标签:例子 集群 改变 分享 image 时间 如何 成本 tps
采取什么办法可以让一个Web服务可大规模可扩展?相信你会对这个问题感兴趣。
通常来说,公共服务器上的一个可伸缩的web服务总是隐藏在一个Load Balancer(负载均衡器)之后。这个负载均衡器会将负载(来自用户的请求)均匀的分配到一组服务器或者服务器集群。那意味着什么?举个例子:某个用户访问你的服务,他第一次的请求可能会由第二台服务器提供,第二次请求由第9台服务器提供,第3次请求又再次由第二台服务器提供。
对于该用户而言,他每次得到的结果应该是一样的,不依赖服务到底是哪台服务器提供的。这个正是可伸缩性的第一个黄金法则:每个服务器都包含完全相同的代码库,不在本地磁盘或内存存储任何与用户相关的数据,如session或用户信息。Session需要集中存储,使得每一台服务器都可以访问到它。它可以是一个外部数据库或外部持久缓存,比如Redis。相比外部数据库,在持久化的缓存中存放session将会有更好的性能。这里提到的“外部”指的是数据存储不放置在这些应用服务器上,而是在接近您的应用程序服务器的数据中心。
但是这要怎么部署呢?你如何确定当应用代码发生了改变能够发送到所有的服务器而没有一台服务器依旧使用之前的代码?幸运的是,这个棘手的问题已经被一个很好的工具capistrano解决了,你需要稍微学习了解下。
在解决了session和多台服务器上新版本的同步更新问题之后,你需要做的就是克隆你的机器镜像了,然后将你最新的代码部署上去。可以参考Amazon提供的AMI服务(Amazon Machine Image)
现在你的服务器可以水平扩展,并且处理成千上万的并发请求了。
但是你发现应用程序变得越来越来最终崩溃。问题的原因:是MySql,不是吗?
现在不是增加更多的机器可以解决的问题了,你有两种办法:
现在,你的数据库有了一个可扩展的解决方案了,你再也不用担心存储TB级的数据,世界看起来那么的美好。
当大量的数据请求发往到数据库,你发现又变慢了,解决办法是增加缓存。
这里说的缓存指的是内存缓存,比如常见的内存数据库Memcached或者Redis ,千万不要使用文件缓存,它会让你服务器的克隆和自动伸缩很痛苦。
但是回到内存缓存,缓存是一个简单的键值存储并且应该介于应用程序和数据存储。任何时候当你的应用程序需要去读取数据时,它首先应该尝试从缓存里面获取数据,只有无法从缓存中读取数据时,才会尝试从数据库中读到。为什么要这么做呢?因为缓存快如闪电,它将数据集存放在内存中,并且可以快速的被处理。举个例子:Redis没秒钟可以处理成千上万的读操作。
访问流程:第一次访问绿色,第二次和之后的蓝色: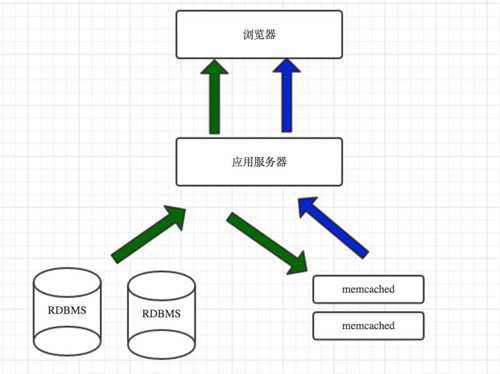
有两种缓存数据的模式,一种是老的方式,一种是新的方式:
一些适合缓存的对象:
请想象一下,你想在你最喜欢的面包店买面包,所以你走进面包店,向一个店员询问购买面包,但是面包都卖光了。你被告知2个小时之后你订的面包可以好,这个很恼人,不是吗?
为了避免这种“请等片刻”的场景,需要采取异步。比如什么时候有面包了,店员会将面包派送给你的家里。通常来说,有两种异步的范例:
如果你做一些耗时的操作,试着采用异步。
标签:例子 集群 改变 分享 image 时间 如何 成本 tps
原文地址:http://www.cnblogs.com/yechanglv/p/6947190.html