标签:alt 其他 title dea 表达 加密 print final closed
淘宝页面比较复杂,含有各种请求参数和加密参数,如果直接请求或者分析Ajax将会非常繁琐。Selenium是一个自动化测试工具,可以驱动浏览器去完成各种工作,比如模拟点击、输入和下拉等多种功能,这样我们只需关心操作,不需要关心后台发生了怎么样的请求下面对具体操作步骤进行详述。
创建webdriver对象
#创建一个WebDriver对象 from Selenium import webdriver browser = webdriver.Chrome()
大多数网络应用程序都使用AJAX技术。当浏览器加载页面时,该页面中的元素可能会以不同的时间间隔进行加载。这使得定位元素变得困难:如果一个元素尚未存在于DOM中,则定位函数将引发ElementNotVisibleException异常。使用等待,我们可以解决这个问题。等待在执行的动作之间提供了一些松弛 - 主要是定位元素或任何其他操作与元素。
等待示例

from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
目标网站分析
查看CSS选择器
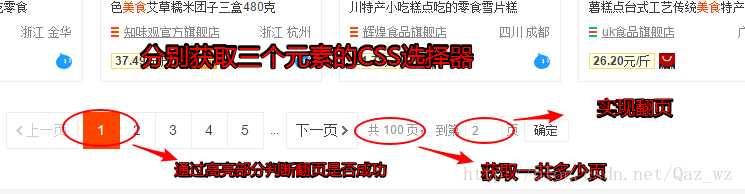
分别获取这四个元素的CSS选择器,方法为动图所示
代码
主程序
import re from pyquery import PyQuery as pq from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from config import * import pymongo #MogoDB配置 client = pymongo.MongoClient(MONGO_URL) db = client[MONGO_DB] #创建WebDriver对象 browser = webdriver.Chrome() #等待变量 wait = WebDriverWait(browser,10) #模拟搜索美食 def search(): try: browser.get(‘https://www.taobao.com/‘)#打开淘宝首页 tb_input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, ‘#q‘)) )#等待输入框加载完成 search_btn = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, ‘#J_TSearchForm > div.search-button > button‘)) )#等待搜索按钮加载完成 tb_input.send_keys(‘美食‘)#输入框中传入“美食” search_btn.click()#点击搜索 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.total‘)) )#加载完成,获取页数元素 get_products() return total.text#获取元素中的文本 except TimeoutException: return search()#若发生异常,重新调用自己 #翻页函数 def next_page(page_number): try: page_input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.form > input‘)) )#等待翻页输入框加载完成 confirm_btn = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit‘)) )#等待确认按钮加载完成 page_input.clear()#清空翻页输入框 page_input.send_keys(page_number)#传入页数 confirm_btn.click()#确认点击翻页 wait.until(EC.text_to_be_present_in_element( (By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > ul > li.item.active > span‘), str(page_number)) )#确认已翻到page_number页 get_products() except TimeoutException: next_page(page_number)#若发生异常,重新调用自己 #获取商品信息 def get_products(): wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-itemlist .items .item‘)) )#等待商品信息加载完成,商品信息的CSS选择器分析HTML源码得到 html = browser.page_source#得到页面HTML源码 doc = pq(html)#创建PyQuery对象 items = doc(‘#mainsrp-itemlist .items .item‘).items()#获取当前页所有商品信息的html源码 for item in items: product = { ‘image‘:item.find(‘.pic .img‘).attr(‘src‘), ‘price‘:item.find(‘.price‘).text(), ‘deal‘:item.find(‘.deal-cnt‘).text()[:-3], ‘title‘:item.find(‘.title‘).text(), ‘shop‘:item.find(‘.shop‘).text(), ‘location‘:item.find(‘.location‘).text() } print(product) save_to_mongoDB(product)#保存到MongoDB #保存到MongoDB def save_to_mongoDB(product): try: if db[MONGO_TABLE].insert(product): print(‘存储到MongoDB成功‘,product) except Exception: print(‘存储到MongoDB失败‘,product) def main(): total = search()#获取商品页数,字符串类型 total = int(re.compile(‘(\d+)‘).search(total).group(1))#利用正则表达式提取数字,并强制转换为int类型 for i in range(2, total+1): next_page(i) browser.close() if __name__ == ‘__main__‘: main()
MongoDB配置代码
MONGO_URL = ‘localhost‘ MONGO_DB = ‘taobao‘ MONGO_TABLE = ‘meishi‘
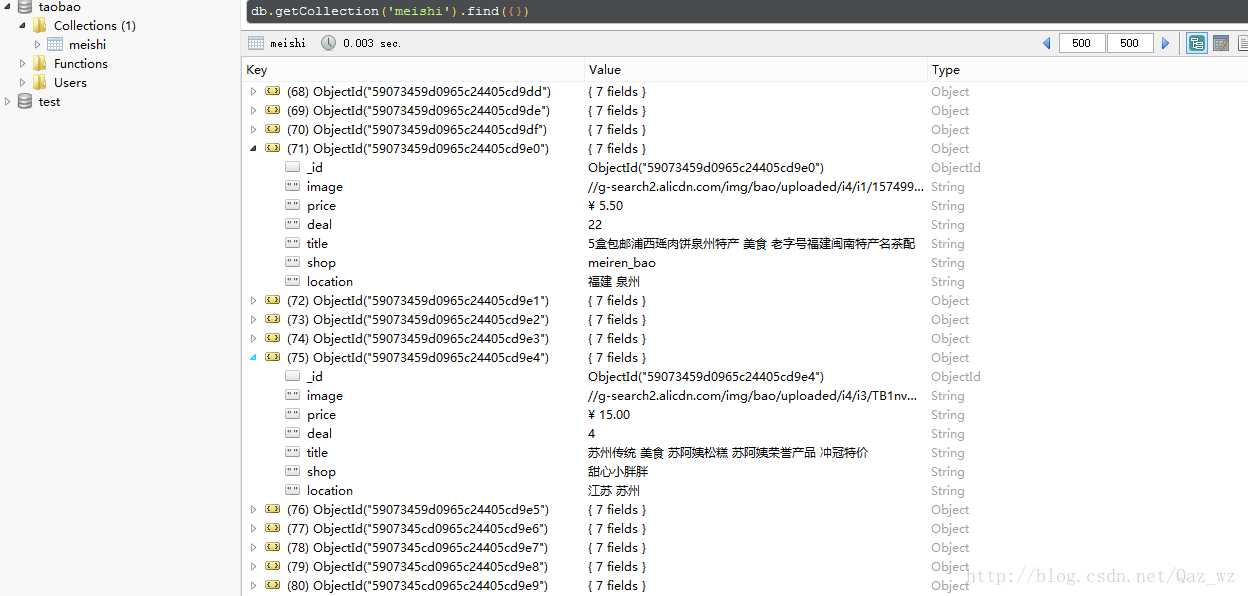
运行结果
标签:alt 其他 title dea 表达 加密 print final closed
原文地址:http://www.cnblogs.com/ttrrpp/p/6943200.html
