标签:文件内容 生成 利用 数据 格式 基本 移动文件 str split
正则表达式:模糊匹配
最常用的匹配语法
1,re.match 从头开始匹配
2,re.search 匹配包含
3,re.findall 把所有匹配到的字符放到以列表中的元素返回
4,re.split 以匹配到的字符当做列表分隔符
5,re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式:
|
1
2
3
|
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)M(MULTILINE): 多行模式,改变‘^‘和‘$‘的行为S(DOTALL): 点任意匹配模式,改变‘.‘的行为 |
日志处理之logging模块
日志级别:
debug 最详细的调试信息 10
info 就想记录一下 20
warning 出现警告 30
error 出现错误 40
crttcal 非常严重 50
从大至小,级别越高,数字越大!
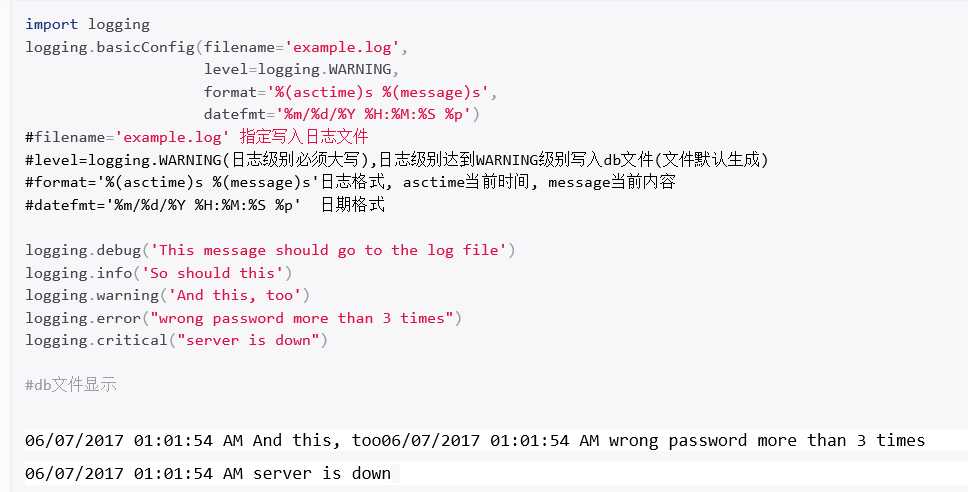
