标签:sequence level ace false etl pause white rtti 解决方案
-------------------siwuxie095
二叉搜索树的局限性
二叉搜索树在时间性能上是具有局限性的
同样的数据,可以对应不同的二叉搜索树,如下:
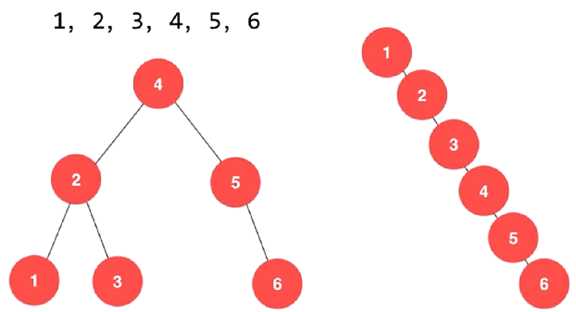
二叉搜索树可能退化成链表,相应的,二叉搜索树的查找操作是和这棵树
的高度相关的,而此时这颗树的高度就是这颗树的节点数 n,同时二叉搜
索树相应的算法全部退化成 O(n) 级别
显然,说二叉搜索树的查找、插入、删除 这三个操作都是 O(lgn) 级别的,
只是一个大概的估算,具体要和二叉搜索树的形状相关
二叉搜索树并不能像堆那样,保证所有的操作都一定是 O(lgn) 级别的,
为了形象展示二叉搜索树的局限性,实际做一个测试
程序:二叉搜索树和顺序查找表在数组有序情况下的对比
FileOps.h:
#ifndef FILEOPS_H #define FILEOPS_H
#include <string> #include <iostream> #include <fstream> #include <vector> using namespace std;
namespace FileOps {
int firstCharacterIndex(const string &s, int start) { for (int i = start; i < s.length(); i++) { if (isalpha(s[i])) { return i; } } return s.length(); }
//把大写字符串转换为小写字符串 string lowerS(const string &s) {
string ret = ""; for (int i = 0; i < s.length(); i++) { ret += tolower(s[i]); }
return ret; }
//将文件读入words数组中 bool readFile(const string& filename, vector<string> &words) {
string line; string contents = ""; ifstream file(filename); if (file.is_open()) { while (getline(file, line)) { contents += (line + "\n"); } file.close(); } else { cout << "Can not open " << filename << " !!!" << endl; return false; }
int start = firstCharacterIndex(contents, 0); for (int i = start + 1; i <= contents.length();) {
if (i == contents.length() || !isalpha(contents[i])) { words.push_back(lowerS(contents.substr(start, i - start))); start = firstCharacterIndex(contents, i); i = start + 1; } else { i++; } }
return true; } }
#endif |
BST.h:
#ifndef BST_H #define BST_H
#include "stdlib.h" #include <queue>
//二叉搜索树 template <typename Key, typename Value> class BST {
private:
struct Node { Key key; Value value; Node *left; Node *right;
Node(Key key, Value value) { this->key = key; this->value = value; this->left = this->right = NULL; }
Node(Node *node) { this->key = node->key; this->value = node->value; this->left = node->left; this->right = node->right; } };
Node *root; //根节点 int count;
public:
BST() { root = NULL; count = 0; }
~BST() { destroy(root); }
int size() { return count; }
bool isEmpty() { return count == 0; }
//向整棵二叉树树中插入新元素转换成向一个子树中插入新元素 //直到子树是空的时候,新建一个节点,这个新建的节点就是一 //棵新的子树,只不过它只有一个节点,将它直接返回回去 // //这样,通过递归的方式向二叉搜索树中插入了一个新的元素 void insert(Key key, Value value) { root = insert(root, key, value); }
bool contain(Key key) { return contain(root, key); }
//search()函数常见的返回形式: //(1)Node*,缺点:对外界来说,没有将数据结构Node进行隐藏 //(2)Value,缺点:如果查找不到的话,不知道该返回什么数值 //(3)Value*,优点:作为一个指针可以存一个空元素 Value *search(Key key) { return search(root, key); }
// 前序遍历 void preOrder() { preOrder(root); }
// 中序遍历:会将二叉搜索树的key从小到大进行排序 void inOrder() { inOrder(root); }
// 后序遍历 void postOrder() { postOrder(root); }
