标签:传统 cpu 目的 标准 而且 如何 来讲 屏幕 amber
出于3D计算机图形学和图形渲染方面的个人兴趣,脑子里便萌生出了自己实现一个渲染器的想法,主要是借助pathtracing这种简单的算法,外加GPU加速来实现,同时也希望感兴趣的朋友们能够喜欢,也欢迎提出一些更好的看法~~。
(本人水平有限,若有错误也请指正~)
首先列个提纲......:
1)局部光照与全局光照简介
2)GPU并行运算在图形渲染的应用
—————————————————————————————————————————————————
1)pathtracing算法简介:
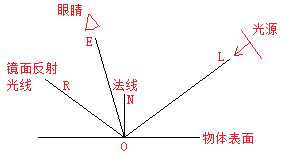
在利用计算机表达现实生活景物的思想逐渐成型时,人们最初是利用所谓的局部光照模型来进行物体表面着色的,这种光照模型只能算得上是预览品质,在当时计算能力不高的硬件水平上已经能够达到一个比较满意的效果,这里我们要记住两个人,一个是Phong,一个是Lambert,前者推导出了理想漫反射表面对入射光所遵从的物理模型,后者提出了一个渲染物体表面高光质感的视觉近似模型。这里我们要提前做一些符号约定:规定所有的单位向量均由物体表面内部指向外部,由光线击中处O向光源引出的单位向量记为L,O向视线引出的单位向量为E,O向镜面反射方向的方向引出单位向量,记为R,由O出发指向外侧垂直于O所在表面的单位向量为N,即法线。
Phong的模型:Phong给出了漫反射表面遵从的物理模型公式,即设漫反射光线强度为I(介于0与1之间),则I正比于E与L之间所成角的余弦值,由于均为单位向量,则
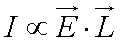
实际中对比例系数再次进行定义以便更好描述物体表面属性,增加Kd与Id,这里的d为diffuse的缩写,Kd即为漫反射表面自身对光线的反射程度,1表示所有的光不吸收,全部进行漫反射,0则吸收所有入射光,对外呈现纯黑色,Id则为入射光强度,也是介于0~1之间,则
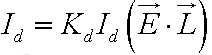
Lambert模型:Lambert解决了物体表面的高光反射的问题,给出了视觉近似公式,随物体表面粗糙程度的不同,入射光线的所有可能的出射方向由理想镜面反射方向到理想漫反射方向之间过渡,Lambert近似给出在过渡过程中的视觉变化,其公式为
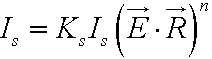
位于指数次幂的n代表了物体的光滑程度,n越大,则物体表面越光滑,相当于视向量E对于镜面反射向量R越敏感。
为了更好的描述物体表面,将这两项相加即可,I=Id+Is,所表现的物体表面既有高光反射质感,不进行高光反射的地方可以利用漫反射公式对其进行着色。
以上所述的两种着色方式是局部光照模型的典型代表,这里的“局部”含义即为:物体表面的亮与暗仅与着色处的一些参量有关,而与场景中其它物体的反射,遮挡等等其它因素均无关,当对下图所示情况进行着色时,局部光照模型无法给出图示处的阴影现象。
光在场景中的传输过程的本质是很简单的,折射(透射),反射,吸收。其中的反射又可分为漫反射,高光反射与镜面反射,这三种反射是由于物体表面光滑程度的不同而来的。但是,由于现实生活中场景的复杂程度变化多样,这就造成了一些常见的现象:溢色与焦散现象,溢色即如下左图所示(图片来源于网络):红色的物体反射的光线射向墙面使得白色的墙面染上了红色,如同颜色“溢出”到其它物体一样。焦散现象如下右图(图片来源于网络),本质是透射物体对光线的汇聚与分散作用。


而上述现象对于传统的局部光照模型来讲是无法实现的,全局光照模型则是为了解决上述问题和出于真实感渲染的目的应运而生的,全局光照模型考虑的是光线在场景中如何传输并与场景中的物体进行物理拟真交互的问题,从而得到一张真实度很高的渲染成品,常见的一些全局光照的手段有:基于光子贴图(Photon Mapping)的方法,基于路径跟踪(Path Tracing)的方法,这两种方法,前者从光源处发射光子,并记录光子在场景中传输所产生的记录,后者则是从视线出发对场景进行采样,可以说这两种方法的思路是相反的,但对于表现真实感的场景,都是很好的算法,而且已经应用了很长时间。
2)GPU并行运算在图形渲染的应用:
GPU的概念最初是由NVIDIA提出的,也就是我们所说的“显卡”,现在的显卡已经由一个传统的游戏设备,逐渐往通用计算领域发展。对于传统游戏设备,现代的GPU能够通过像OpenGL和Direct3D这种即时图形API在屏幕上呈现出即时影像,CPU通过这些API,经由底层驱动给GPU发送绘图数据和绘图指令等等。而对于通用计算领域,CPU则可以通过像CUDA,OpenCL这类API给GPU发送计算指令,计算得到的数据传回CPU进行后续处理。CUDA是NV的,而OpenCL则是一个开放的标准,AMD,Intel,Apple都支持这个标准,目的是利用上任何一个能够参与计算的设备,通用性比CUDA强,但是其效率没有CUDA高。上述的两种全局光照算法均可以在GPU上得以实现,且实现的效率能够超过GPU约两个数量级,这归功于GPU的并行设计理念。而且随着GPU硬件的不断发展,GPU的一些硬件优势也得以体现,如今的GPU的双精度浮点运算能力都要比CPU快很多倍,单精度则更快,同时GPU的显存是没有分页机制的,内部带宽也很高,因此访存延迟要比CPU少很多。这就是在某些场合下,为什么GPU的速度能够远超CPU的原因。
标签:传统 cpu 目的 标准 而且 如何 来讲 屏幕 amber
原文地址:http://www.cnblogs.com/time-flow1024/p/6943508.html