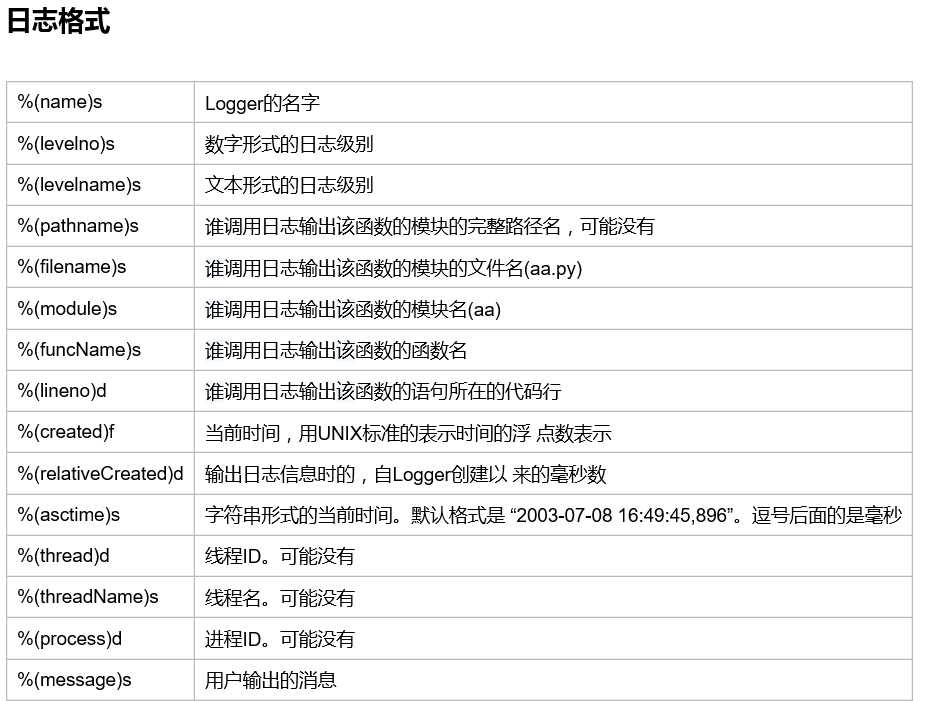
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出(输出到文件内或屏幕)
filter提供了细度设备来决定输出哪条日志记录(日志内容哪些输出,哪些不输出)
formatter决定日志记录的最终输出格式(日志格式)
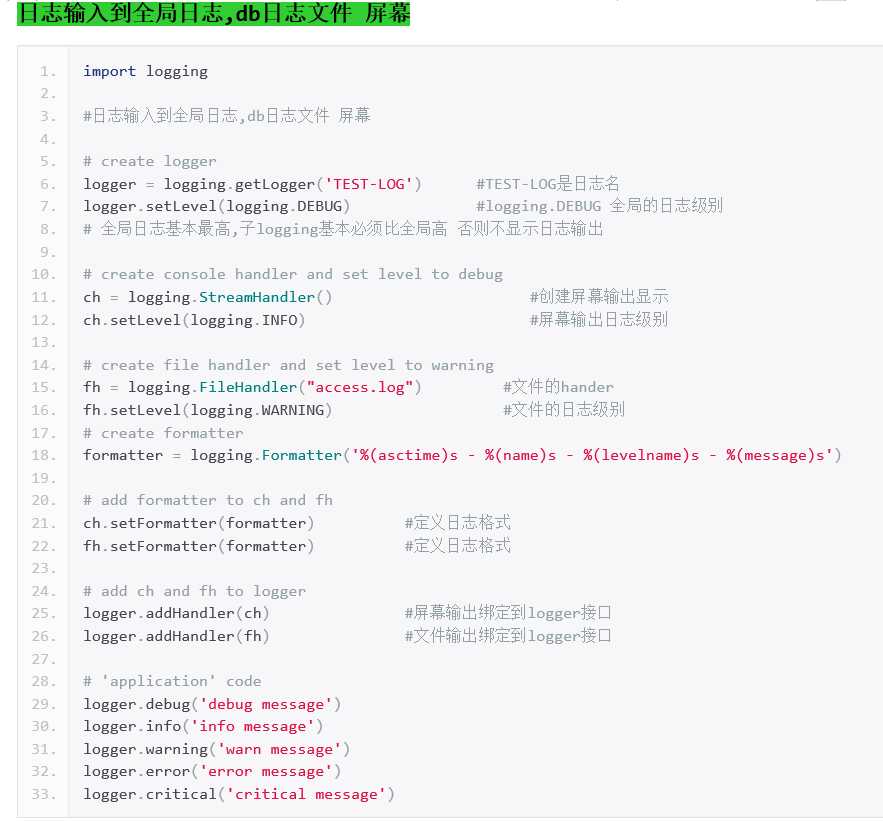
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a‘,即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
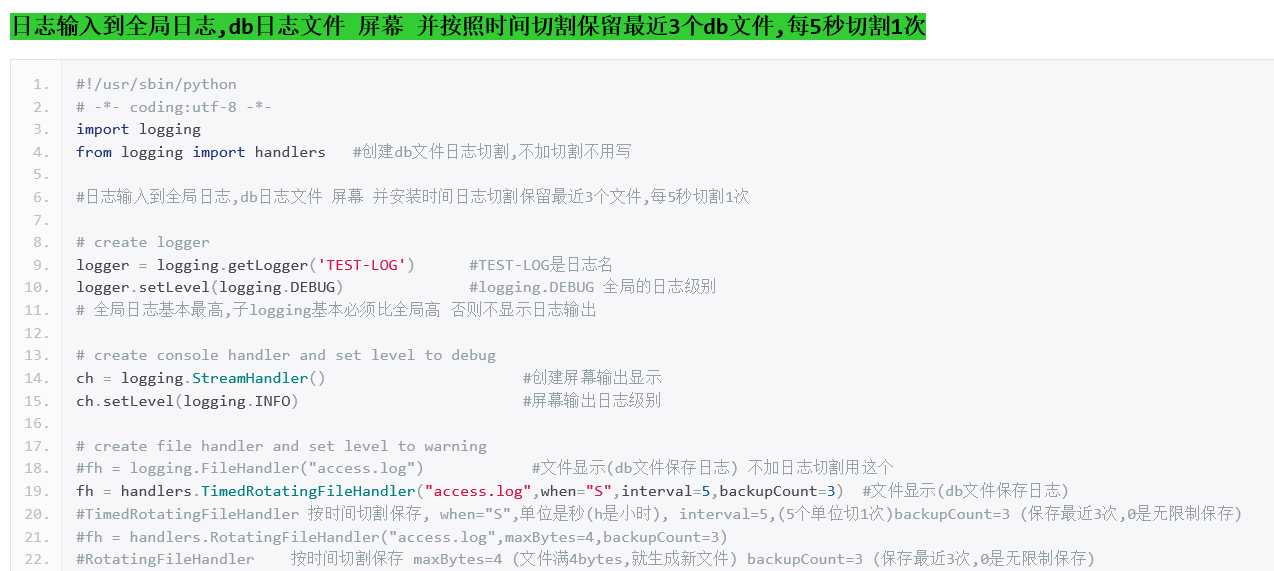
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨

sys模块
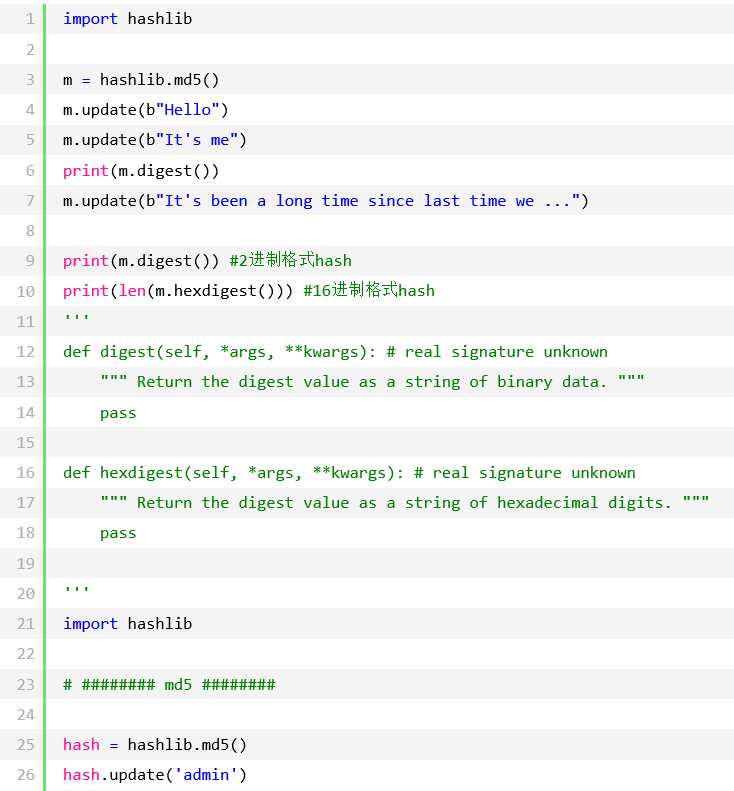
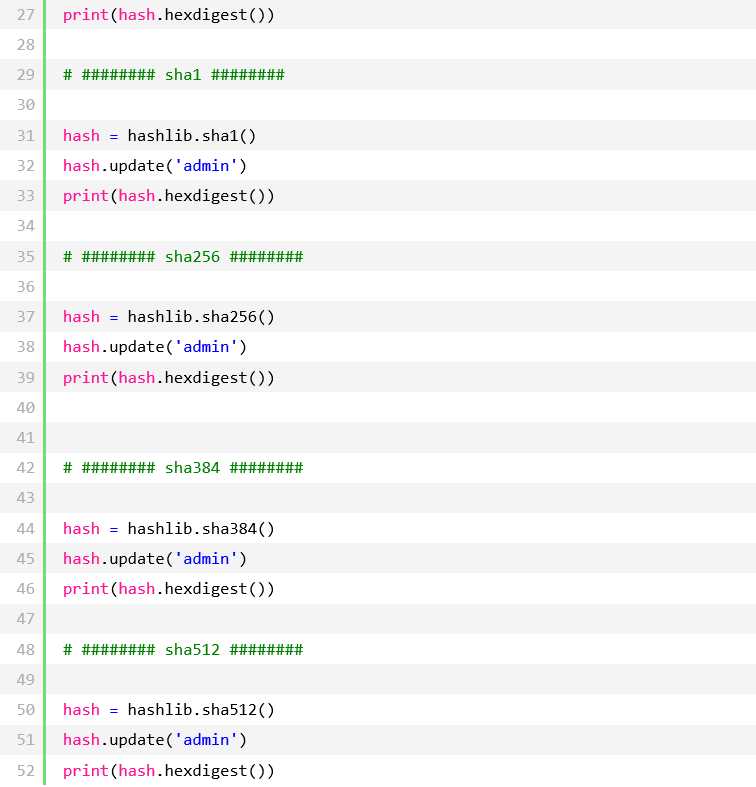
