制
client读数据需要注册watch->数据改变,zookeeper通知client->watch失效,只能被调用一次,需要继续关注再次watch
3.2 支持同步与异步
同步时候发送一个请求会阻塞等待响应;异步允许client发送多个请求,不需要阻塞等待请求完成,提供callback函数,请求完成时被调 用。前面的API都提供这两种实现。
3.3 zookeeper保证
linearizable write:所有的写操作可串行化
FIFO client order:每个client的读写操作按照FIFO的顺序发生,并且其它client可以看到。
不同client之间的读写顺序没有任何保证,可能读到旧数据,一定要读最新数据调用sync.
3.4 系统结构
每个节点维持相同的tree,外存有snapshot+log提供crash recovery
+Request processor:
每个client只连接到一台zookeeper,所有读操作由该服务器用其本地状态Replicated Database回复
对于写操作,一个leader其他为follower,follower把写请求发送给leader,leader协调所有follower一起完成写操作
Leader把每个Client写操作包装成Idempotent Transaction,每个Txn可以执行多次来恢复,Txn有唯一递增ID
+Atomic broadcast:
Leader带领follower,保证写操作是全局串行化,使用ZAB协议(2pc变形)
+Replicated Database:
每个leader/follower 读操作可以绕开前段,直接读。在Atomic Broadcast后,写操作修改本地的Replicated Database
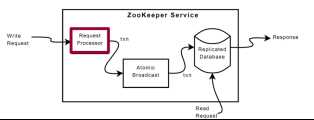
3.5 ZAB协议
3.5.1 两种工作模式:
+正常Broadcast:Leader向Follower广播新的写操作
+异常Recovery:竞争新的leader,新的leader进行恢复
3.5.2 ZAB Broadcast流程:
Leader把一个新的Txn写入本地log,广播propose这个txn->每个follower收到propose后,写入本地log,向leader发回Ack->leader收到f个 ack之后(这时候加上自己是f+1个确认正常) ,写commit到log,commit修改zookeeper树->follower收到commit后,写commit到log,然后 修改zookeeper树。
注意:
可以异步发送多个propose,从而批量写入log;
commit阶段不需要ack;
leader长时间未收到f个ack,需要进入recovery.
3.5.3 Recovery
+竞选leader:每个节点查看自己的最大TxnID,选择leader为max(TxnID)为最大的节点。
+Txn为64位,高32位代表epoch,第32位代表in-epoch id,每次精选leader epoch++,于是每次recovery一定有了更高的txn id.
+新的leader 把所有正确执行的Txn都确保正确执行(idempotent,再广播一次),其它已经提交但是还没有执行的client操作都丢弃, client会重试。
4.应用案例
+Configuration Managemen:一个分布式系统可以事先确定一个ZooKeeper路径path,把配置信息存储在这个给定的Znode,分布式系统的每台 机器,都去getData(path, watch)
+Simple Lock:可以把lock对应为一个Znode,加锁=创建Znode,解锁=删除Znod,加锁不成功,可以用watch,当Znode被删除时,可以得到通 知
标签:apach cti cli 声明 size png 文件系统 config ble
原文地址:http://www.cnblogs.com/gardenofsjw/p/6919387.html