标签:学习 ural 平滑 单位 去除 tput 等于 分类器 value
本讲内容
1. Naive Bayes(朴素贝叶斯)
2.Event models(朴素贝叶斯的事件模型)
3.Neural network (神经网络)
4.Support vector machines(支持向量机)
1.朴素贝叶斯
上讲中的垃圾邮件问题有几个需要注意的地方:
(1) 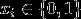 一个单词只有出现和不出现两种可能,因此每个特征x只有两个取值
一个单词只有出现和不出现两种可能,因此每个特征x只有两个取值
(2) 特征向量x的个数应该等于词典的长度,比如 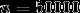
将该算法一般化:
(1) 让 可以取更多的值
可以取更多的值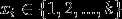
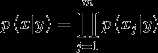
此时 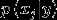 服从多项式分布,而不再是伯努利分布。一种常见的例子是当x的取值是连续值,而需要将其离散化为有限的几个值。
服从多项式分布,而不再是伯努利分布。一种常见的例子是当x的取值是连续值,而需要将其离散化为有限的几个值。
(2) 对序列进行分类的变化形式
给之前邮件例子中采用的模型起个名字:多元伯努利事件模型 (意思是其中存在很多个伯努利随机变量)
接下来要讲另一种事件模型:多项式事件模型
给定一封邮件,我需要得到这封邮件的一个特征向量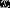 和它的标签
和它的标签 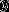
对于多项式事件模型,我们按照如下规则对一封邮件建立特征向量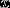 :
:
对于一封含有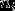 个单词的邮件
个单词的邮件
特征向量表示为
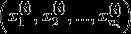
其中的每个元素 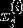 的值为词典中该单词的索引。
的值为词典中该单词的索引。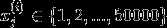
这种情况下我们的生成模型为

这里的n是指邮件的长度,而不是词典的长度。
该模型的参数包括
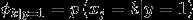
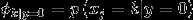
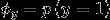
作极大似然估计 ,得到参数最优值为
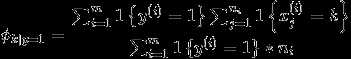
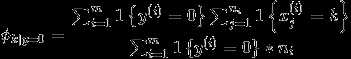
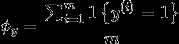
应用laplace平滑,分子+1,分母+50000.
通常情况下对于一个文本分类问题,使用多项式事件模型取得的分类效果几乎总是会比使用多元伯努利事件模型取得的效果要好。一个好的解释是,
多项式事件模型考虑了一个文档中单词出现的次数,而多元伯努利事件模型没有考虑。
非线性分类器
上一讲中说过,当满足 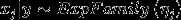 先验假设时,基于此得到的生成模型满足logistic后验分布,应用logistic回归的分类器属于线性分类器。因此使用朴素贝叶斯得到的分类器也是线性分类器。神经网络和支持向量机都属于非线性分类器。
先验假设时,基于此得到的生成模型满足logistic后验分布,应用logistic回归的分类器属于线性分类器。因此使用朴素贝叶斯得到的分类器也是线性分类器。神经网络和支持向量机都属于非线性分类器。
3.神经网络
略。
4.支持向量机
当我们使用logistic回归拟合分类器时,我们认定一个良好的分类器具有以下的特征:
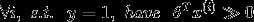
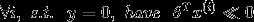
先假设我们的训练集合是线性可分的,稍后会去除这个假设。
为了描述支持向量机的简便性,对符号进行改动如下:
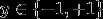
have h output values in 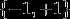
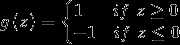
扔掉
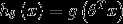
替换为
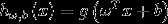
其中
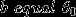

函数间隔和几何间隔
函数间隔定义:
一个超平面(w,b) 和某个特定的训练样本 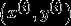 之间的函数间隔为
之间的函数间隔为
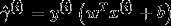
对上式的一种直观理解(需求)是,为了使函数间隔尽可能大:
如果 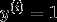 ,则希望
,则希望 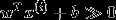
如果 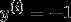 ,则希望
,则希望 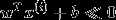
如果 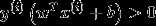 则证明我们的分类结果是正确的。
则证明我们的分类结果是正确的。
一个超平面和整个训练集合的函数间隔定义为

因此需求变为,为了使最坏情况下的函数间隔尽可能大
这种理解(需求)有一个很严重的问题:
假设我们的w,b都已经满足分类任务的要求,那么此时我将w替换为2w,b替换为2b。那么函数间隔
会变为原来的两倍,因此单纯的以最大化函数间隔为目标是没有意义的。所以我们需要对函数间隔添加一个正则化的约束,例如  。
。
几何间隔定义:
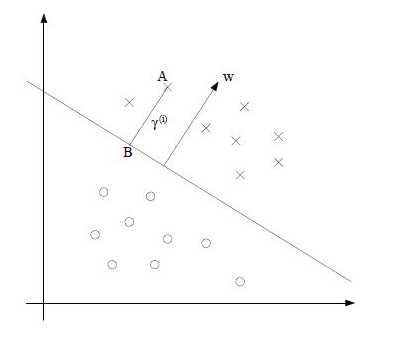
超平面(w,b)和某个特定的训练样本 之间的几何间隔为:
训练样本 和由超平面(w,b)确定的分隔线之间的几何间距。
定义在高维空间中超平面(w,b)的单位向量为 
考虑训练样本A,它到分隔线的距离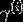 ,也即线段AB的长度。B点可以表示为
,也即线段AB的长度。B点可以表示为
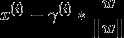
B点在超平面上,对于一个分类超平面来说,超平面上的所有点x满足
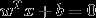
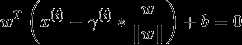
解得
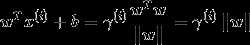

上式已经假设分类正确
几何间隔更为一般的形式为
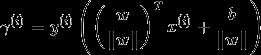
如果||w||=1 那么函数间隔等于几何间隔
更一般地,
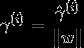
一个超平面和整个训练集合之间的几何间隔定义为

最大间隔分类器
支持向量机的前身。它是一个学习算法,选择特定的w和b,使得几何间隔最大化。
第六讲完。
标签:学习 ural 平滑 单位 去除 tput 等于 分类器 value
原文地址:http://www.cnblogs.com/madrabbit/p/6947014.html