hashlib加密模块(用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法,md5是不可逆的)
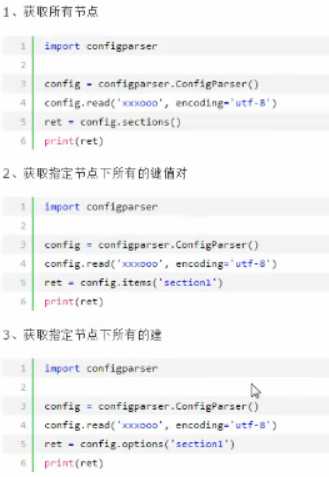
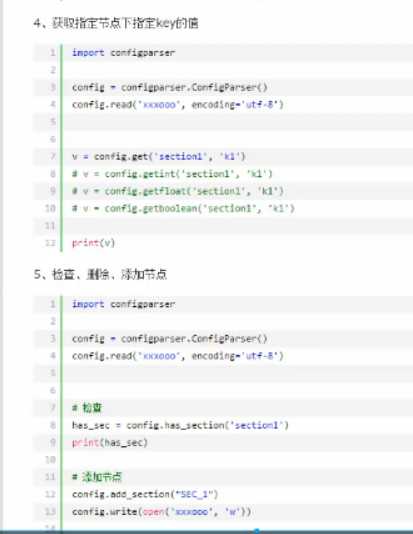
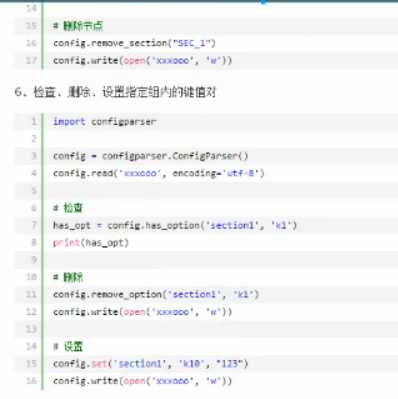
configparser 用于处理特定格式的文件,其本质上是利用open来操作文件(把所有类型都当做字符串处理)

getint 转换成整数
getfloat 转换成浮点数
getboolean 转换成布尔值
xml 是实现不同语言或程序之间进行数据交换的协议(xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。)
浏览器返回的字符串
1,html
2,json
3, xml
页面上做展示(字符串类型一个xml格式文件)
配置文件(文件,内部数据xml格式)
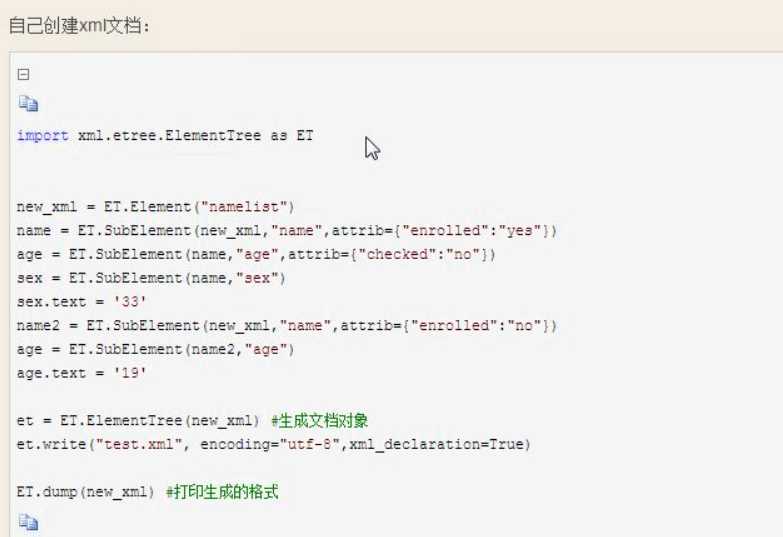