// 层序遍历 void levelOrder() { //需要引入队列:先进先出 queue<Node*> q; q.push(root); while (!q.empty()) {
Node *node = q.front(); q.pop();
cout << node->key << endl;
//如果node的左孩子不为空 if (node->left) { q.push(node->left); } //如果node的右孩子不为空 if (node->right) { q.push(node->right); } } }
// 寻找最小的键值 Key minimum() { assert(count != 0); Node *minNode = minimum(root); return minNode->key; }
// 寻找最大的键值 Key maximum() { assert(count != 0); Node *maxNode = maximum(root); return maxNode->key; }
// 从二叉树中删除最小值所在节点 void removeMin() { //根节点不为空,才能做事情 if (root) { root = removeMin(root); } }
// 从二叉树中删除最大值所在节点 void removeMax() { if (root) { root = removeMax(root); } }
// 从二叉树中删除键值为key的节点 void remove(Key key) { root = remove(root, key); }
private:
// 向以node为根的二叉搜索树中,插入节点(key, value) // 返回插入新节点后的二叉搜索树的根 Node *insert(Node *node, Key key, Value value) { //递归到底的情况:如果一个节点都没有, //创建一个新节点作为子树的根 if (node == NULL) { count++; return new Node(key, value); }
//如果新插入节点的key等于当前节点的key,做更新操作即可 if (key == node->key) { node->value = value; } else if (key < node->key) { node->left = insert(node->left, key, value); } else { // key > node->key node->right = insert(node->right, key, value); }
return node; }
// 查看以node为根的二叉搜索树中是否包含键值为key的节点 bool contain(Node *node, Key key) { //如果当前访问的节点已经为空, //即不包含,直接返回false即可 if (node == NULL) { return false; }
if (key == node->key) { return true; } else if (key < node->key) { return contain(node->left, key); } else { // key > node->key return contain(node->right, key); } }
// 在以node为根的二叉搜索树中查找key所对应的value Value *search(Node *node, Key key) {
if (node == NULL) { return NULL; }
if (key == node->key) { return &(node->value); } else if (key < node->key) { return search(node->left, key); } else { // key > node->key return search(node->right, key); } }
// 对以node为根的二叉搜索树进行前序遍历 void preOrder(Node *node) {
if (node != NULL) { cout << node->key << endl; preOrder(node->left); preOrder(node->right); } }
// 对以node为根的二叉搜索树进行中序遍历 void inOrder(Node *node) {
if (node != NULL) { inOrder(node->left); cout << node->key << endl; inOrder(node->right); } }
// 对以node为根的二叉搜索树进行后序遍历 void postOrder(Node *node) {
if (node != NULL) { postOrder(node->left); postOrder(node->right); cout << node->key << endl; } }
void destroy(Node *node) { //使用后序操作的方式来释放整棵树 if (node != NULL) { destroy(node->left); destroy(node->right);
delete node; count--; } }
// 在以node为根的二叉搜索树中,返回最小键值的节点 Node *minimum(Node *node) { if (node->left == NULL) { return node; }
return minimum(node->left); }
// 在以node为根的二叉搜索树中,返回最大键值的节点 Node *maximum(Node *node) { if (node->right == NULL) { return node; }
return maximum(node->right); }
// 删除掉以node为根的二叉搜索树中的最小节点 // 返回删除节点后新的二叉搜索树的根 Node *removeMin(Node *node) { //如果当前节点的左孩子为空,则当前节点为最小节点 //显然,最小值所在的节点只可能有右孩子 if (node->left == NULL) { Node *rightNode = node->right; delete node; count--; return rightNode; }
