标签:返回 post ted ... 需要 www reduce 第一时间 匿名
首先要明确协程函数特点:yield变为表达式,可以通过g.send(value)传值,用send传值时协程函数需要初始化,也可以说是生成器函数的一种
yield的另一种用法:
1、yield的语句形式: yield 1(生成器)
2、yield的表达式形式: x=yield (协程函数)
x=yield
g.send(‘1111‘),先把1111传给yield,由yield赋值给x
然后再往下执行,直到再次碰到yield,然后把yield后的返回值返回
>>> def func():
n = 0
while 1:
n = yield n #可以通过send函数向n赋值
f = func()
f.next() # 默认情况下n为0
0
f.send(1) #n赋值1
1
f.send(2)
匿名函数
f=lambda x,y:x+y
print(f)
print(f(1,2))
lambda x,y:x+y
max,min,zip,sorted的用法
salaries={
‘egon‘:3000,
‘alex‘:100000000,
‘wupeiqi‘:10000,
‘yuanhao‘:2000
}
print(max(salaries))
res=zip(salaries.values(),salaries.keys())
# print(list(res))
print(max(res))
def func(k):
return salaries[k]
print(max(salaries,key=func))
print(max(salaries,key=lambda k:salaries[k]))
print(min(salaries,key=lambda k:salaries[k]))
print(sorted(salaries)) #默认的排序结果是从小到到
print(sorted(salaries,key=lambda x:salaries[x])) #默认的排序结果是从小到到
print(sorted(salaries,key=lambda x:salaries[x],reverse=True)) #默认的排序结果是从小到到
内置函数
map
reduce
filter
def func(f):
return f
res=func(max)
print(res)
l=[‘alex‘,‘wupeiqi‘,‘yuanhao‘]
res=map(lambda x:x+‘_SB‘,l)
print(res)
print(list(res))
nums=(2,4,9,10)
res1=map(lambda x:x**2,nums)
print(list(res1))
from functools import reduce
l=[1,2,3,4,5]
print(reduce(lambda x,y:x+y,l,10))
l=[‘alex_SB‘,‘wupeiqi_SB‘,‘yuanhao_SB‘,‘egon‘]
res=filter(lambda x:x.endswith(‘SB‘),l)
print(res)
print(list(res))
递归调用:在函数调用过程中,直接或间接地调用了函数本身,这就是函数的递归调用
age(n)=age(n-1)+2 n>1
age(n)=18 n=1
def age(n):
if n == 1:
return 18
return age(n-1)+2
print(age(5))
二分法
def search(find_num,seq):
if len(seq) == 0:
print(‘not exists‘)
return
mid_index=len(seq)//2
mid_num=seq[mid_index]
print(seq,mid_num)
if find_num > mid_num:
#in the right
seq=seq[mid_index+1:]
search(find_num,seq)
elif find_num < mid_num:
#in the left
seq=seq[:mid_index]
search(find_num,seq)
else:
print(‘find it‘)
search(77,l)
search(72,l)
search(-100000,l)
模块与包
import导入模块干的事:
1.产生新的名称空间
2.以新建的名称空间为全局名称空间,执行文件的代码
3.拿到一个模块名spam,指向spam.py产生的名称空间
import time import spam time.sleep(10) import spam as aa print(aa.money)
from ... import ...
from spam import money,read1,read2,change
1.产生新的名称空间
2.以新建的名称空间为全局名称空间,执行文件的代码
3.直接拿到就是spam.py产生的名称空间中名字
from spam import money print(money)
from ... import ...
优点:方便,不用加前缀
缺点:容易跟当前文件的名称空间冲突
模块的搜索顺序:
内存---->内置------->sys.path
包是一种通过使用‘.模块名’来组织python模块名称空间的方式
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点 的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
__init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
正则简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
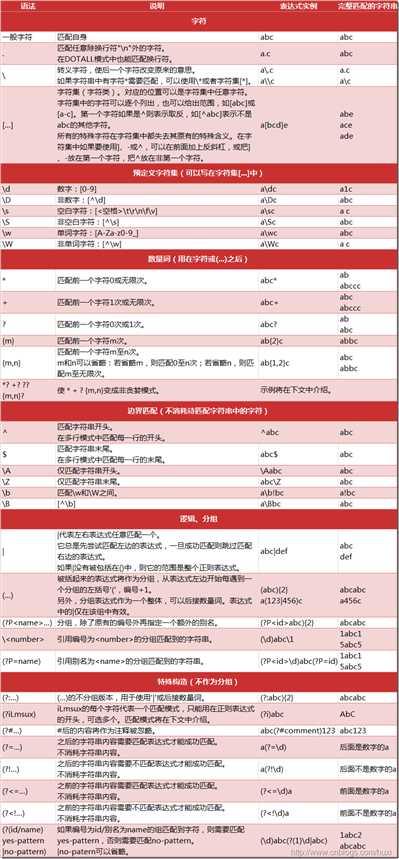
import re line = "Cats are smarter than dogs" matchObj = re.match( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if matchObj: print "matchObj.group() : ", matchObj.group() print "matchObj.group(1) : ", matchObj.group(1) print "matchObj.group(2) : ", matchObj.group(2) else: print "No match!!"
标签:返回 post ted ... 需要 www reduce 第一时间 匿名
原文地址:http://www.cnblogs.com/scxbk/p/6931774.html