导入xml模块

遍历XML文档

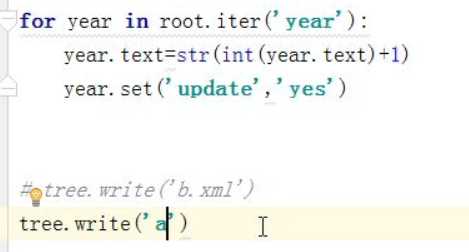
修改
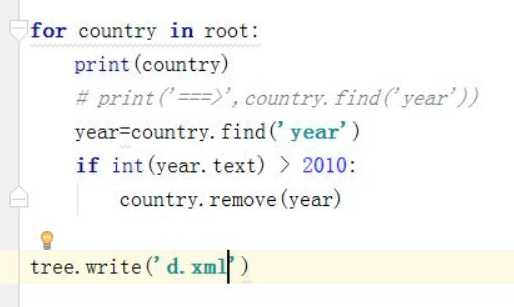
删除
添加
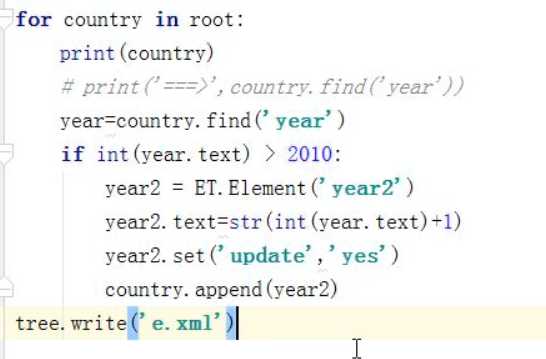
tag 获取当前节点的标签名
attrib 或许当前节点的属性
text 获取当前节点的属性
getchlldren 获取所有的子节点(已经废弃)
find 获取第一个寻找到的子节点
findtext 获取第一个寻找到的子节点的内容
findall 获取所有的子节点
iterfind 获取所有指定的节点,并创建一个迭代器(可以被for循环)
每一个节点都是Element对象,
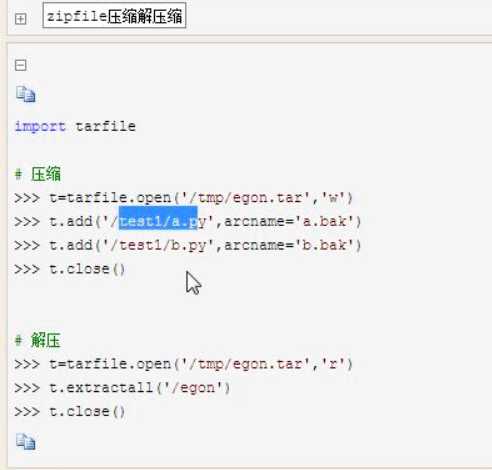
shutill 压缩模块(高级的文件,文件夹,压缩包,处理模块)
shutill.copyfileobj (将文件内容拷贝至另一个文件)
shutill.copyfile (拷贝文件)
shutill.copymode (仅拷贝权限,内容。组,用户均不变)
shutill.copystat (仅拷贝状态的信息)
shutill.copy(拷贝文件和权限)
shutill.copy2(拷贝文件和状态信息)
shutill.ignore_patterns
shutill.copytree
(递归的去拷贝文件夹)
shutill.rmtree(递归的去删除文件)
shuitll.move(递归的去移动文件,它类似mv命令,其实就是重命名)
shutill.make_archive(创建解压缩,并返回文件路径)

subprocess模块(执行系统命令)
获取状态码
shell=false的时候是传列表
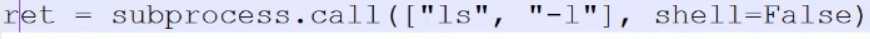
shell=true的时候是传字符串
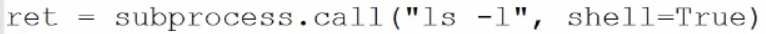
check_all(执行命令,如果状态码是0,则返回执行结果,否则抛异常)
check_output(执行命令,如果状态码是0,则返回执行结果,否则抛异常)
subprocess.Popen(...)
