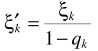标签:hone 介绍 diffuse pos blank ase logs one and
作者:桂。
时间:2017-06-06 16:10:47
链接:http://www.cnblogs.com/xingshansi/p/6951494.html
原文链接:http://pan.baidu.com/s/1i51Kymp
未完待续
前言
这篇文章是TF-GSC的改进版。虽然TF-GSC对于方向性干扰的抑制效果不错,对于弥散噪声(diffuse noise,题外话:不同方向directional noise的均值,或者接近这种效果,可以理解为diffuse noise.)TF-GSC性能下降明显,如果diffuse noise还是non-stationary,性能下降就更严重了。本文的思路是在TF-GSC的基础上,引入postfiltering(后置滤波),文中提到了三种方法:两种基于single channel-1)mixture maximum;2)OMLSA;但如果噪声both diffused and nonstationary,基于single channel的方法不再适用,这时候方法3仍然有效:a new multimicrophone postfilter method。
本文主要梳理基于TF-GSC的multimicrophone postfilter method,因为基于single channel的两种方法都是单独使用,后面有时间另写文章整理。
一、OMLSA思想
A-利用不存在概率的增强
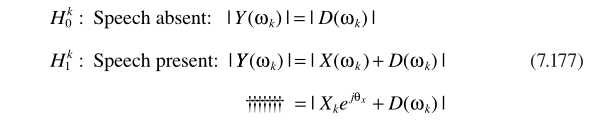
容易推理基于MMSE准则的估计器
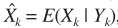
如果考虑语音存在概率,则估计器扩展为
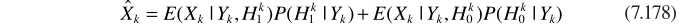
理论上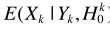 的值为0,上式简化为
的值为0,上式简化为
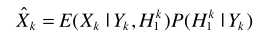
B-语音不存在概率与最大似然准则估计器ML 结合
例如在语音增强一文中介绍的,基于最大似然准则的估计器为
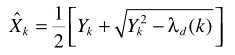
从Y的概率密度形式
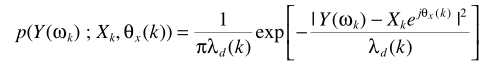
易知ML是基于语音存在的假设,结合语音存在概率,则基于ML准则的估计器为
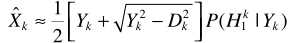
对于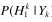 )的计算可以利用贝叶斯准则
)的计算可以利用贝叶斯准则
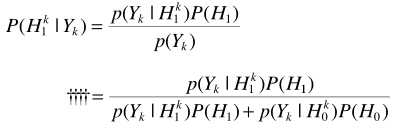
这里利用一个假设(也就是约束条件):噪声服从均值为0,方差相同的复高斯分布。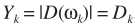 ,此时容易证明噪声幅度服从瑞利分布(相位为均匀分布,且二者独立),
,此时容易证明噪声幅度服从瑞利分布(相位为均匀分布,且二者独立),
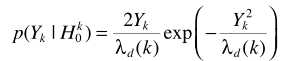
H1假设下,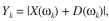 此时
此时
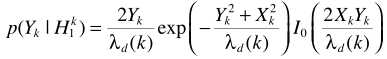
关于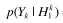 的计算参考语音增强一文的最大似然估计。例如假设语音存在/不存在是等可能的,
的计算参考语音增强一文的最大似然估计。例如假设语音存在/不存在是等可能的,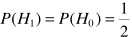 ,此时完成了的估计:
,此时完成了的估计:
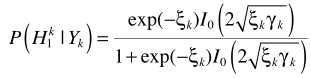
其中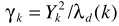 是a posteriori SNR,
是a posteriori SNR,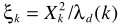 是a priori SNR。这个就是一般意义的参数估计了,在语音增强一文也给出了两个实现思路:1)Maximum-Likelihood Method;2)Decision-Directed Approach.至此也就完成了结合不存在概率的语音增强。
是a priori SNR。这个就是一般意义的参数估计了,在语音增强一文也给出了两个实现思路:1)Maximum-Likelihood Method;2)Decision-Directed Approach.至此也就完成了结合不存在概率的语音增强。
C-语音不存在概率与最小均方误差估计器MMSE 结合
其实基本思路都是一样的:
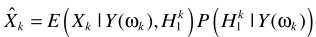
然后是利用贝叶斯进行概率估计
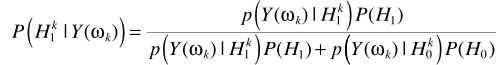
不同点在于这里进行了转化
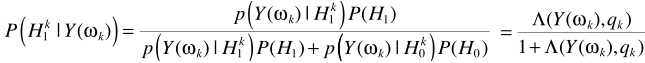
其中
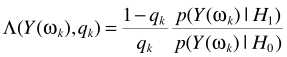
其中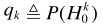 ,denotes the a priori probability of speech absence for frequency bin k.从而
,denotes the a priori probability of speech absence for frequency bin k.从而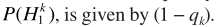
与ML准则不同的是,只有噪声时,是噪声D的分布,而不是其幅度(其实如果是幅度,也有一套方法,感兴趣可以自己推导推导)。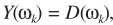 仍是高斯分布
仍是高斯分布
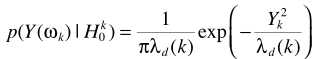
