标签:log rsh eval mem 技术 models .com variable document
1. Mixed membership model
This model wants to discover a set of memberships
In contrast, cluster models aim at discovering a single membership
In clustering:
In LDA:
LDA inputs: set of words per doc for each doc in corpus
LDA outputs: corpus-wide topic vocab distributions, topic assignments per word, topic proportions per doc
Typically LDA is specified as a bayesian model
2. Gibbs sampling
Iterative random hard assignments
predictions:
benefits:
Procedure:
3. Collapsed gibbs sampling
Based no special structure of LDA model, can sample just indicator variables ziw.
no need to sample other parameters
Procedure:
randomly reassign ziw based on current assignment zjv of all other words in document and corpus.
How much doc likes each topic based on other assignments in doc
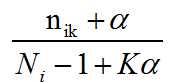
nik is the current assignment to topic k in doc i
Ni is the words in doc i
α is the smoothing param from bayes prior
How much each topic likes the word dynamic based on assignments in other docs in corpus
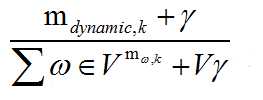
mdynamic,k is the assignments corpus-wide of word dynamic to topic k
γ is the smoothing param
V is the size of vocab
probabilities = how much doc likes topic * how much topic likes word(normalize this product of terms over k possible topics)
Based on the probabilities increment count based on new assignmentof ziw
what to do with the collapsed samples?
From best sample of ziw, can infer
机器学习笔记(Washington University)- Clustering Specialization-week five
标签:log rsh eval mem 技术 models .com variable document
原文地址:http://www.cnblogs.com/climberclimb/p/6931411.html