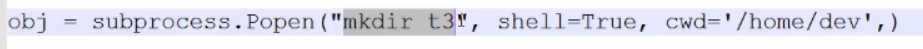
用于执行复杂的系统命令
可用参数:
终端输入的命令分为两种:
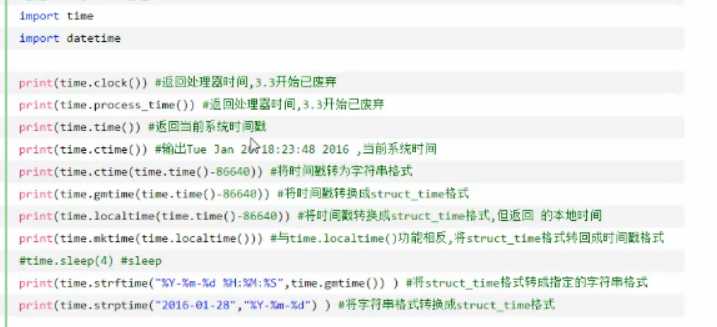
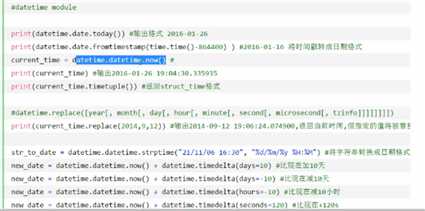
time&datatime模块
random模块
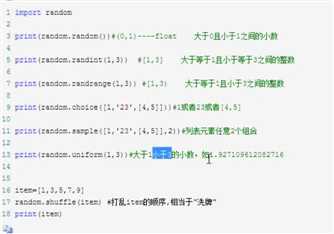
生成随机验证码

json&pickle模块(python的序列化)

json只能处理基本的数据类型

pickle支持任何类型
json: 用于字符串和python数据类型间进行转换(更适合跨语言,字符串,基本数据类型)


通过loads反序列化时,一定要使用双引号,否则有可能会报错

pickle: 用于python特有的类型和python的数据类型间进行转换(更适合所有类型的序列化,仅适用于python)
pickle的写入是二进制形式用wb模式,可以序列化python任何数据类型
json 的写入是字符串形式用w模式,只支持序列化python的str,int,float,set,list,dict,tuple数据类型,但json可和其他语言序列化
pickle功能: dumps,dump,loads,load
json 功能: dumps,dump,loads,load
序列化和反序列化主要用于动态数据存储
pickle.dumps 序列化 内存-->硬盘
pickle.loads 反序列化 硬盘-->内存
pickle
如下2个py文件功能是实现数据的动态存档
这个文件的作用,读取内存数据写入到db文件
import pickle#import json as pickle 这是用json执行 注意把wb改成waccount={ "id":63232223, "credit":15000, "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf"}f=open("account1.db","wb")f.write(pickle.dumps(account)) #相当于pickle.dump(account,f)f.close()这个文件的作用,读取db文件写入到内存
import pickle#import json as pickle 这是用json执行 注意把rb改成rf=open("account1.db","rb")account=pickle.loads(f.read())#相当于account=pickle.load(f)print(account)print(account["id"])#可以加如下,执行后注释 在执行看值是否改变 account["balance"]-=3400f=open("account1.db","wb")f.write(pickle.dumps(account))f.close()import shelve#内存写入db文件, 字典形式,f=shelve.open(r‘sheve.txt‘)f["student1"]={"name":"egon","age":18,"height":"180cm"}print(f[‘student1‘])f.close()#读取db文件的数据f=shelve.open(r‘sheve.txt‘)print(f[‘student1‘])print(f[‘student1‘]["name"])f.close()
标签:文件内容 生成 利用 数据 格式 基本 移动文件 str split
原文地址:http://www.cnblogs.com/gongxu/p/6945980.html