标签:png 架构 展现 com 处理 kafka集群 ges 图像 采集
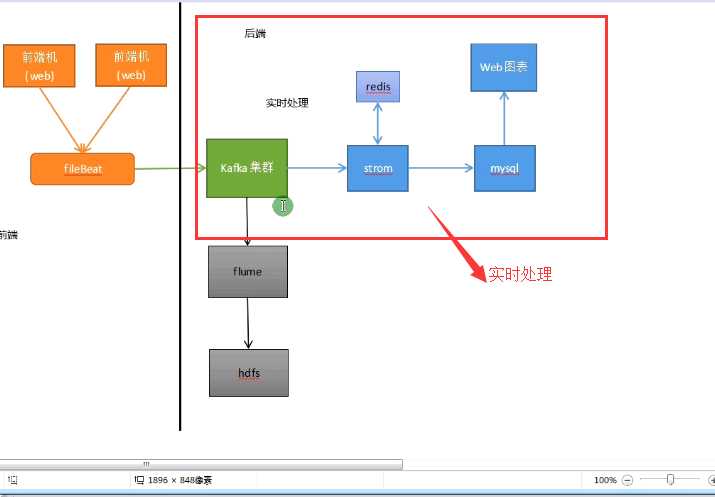
storm是一条一条数据处理,spark是一批数据处理的,storm才是真正意义的实时数据处理。

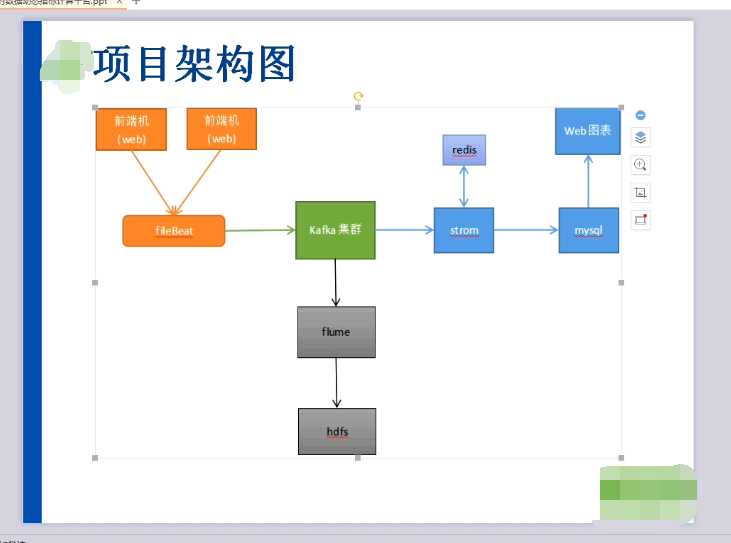
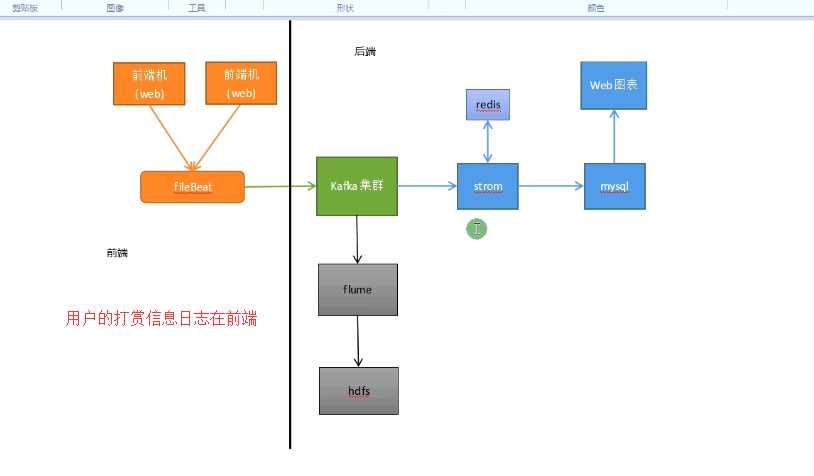
1、fileBeat类似flume用来采集日志的,fileBeat是轻量级的,对性能消化不大,而flume比较消化性能。
2、fileBeat会实时监控前端机,然后把数据实时写到Kafka集群里面。
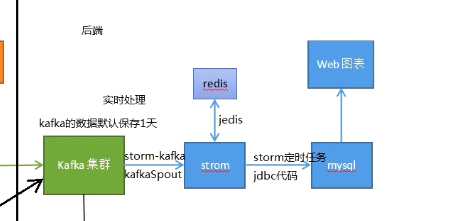
