标签:splay str 配置 ack 课程 collect track ros 传输数据
目录
一、MapReduce/Hadoop
1.编程模型
2.系统实现
3.典型算法
二、Microsoft Dryad
(本文为陈世敏老师课程笔记)
----------------------------------------
一、MapReduce/Hadoop
Google 2014年推出。
1.编程模型
整体思路:程序员串行写程序 ,系统分布式并行完成,但要有很多限制,牺牲程序的功能。
数据模型:<key,value> 记录之间无序。
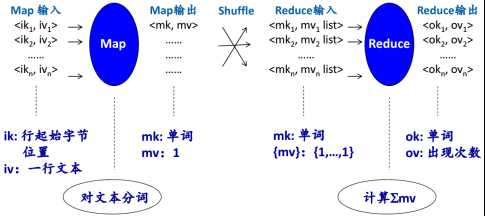
MapReduce执行过程:
+Map(ik, iv) ->{<mk, mv>} 输入是一个记录,输出0~多个
+shuffle 系统完成,等于group by mk <mk,{mv} list>
+ Reduce(mk, {mv}) ->{<ok, ov>}
word count 为例子:
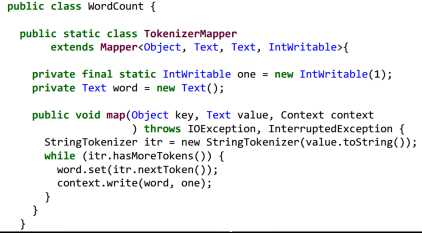
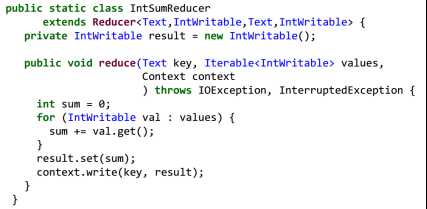

2.系统实现
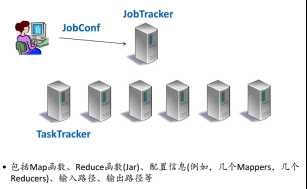
2.1 架构组成
JobTracker:控制协调作业的运行
TaskTracker:执行Map Task 或Reduce Task
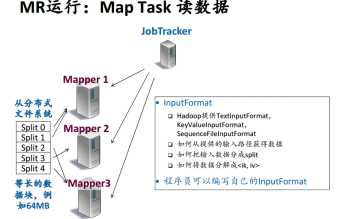
包括Map函数、Reduce函数(Jar)、配置信息(例如,几个Mappers,几个Reducers)、输入路径、输出路径等
2.2 处理过程
(1)Split代表一个HDFS数据块,Split的个数可能多于Mapper的个数,每个split对应一个Map Task,每个Mapper需要处理多个Task.JobTracker采用就近原则,让机器尽量处理本机,减少网络传输。
(2)对于每个记录,调用一次Map函数生成<mk,mv>,每个mk调用partitioner(可以是Hash Partitioner)计算对应的Reduce task id,属于同一个id从小到达,存储在同一个本地硬盘文件。
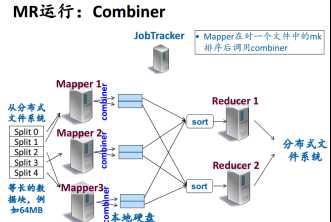
(3)Mapper一端对重复mk进行本地累计,即collection,减少网络传输。
(4)Reducer从Mapper得到数据,由于每个文件已经排序,对多个结果进行归并实现group by.
(5)Reduce对每一项调用一次Reduce函数-> OutputFormat
2.3 Fault Tolerance 容错
JobTracker发现宕机会把任务分配给另一个worker。
+如果Mapper宕机,其split分配给其它Mapper,通知所有Reduce这些splite对应的新Mapper
+如果Reduce宕机,新的Reducer重新从Mappers传输数据。
3.典型算法
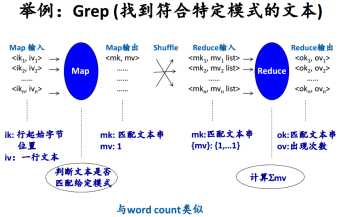
3.1 Grep 找到符合特定模式的文本
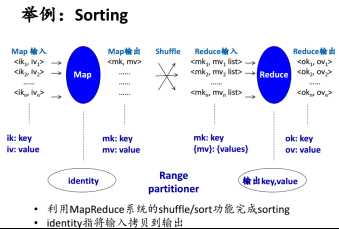
3.2 sorting
3.3 Equi-join
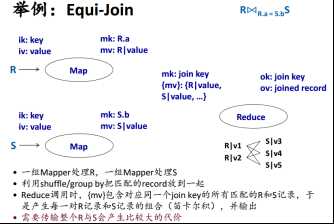
二、Microsoft Dryad

标签:splay str 配置 ack 课程 collect track ros 传输数据
原文地址:http://www.cnblogs.com/gardenofsjw/p/6921356.html