标签:size output sof 优点 googl 准备 数据 样本 local
数据收集以后,我们下面接着要干的事情是如何将文本转换为神经网络能够识别的东西。
词向量
作为自然语言,只有被数学化才能够被计算机认识和计算。数学化的方法有很多,最简单的方法是为每个词分配一个编号,这种方法已经有多种应用,但是依然存在一个缺点:不能表示词与词的关系。
词向量是这样的一种向量[2.1, -3.31, 83.37, 93.0, -18.2, ……],每一个词对应一个向量,词义相近的词,他们的词向量距离也会越近(欧氏距离、夹角余弦)
词向量有一个优点,就是维度一般较低,一般是50维或100维,这样可以避免维度灾难,也更容易使用深度学习
词向量的原理?
词向量的训练是一种无监督学习,也就是没有标注数据,给我n篇文章,我就可以训练出词向量。
基于三层神经网络构建n-gram语言模型(词向量顺带着就算出来了)的基本思路:
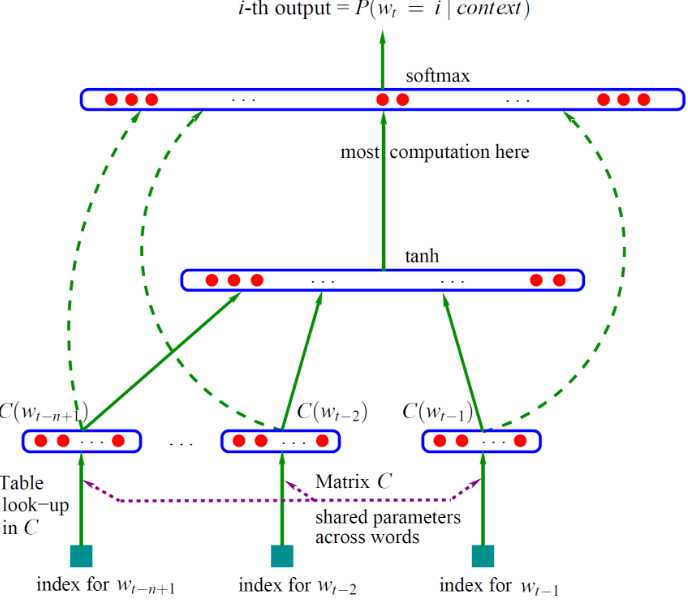
最下面的w是词,其上面的C(w)是词向量,词向量一层也就是神经网络的输入层(第一层),这个输入层是一个(n-1)×m的矩阵,其中n-1是词向量数目,m是词向量维度
第二层(隐藏层)是就是普通的神经网络,以H为权重,以tanh为激活函数
第三层(输出层)有|V|个节点,|V|就是词表的大小,输出以U为权重,以softmax作为激活函数以实现归一化,最终就是输出可能是某个词的概率。
另外,神经网络中有一个技巧就是增加一个从输入层到输出层的直连边(线性变换),这样可以提升模型效果,这个变换矩阵设为W
假设C(w)就是输入的x,那么y的计算公式就是y = b + Wx + Utanh(d+Hx)
这个模型里面需要训练的有这么几个变量:C、H、U、W。利用梯度下降法训练之后得出的C就是生成词向量所用的矩阵,C(w)表示的就是我们需要的词向量
怎样得到我们需要的词向量?
感觉别个写的很复杂的样子呀,不会怎么办,有个简单有效的解决方案就是google的word2vec工具,我们可以把需要训练的样本数据通过word2vec转换为二进制集合。
环境准备:
1、centos7.0
2、gcc
3、python-jieba
4、locale zh_CN.UTF-8
第一步 准备工作
咱们要准备一个分好词的文本文件,用jieba分词即可。
命名为train.txt

接着下载word2vec工具,这个c写的,需要编译,我已经编译完成,可以直接使用。编译后:

第二步 训练词向量
训练命令:
./word2vec -train train.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -thread 12 -binary 1

训练成功后会生成一个vectors.bin文件,这个就是训练好的词向量的二进制文件
第三步 测试,利用词向量寻找近义词
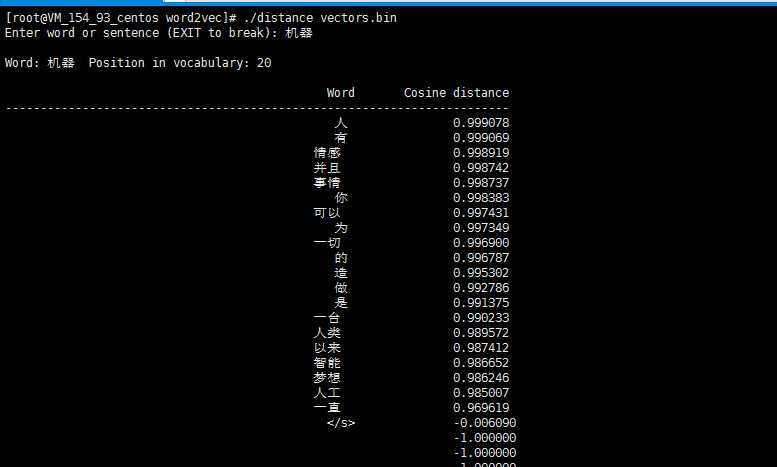
如上图,则说明我们的词向量训练成功。
标签:size output sof 优点 googl 准备 数据 样本 local
原文地址:http://www.cnblogs.com/xulele/p/6973913.html