H1时,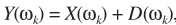 且认为D与X不相关,易得
且认为D与X不相关,易得
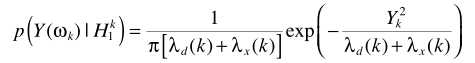
代入上面的估计器,有
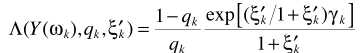
其中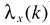 就是
就是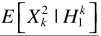 ,则
,则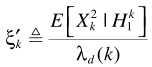 .进一步求解条件概率
.进一步求解条件概率
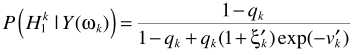
其中
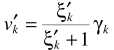
参数估计的细节与ML中的估计思路一致。从而实现信号的增强:
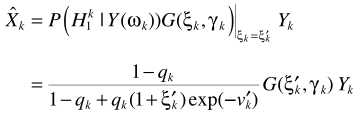
G就是MMSE估计器
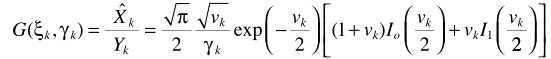
不同之处是里边的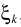 替换成
替换成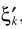 。
。
题外话:看看之前的参数估计与此处参数估计的联系
即
不得不佩服,这些理论的研究者真有一套。
D-语音不存在概率与对数最小均方误差估计器Log-MMSE 结合(OMLSA)
原理与其他方法一致
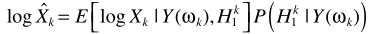
X的估计器
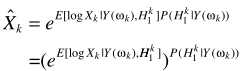
可以进一步写为
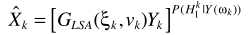
其中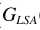 就是语音增强一文中的对数MMSE估计器。这里要有一点不同了,这里的概率是指数形式,有学者研究这样的增强效果并不比直接LSA更好,所以对其变形
就是语音增强一文中的对数MMSE估计器。这里要有一点不同了,这里的概率是指数形式,有学者研究这样的增强效果并不比直接LSA更好,所以对其变形
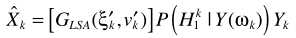
还是与其他方法类似:概率相乘的形式。这里的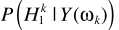 与MMSE中的一致。至此完成了LSA与语音不存在概率的结合。但这套理论比较粗糙,一些学者(原文见这里,P262)提出了不同的角度:只有噪声时,不再认为严格为0,而是接近0:
与MMSE中的一致。至此完成了LSA与语音不存在概率的结合。但这套理论比较粗糙,一些学者(原文见这里,P262)提出了不同的角度:只有噪声时,不再认为严格为0,而是接近0:
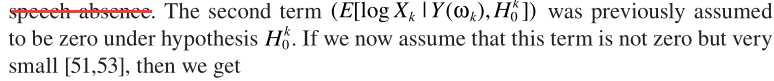
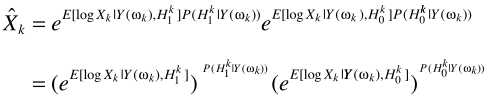
其中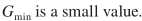 ,第一项
,第一项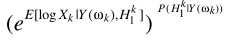 就是最开始的LSA与语音存在概率的原始结合,这就是optimally modified log-spectrum amplitude (OMLSA) estimator ,即
就是最开始的LSA与语音存在概率的原始结合,这就是optimally modified log-spectrum amplitude (OMLSA) estimator ,即
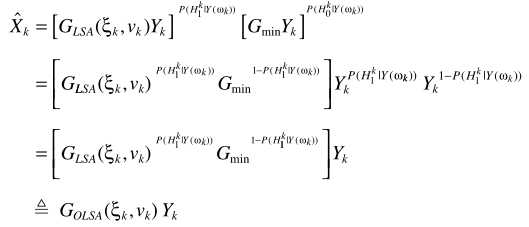
参数估计的改进(此处没写完,待补充):
Implementation Issues Regarding A Priori Snr Estimation
Methods For Estimating The A Priori Probability Of Speech Absence
二、论文理论框架
麦克风接收的信号
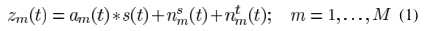
其中m代表第m个麦克,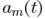 是TF的时域形式(acoustical transfer function,ATF),
是TF的时域形式(acoustical transfer function,ATF),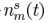 对应the stationary noise component,即稳态噪声,
对应the stationary noise component,即稳态噪声,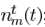 对应the transient noise component,即瞬态噪声。对应频域变换
对应the transient noise component,即瞬态噪声。对应频域变换
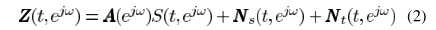
其中
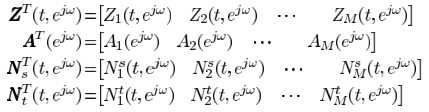
TF-GSC框架前文已经梳理,这里主要分析 the multimicrophone postfiltering:
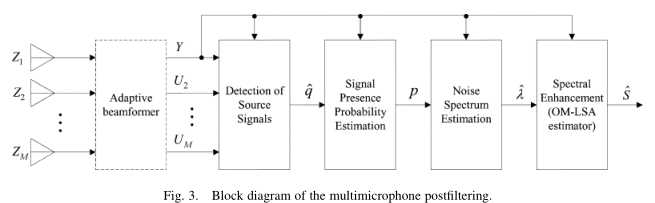
假设TF-GSC处理之后的信号为Y,则后处理操作
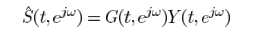
其中
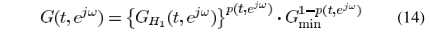
[找时间再补充,明天要开会,就此打住,休息]
参考
【论文:麦克风阵列增强】Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
标签:hone 介绍 diffuse pos blank ase logs one and
原文地址:http://www.cnblogs.com/xingshansi/p/6951494.html