标签:bloom term 红黑树 .com 带来 压缩 访问 提高 使用方法
关于LSM Tree的介绍,这篇文章http://www.benstopford.com/2015/02/14/log-structured-merge-trees/讲得非常具体。
由于磁盘的顺序IO比随机IO效率高得多,为了提高写的吞吐量,有以下几个方法:termed logging,journalling, a heap file
这种情况下,读操作会比写操作花费更多时间(需要反向扫描,直至找到key)。
基于log/journal的方法只适用于简单场景,如数据被整体访问(大部分数据库的预写日志,WAL, write-ahead logging),或通过已知偏移量访问,如简单的消息系统kafka。
对于复杂场景,如基于key或随机访问,有四种方式:
1. Searched sorted file:将数据存入文件,用key排序,若数据定义了长度,则使用binary search,否则使用page index + scan
2. Hash:将数据hash到桶,之后直接读取
3. B+:使用可导航的文件组织,如B+树,ISAM等
4. 外部文件:将数据存为log/heap,使用额外的hash或tree索引至数据
以上四种方式大大提升了读性能(大部分情况下O(lgn)),但也牺牲了写性能(由于增加了排序)。
此时,有以下问题:
1. 每次写操作有两次IO,一次是读页面,一次是写回该页面,而log法只需要一次IO
2. 若要更新hash或B+索引结构,则需更新文件系统的特定部分,而这种原地更新需要缓慢的随机IO
一个常见的解决方法是使用方法4,为journal构建index,并将index至于内存。于是Log Structured Merge Trees(LSM Tree)应运而生。
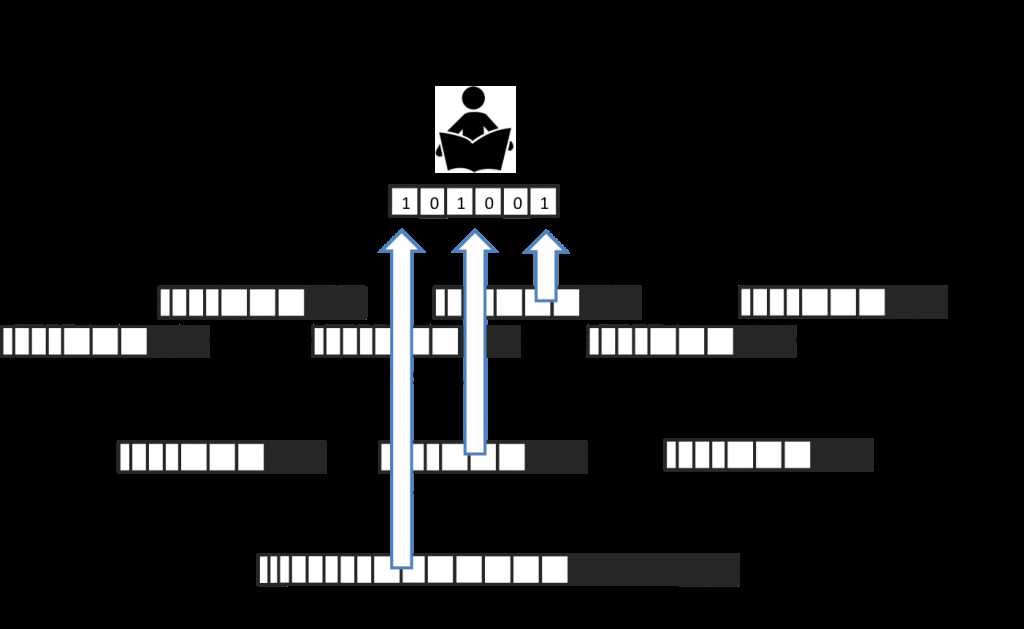
LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端情况下,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。
具体工作原理为:当一个更新请求到达时,将会被加入内存缓存区(一般情况下是一棵树,如红黑树,B树等,来保存key的有序性)。这个memtable会作为write-ahead-log复制于磁盘中,以便出现问题时的修复。当memtable区满时,将会flush到磁盘中作为一个新的文件。这个过程会随着写入的增多而不断重复。
由于旧文件不会被更新,重复的entry会被创建来取代之前的记录(或者移除的标记),这会带来一些冗余。系统会定期进行压缩操作,压缩的做法是选择多个文件,将他们进行合并,并移除重复的更新或者删除操作。这对消除冗余和提高读性能(由于读性能会随着文件数增加而递减)非常重要。此外,由于每个文件都是有序的,所以合并文件的操作也非常高效。
当读操作到达时,系统会先检查memtable,如果没有找到对应的key,则在磁盘文件中以逆时间顺序进行查找,直至找到key。每个文件都是有序的,不过读操作仍然会因为文件数目的增长而变慢。为了解决这个问题,有一些小trick。其中最常见的方法是在内存中保持一个page-index,以便使你更接近目标key。LevelDB,RocksDB和BigTable在每个文件的保存了一个block-index。这会比直接进行二分查找更高效,因为它允许使用可变长度,更适用于压缩数据。
哪怕使用紧凑的读操作,文件访问次数依然很多。大部分实现通过使用Bloomfilter来进行改进。Bloom filters是一种判断文件中是否包含某个key的内存高效方法。
总的来说,LSM Tree是在随机写IO和随机读IO之间进行trade off。如果可以使用软件方法(如Bloom filters)或硬件方法(如大文件缓存)来优化读性能,那么这个trade off是一个明智的选择。
基本compaction
根据特定size限制进行compaction,譬如5个文件,每个文件有10行,会被合并为一个有50行(或者比50行小一些)的文件。而5个50行的文件又会被合并为一个具有250行的文件,以此类推。
这种方法的问题是:会创建大量的文件,所有文件都需要被分别搜索以读取结果。
分层compaction
新的实现方法,如LevelDB,RocksDB和Cassandra等,通过level-based而不是size-based进行compaction以解决上述问题。这种level-based方法主要有以下两点不同:
1. 每一层可以包含一系列文件,并且保证不会有重叠的key。这意味着key在所有可用文件中被切分。所以在特定层寻找一个key只需要读取一个文件。(要注意的是,第一层比较特殊,相同keys可以在多个文件中)
2. 多个文件会一次合并至上层的一个文件中。当一层填满时,会从该层取出一个文件,合并至上层以创建空间使更多的数据可以被加入。
这种改动意味着level-based解决方案随着时间推移进行压缩并且需要的空间更少。此外,它的读性能也更好。
标签:bloom term 红黑树 .com 带来 压缩 访问 提高 使用方法
原文地址:http://www.cnblogs.com/shinning/p/6944094.html