标签:说话 encoder com state ati text size mil max
在此前的两篇博客中所介绍的两个论文,分别介绍了encoder-decoder框架以及引入attention之后在Image Caption任务上的应用。
这篇博客所介绍的文章所考虑的是生成caption时的与视觉信息无关的词的问题,如“the”、“of”这些词其实和图片内容是没什么关系的;而且,有些貌似需要视觉特征来生成的词,其实也可以直接通过语言模型来预测出来,例如“taking on a cell”后生成“phone”。
所以作者设计了一个自适应注意力机制,使得模型在生成每个词时,可以决定模型需要关注图像还是只需要依靠语言模型;如果需要关注图像,再通过spatial attention来决定关注图像的哪个区域。中间那一行的概率值越大,就表明越需要图像特征。
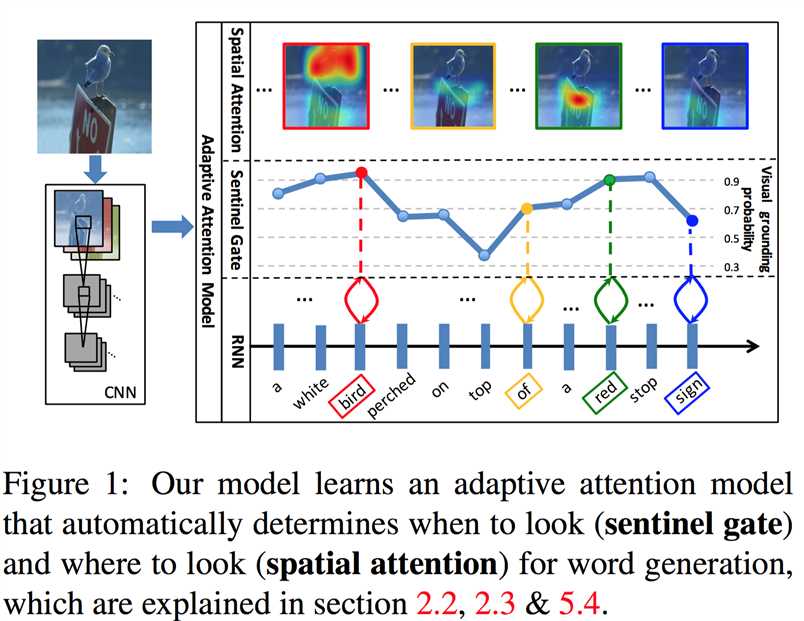
Adaptive Attention 论文阅读笔记
[1] Knowing When to Look - Adaptive Attention via A Visual Sentinel for Image Captioning
这篇文章主要的idea是解码器在生成一个词时,图像特征有时候并不需要,单纯依靠语言模型就可以predict一个很合适的词。
1. encoder-decoder框架
下面还是不厌其烦地过一遍encoder-decoder框架,主要是为了为全文统一记号……
给定训练集的图像 I 和对应的描述句子 $y=\{y_1,...,y_t\}$ ,模型的训练目标是最大化似然
$$\theta^*=\arg\max_{\theta}\sum_{(I,y)}\log p(y|I;\theta)$$
(1)encoder:CNN
CNN来提取图像特征早已经成为了标配。本文的模型使用ResNet提取 k 个区域的特征
$$A = \{\textbf a_1,...,\textbf a_k\},\quad \textbf a_i\in\mathbb R^{1024}$$
然后得到全局(global)图像特征
$$\textbf a^g=\frac1k\sum_i\textbf a_i$$
使用ReLU激活函数,将图像特征变换为 d 维向量
$$\textbf v_i=\text{ReLU}(W_a\textbf a_i)$$
$$\textbf v^g=\text{ReLU}(W_b\textbf a^g)$$
最后就可以得到
$$V=[\textbf v_1,...,\textbf v_k]\in\mathbb R^{d\times k},\quad\textbf v_i\in\mathbb R^d$$
(2)decoder:LSTM
将句子的概率拆解(省略了模型参数的依赖)
$$\log p(y|I)=\sum_{t=1}^T\log p(y_t|y_1,...,y_{t-1},I)$$
建模在 t 时刻生成词 $y_t$ 的条件概率,通常情况下都是选择RNN:
$$\log p(y_t|y_1,...,y_{t-1},I)=f(\textbf h_t,\textbf c_t)$$
f 是非线性函数,$\textbf h_t$ 是当前时刻的隐状态;$\textbf c_t$ 是当前时刻输入到decoder的视觉上下文向量:如果不使用attention机制时,它就是encoder计算出的编码向量,与时间 t 无关;如果使用attention机制,则是由attention机制计算出来(也就是上一篇博客的 $\textbf z_t$ ,由encoder的编码向量和decoder在上一时刻的隐状态共同决定)。
隐状态通过LSTM建模:
$$\textbf h_t=\text{LSTM}(\textbf x_t,\textbf h_{t-1},\textbf m_{t-1})\in\mathbb R^d$$
其中 $x_t=[\textbf w_t;\textbf v^g]$ 是输入信息,这里使用的是上一时刻生成的词的词向量 $\textbf w_t$ 和图像特征 $\textbf v^g$ 的拼接(concatenate),$\textbf m_{t-1}$ 是上一时刻的细胞状态。
到这里还没介绍函数 f 究竟是什么,就是普通的Softmax?不急,下面介绍attention时再说。
2. spatial attention机制
抛开具体任务,概括地说attention机制在seq2seq中的作用的话,其目的就是得到一个与时刻 t 相关的向量(用来取代encoder的与时刻无关的编码向量)来输入给decoder,这个向量需要反映出在解码器在时刻 t 生成一个词时对输入序列的不同部分(这里就是不同的图像区域)的关注程度的差别。用一个函数 $f_{\text{att}}$ 来表示attention机制耦合两方面信息的方式,然后就可以用Softmax得到这 k 个区域在时刻 t 被分配的权重:
$$\textbf z_t=f_{\text{att}}(V,\textbf h_t)$$
$$\boldsymbol\alpha_t=\text{softmax}(\textbf z_t)=[\alpha_{t1},...,\alpha_{tk}]$$
文本的模型中,$f_{\text{att}}$ 使用的形式是 $\textbf w_h^{\top}\tanh(W_vV+W_g\textbf h_t\textbf 1^{\top})$ 。有了权重,就可以计算出视觉上下文向量 $\textbf c_t$ :
$$\textbf c_t=\sum_{i=1}^k\alpha_{ti}\textbf v_i$$
看到这基本上可以感觉到,这个attention机制和上篇博客介绍的那篇论文里的soft attention很像,但是有细微的差别,比如这里用的隐状态是当前时刻 t 的而不是上一个时刻的。作者画了个图示意了两个机制的区别:
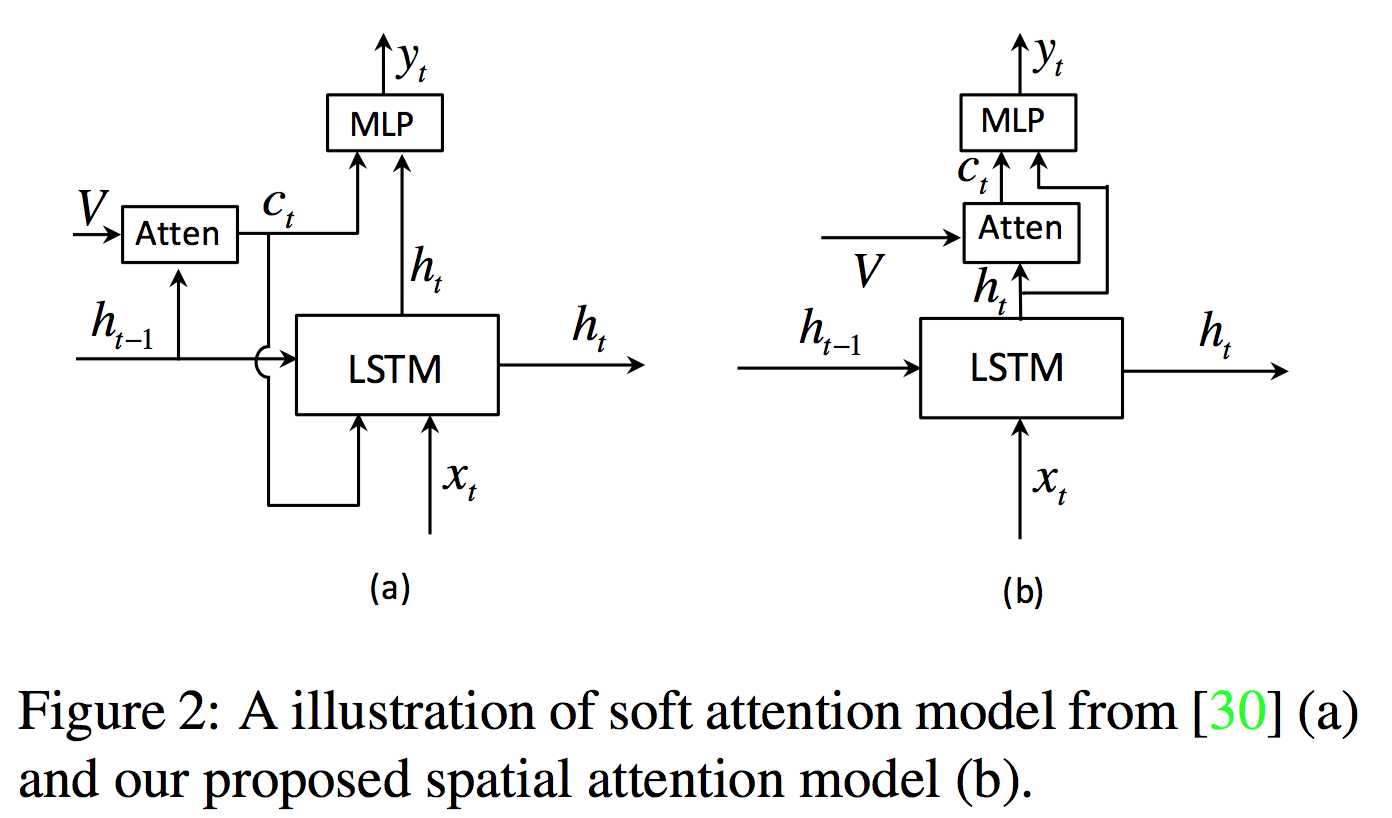
作者解释道,使用当前时刻的隐状态这一idea来自于ResNet的启发。作者将 $\textbf c_t$ 视作当前时刻隐状态 $h_t$ 的残差信息,其起到的作用是削减生成词时的不确定性,为 $\textbf h_t$ 补充信息。用当前时刻隐状态而不用上一时刻的这种套路
3. Adaptive Attention机制
(1)decoder已知信息 vs. attention得到的视觉上下文信息
下面就是本文的核心,自适应注意力机制。之前提到,本文的关注点就在于decoder所生成的那些与图片无关的词(如介词),或者貌似有关、但是可以直接用语言模型预测出来的词。直接用attention机制的话,是无法确定什么时候可以不依赖图像信息而直接用语言模型来生成一个词的。
作者提出了一个visual sentinel(视觉哨兵)的概念,是decoder已经知道的信息的隐式表示。与此对应地,attention机制所得到的视觉上下文向量 $\textbf c_t$ 可以看作是decoder在当前时刻从图像特征里了解到的“新”信息。
decoder的memory(细胞状态,$\textbf m_t$ )存储了长时和短时的视觉和语言学信息。这篇论文的模型从里面抽取一个新的成分——视觉哨兵 $\textbf s_t$,使得模型能够在不需要图片信息时不再关注图像特征。基于此,作者扩展了LSTM:
$$\textbf g_t=\sigma(W_x\textbf x_t+W_h\textbf h_{t-1})$$
