标签:向量 需要 开始 没有 空间 函数 聚类 怎么办 kernel
支持向量机(Support vector machine,以下简称SVM)是一种监督学习模型,其学习算法可分析数据,并用以解决分类和回归问题。给定一训练数据集,每个数据点(或实例)属于二分类中的某个分类,SVM训练算法则建立一个模型,这个模型可以将一个新的数据实例归于某一类(预测)。除了线性分类,SVM可以有效地执行非线性分类,这是因为使用了核技巧(kernel trick)或者称核函数(kernel function),从而隐式地将输入映射到高维特征空间。
当数据没有标记时,监督学习也就实现不了,此时就需要非监督学习,试图去发现数据会天然地聚合成组(聚类),然后将新的数据实例映射到其中某一个组。具有增强SVM的聚类算法称作支持向量聚类(Support vector clustering),通常用于工业应用中当数据没有标记或者只有部分数据标记作为分类的预处理的时候。
(以上是本人蹩脚的维基百科翻译,仅作初印象认识SVM,不懂也没关系,毕竟翻译的不好,下面会由浅入深地介绍)
所以说SVM到底是什么呢?可能几句话难以概括全部,下面将SVM分为几类,然后逐一去了解。
SVM是一种二类分类模型,前面介绍感知机的时候知道感知机也是一种二类分类模型。区别在于,SVM是定义在特种空间上间隔最大的分类器,而且不一定是线性分类。
为什么要强调间隔最大?
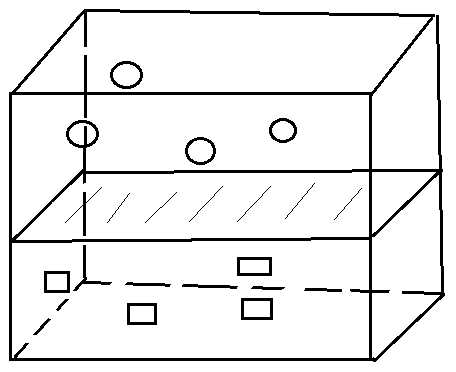
如下图,是一个二类分类,将图标分为圆圈和方框,
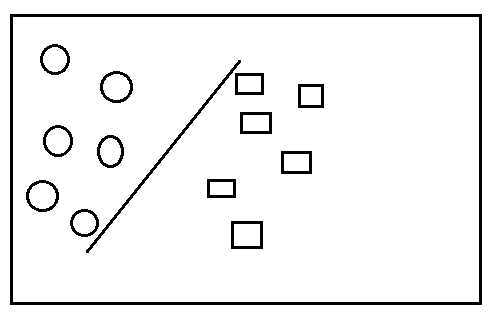
显然这样的分类虽然可行,但是不够好,为什么? 假设现在又多了几个图标,如下图,
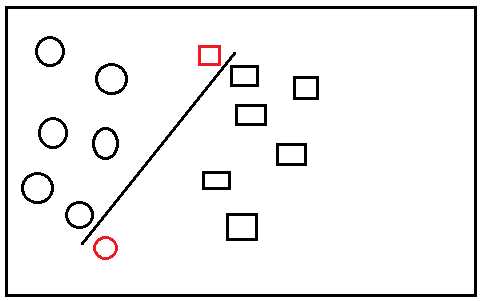
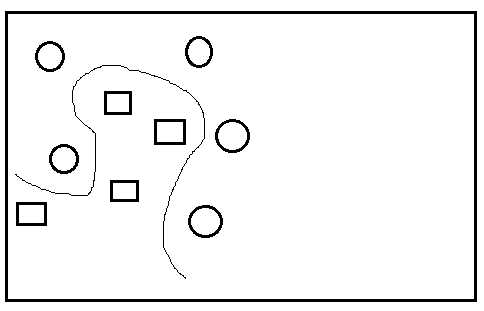
显然此时,新的图标(数据实例)被分错了类,而如果一开始我们如下图分类,
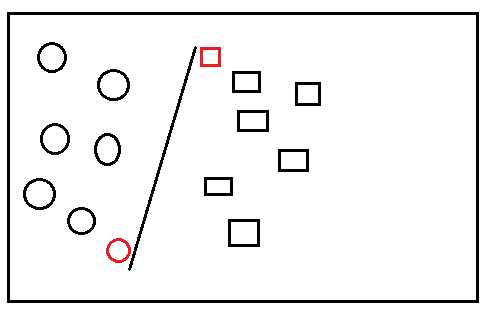
此时新的图标分类就正确了,比较这两种分类,发现后一种分类,分类线两边的间距更大,显然这是一种较好的分类。
下面说说为什么不一定是线性分类,假设现在图标分布为
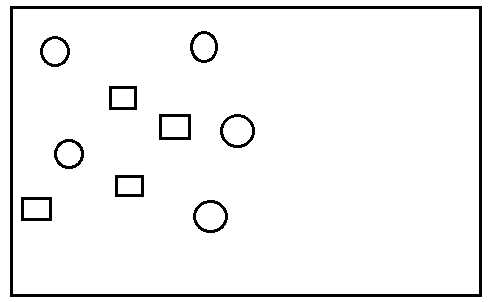
这样就无法用一条线来分类了,此时怎么办呢,有牛人已经想到了一种方法,就是将这些分布在二维上的数据点映射到三维空间(即,上文说的将输入映射到高维特征空间),变成
此时,就可以容易的用一个平面(线性)来隔断,分成两类,如果在回归到二维平面,可能就是下面图中所示,就变成了非线性分类,这一技巧就是核技巧。
SVM学习方法包含构造由简到繁的模型:线性可分支持向量机(linear support vector machine in linearly separable case),线性支持向量机(linear support vector machine)以及非线性支持向量机(non-linear support vector machine)。当训练数据线性可分时,通过硬间隔最大化(hard margin maximization),学习一个线性分类器,此即线性可分支持向量机,又称硬间隔支持向量机,这是最基础的模型。当训练数据近似线性可分时,通过软间隔最大化(soft margin maximization)学医一个线性分类器,此为线性支持向量机,又称软间隔支持向量机。当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
后面分别介绍这几种SVM。
ref
标签:向量 需要 开始 没有 空间 函数 聚类 怎么办 kernel
原文地址:http://www.cnblogs.com/sjjsxl/p/6935000.html