3、storm对kafka里的数据进行实时处理,在处理的时候与redis进行交互,因为有些关联的数据日志里是不全的。
4、处理完之后最终把数据写人mysql里,再到web图像进行展现。
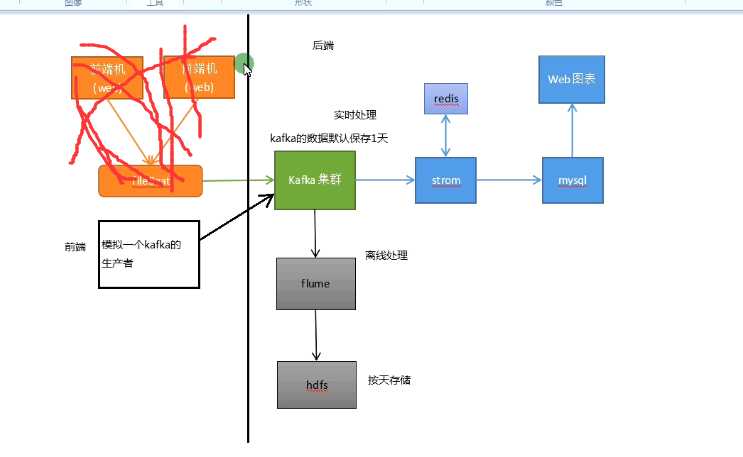
为了方便演示
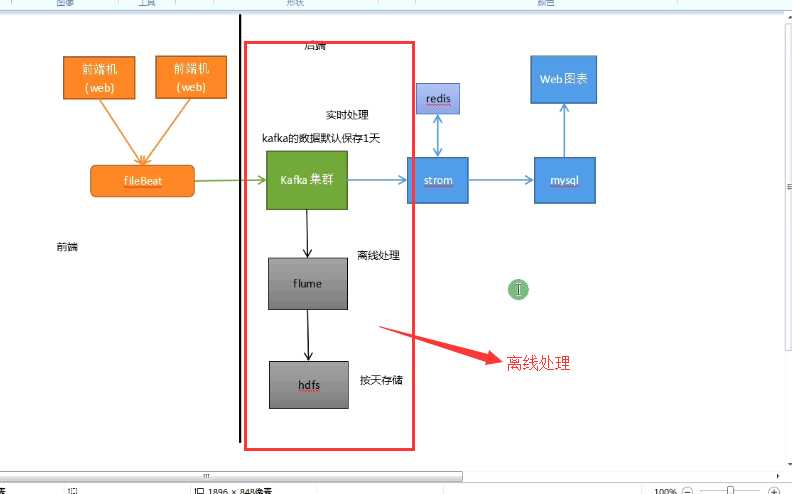
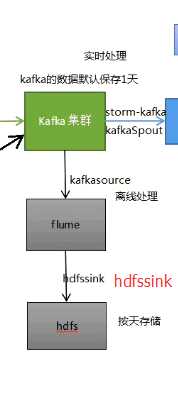
实时处理这条线需要用到的一些组件
离线处理需要用到的一些组件
标签:png 架构 展现 com 处理 kafka集群 ges 图像 采集
原文地址:http://www.cnblogs.com/braveym/p/6970791.html