有了门控,就可以对LSTM的细胞单元进行如下计算,抽取出视觉哨兵:
$$\textbf s_t=\textbf g_t\odot \tanh(\textbf m_t)$$
换句话说,普通版本的LSTM使用输出门控 $\textbf o_t$ 从细胞单元提取出了隐状态 $\textbf h_t=\textbf o_t\odot \tanh(\textbf m_t)$ ,这里又提取出了新的成分,也就是视觉哨兵。
那么,如何利用这个视觉哨兵向量呢?要知道,视觉哨兵向量是decoder已经知道的信息的隐式表示,而此前的attention机制所得到的视觉上下文向量 $\textbf c_t$ 可以看作是decoder从图像特征里了解到的信息。接下来就是把两者进行一个trade-off,sentinel gate $\beta_t$ 用来决定是否去关注图像特征的门控。线性加权是无敌的!
$$\hat{\textbf c}_t=\beta_t\textbf s_t+(1-\beta_t)\textbf c_t$$
$\beta_t$ 取值在 0 到 1 之间,当 $\beta_t=1$ 时就表示此时的decoder完全不需要图像信息。作者把 $1-\beta_t$ 称为 visual grounding probability。
(2)trade-off 系数的自适应求解
所谓的“自适应”,大概就是说这个 $\beta_t$ 可以计算出来,而不是手工指定。作者是这样做的:
$$\textbf z_t=f_{\text{att}}(V,\textbf h_t)=\textbf w_h^{\top}\tanh(W_vV+W_g\textbf h_t\textbf 1^{\top})$$
$$\hat z_t=f_{\text{att}}(\textbf s_t,\textbf h_t)=\textbf w_h^{\top}\tanh(W_s\textbf s_t+W_g\textbf h_t)\in\mathbb R$$
$$\hat{\boldsymbol\alpha}_t=\text{softmax}([\textbf z_t;\hat{ z}_t])\in\mathbb R^{k+1}$$
$$\beta_t=[\hat{\boldsymbol\alpha}_t]_{k+1}$$
换句话说,使用向量 $\hat{\boldsymbol\alpha}_t$ 的最后一个元素来作为这个系数,满足取值在 0 到 1 之间。
(3)解码方式
现在,该有的信息都有了,回答一下刚才留的那个问题,也就是LSTM输出了隐状态后,如何计算生成的词。传统的方式就是用Softmax,利用的信息包括隐状态、上一时刻的词向量、attention得到的向量。这里大同小异:
$$\textbf p_t=\text{softmax}(W_p(\hat{\textbf c}_t+\textbf h_t))$$
4. 实验与例子
这里不再介绍实验细节了,回来跑一下这篇文章的代码感受一下。总之就是,纵向比较的话,加入了视觉哨兵的自适应attention机制后效果要好于不加;横向比较的话,在这个论文在2016年11月放到arXiv时(现在已经被2017CVPR接收了),是state-of-the-art的效果。即便现在来看,其在COCO排行榜上的排名也是非常高的。

Multimodal —— 看图说话(Image Caption)任务的论文笔记(三)引入视觉哨兵的自适应attention机制
标签:说话 encoder com state ati text size mil max
原文地址:http://www.cnblogs.com/Determined22/p/6954509.html