标签:ram str details 问题 部分 from ack track size
欢迎转载。转载注明出处:
http://blog.csdn.net/neighborhoodguo/article/details/47193885
近期几课的内容不是非常难。还有我的理解能力有所提高(自恋一下)。所以这几课完毕的都挺快。不知不觉lec9也完毕了。这一讲讲了还有一个RNN,当中R是Recursive不是之前的Recurrent。
课上老师使用Recursive NN来做NLP和CV的任务,我个人觉得做CV还是不错的。这个NLP怎么感觉有点不靠谱。无论怎么说这个model还是攻克了非常多实际问题的。并且性能也不错,如今就来记录记录喽。
首先来梳理一下这一课讲得内容吧。首先讲了怎样把一个sentence进行vector表示,再是怎样进行parsing,然后是构建object function的方法max-margin以及BPTS(Backpropagation Through Structure)。最后是Recursive NN的几个改良版还有这个model也能够进行computer vision的工作。
类似上一阶段的word vector space这次我们是将一整个sentence投影到semantic vector spaces中。
我们的模型是基于这样两个如果:一个句子的意思是基于1.这个句子所包括单词的意思;2.这个句子的构建方式。当中第二点还在争论中,我们这一讲讨论的模型能够同一时候完毕两个任务,第一能够学出来这个句子的tree模型,第二能够学出来这个句子在semantic vector space里的表示。
Parsing tree是什么呢?上图:
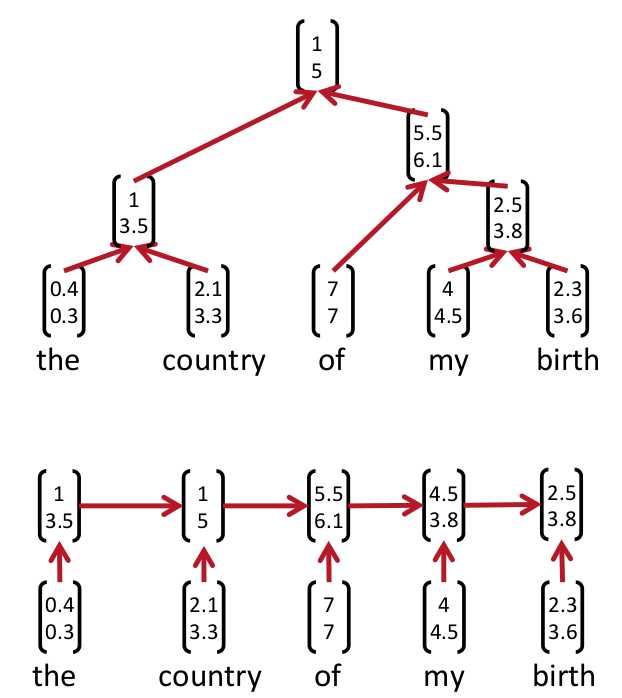
当中上面那个图就是在这一讲里所述的parsing tree。而上一讲的recurrent neural networks事实上类似以下的parsing tree它被视作是上一种parsing tree的特殊表示方式。
这两种表示方法究竟哪个正确如今还没有定论(still cognitively debatable)
如何学出来这个parsing tree呢?聪明的人类发明了一个方法叫beam search就是bottom-up的方法。从最低下開始,计算哪两个成为好基友的score最大,然后取出来最大的score的俩个node然后他俩就merge了(好邪恶)。最后一直到最上面所有都merge起来了就形成了一个parsing tree。
slide里的objection function我之后參阅了recommand reading里的object function发现不一样正负号是反的。
我推測是不是老师写得时候给写反了??
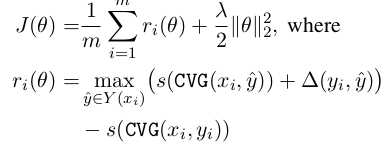
论文里给出的object function是这种。当中delta(yi, y_hat)是依据标记错误的node数量再乘以一个k得出的:
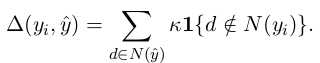
score有两个部分:
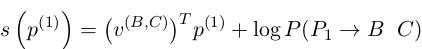
前半段的v是要通过我们的model学习出来的,后半段是log probability of the PCFG也就是这玩意发生的概率并转成log space下。
课上讲得max-margin不太具体。第二篇论文里面讲得挺好。这里摘抄出来:
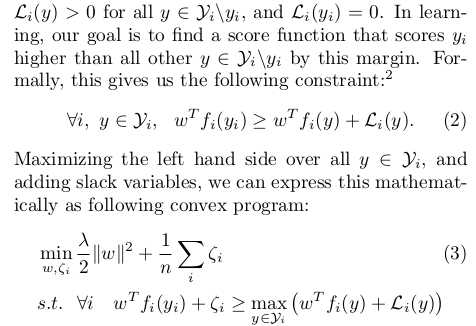

最后得到max-margin的公式。我们的目的是使得c(w)最小
这样为什么就是最优的呢,我想了半天才想出来这里用通俗点的话记录一下:假设w不是最优的w那么max()里左边的score选出来的不是y_i,再加上L_i那么终于肯定是ri非常大,必定不是最小的。假设w是最优的呢?那肯定max()选出来的是yi。delta肯定为零。然后整体必定最小。这种w必定使得score(y_i)比其它全部的score(y)大,而且大出来一个L_i(y)的margin。
BPTS论文里讲得比較少。slide里讲得还挺具体还有pset2的部分代码还是不错滴。
BPTS和之前的传统BP有三个差别:

第一点是说求w的gradient要sum全部node的;第二点我感觉是用来更新semantic vector space里的vector的。第三点还要加一个error message:Total error messages = error messages from parent + error message from own score
BPTS的parameters更新的改进方法能够调整learning rate或者使用subgradient(使用subgradient的方法论文里有讲,cs229里也有将一个smo方法比較类似)
前半段讲得都是最简单的simple RNN。
最后讲了一个改良版的SU-RNN(syntactically-untied RNN)
也就是weight依据children的type的不同而进行不同的选择。
最后有一个CV的展示,就是说RNN对于NLP的操作和CV差点儿相同都是一步一步分解。
Website:
nlp.stanford.edu
http://repository.cmu.edu/robotics
www.socher.org
标签:ram str details 问题 部分 from ack track size
原文地址:http://www.cnblogs.com/gccbuaa/p/6950956.html