node->left = removeMin(node->left); return node; }
// 删除掉以node为根的二叉搜索树中的最大节点 // 返回删除节点后新的二叉搜索树的根 Node* removeMax(Node* node) { //如果当前节点的右孩子为空,则当前节点为最大节点 //显然,最大值所在的节点只可能有左孩子 if (node->right == NULL) { Node *leftNode = node->left; delete node; count--; return leftNode; }
node->right = removeMax(node->right); return node; }
// 删除掉以node为根的二叉搜索树中键值为key的节点 // 返回删除节点后新的二叉搜索树的根 Node* remove(Node* node, Key key) {
if (node == NULL) { return NULL; }
if (key < node->key) { node->left = remove(node->left, key); return node; } else if (key > node->key) { node->right = remove(node->right, key); return node; } else { // key == node->key //如果node只有右孩子 if (node->left == NULL) { Node *rightNode = node->right; delete node; count--; return rightNode; }
//如果node只有左孩子 if (node->right == NULL) { Node *leftNode = node->left; delete node; count--; return leftNode; }
// node->left != NULL && node->right != NULL //即node的左右孩子都不为空 Node *successor = new Node(minimum(node->right)); count++;
successor->right = removeMin(node->right); successor->left = node->left;
delete node; count--;
return successor; } } };
//前中后序遍历属于深度优先遍历 //而层序遍历则属于广度优先遍历 // //这四种遍历方式相对都非常高效,时间复杂度是O(n) // // // //二叉搜索树中,最复杂的一个操作就是删除节点 // //其实删除一个节点很容易,关键是将这个节点删除之后,如何来处理 //与这个节点相关联的部分,使得整棵树依然保持二叉搜索树的性质 // // //如果要删除的节点只有一个孩子,那么这个问题很简单,和删除最大 //(小)值所在节点的方法一样,最难的是删除左右都有孩子的节点 // //处理这种情况的一个非常经典的算法就是Hibbard Deletion,这个算 //法在 1962 年被一个叫做 Hibbard 的计算机科学家提出,具体如下: // //假如这个被删除的节点是 d,d 既有左孩子,又有右孩子,其实要做 //的事情就是找一个节点来代替 d,这个节点既不应该是 d 的左孩子, //也不应该是 d 的右孩子,Hibbard 提出这个节点应该是 d 的右子树 //中的最小值 // //删除左右都有孩子的节点 d,用 s 来代替,即 s 是 d 的后继 //(d 即 deletion,s 即 successor) // //s=min(d->right) //s->right=delMin(d->right) //s->left=d->left // //删除 d,s 是新的子树的根 // // // //其实代替的节点也可以是 d 的左子树中的最大值,如下: // //删除左右都有孩子的节点 d,用 p 来代替,p 是 d 的前驱 //(d 即 deletion,p 即 predecessor) // //p=max(d-left) //p->left=delMax(d->left) //p->right=d->right // //删除 d,p 是新的子树的根 // // //删除二叉搜索树中的任意一个节点 时间复杂度 O(lgn)
#endif |
SequenceST.h:
#ifndef SEQUENCEST_H #define SEQUENCEST_H
#include <iostream> #include <cassert> using namespace std;
//顺序查找表:采用链表的数据结构实现 template<typename Key, typename Value> class SequenceST {
private:
struct Node { Key key; Value value; Node *next;
Node(Key key, Value value) { this->key = key; this->value = value; this->next = NULL; } };
Node* head; int count;
public:
SequenceST() { head = NULL; count = 0; }
~SequenceST() { while (head != NULL) { Node *node = head; head = head->next; delete node; count--; }
assert(head == NULL && count == 0); }
int size() { return count; }
bool isEmpty() { return count == 0; }
void insert(Key key, Value value) { Node *node = head; while (node != NULL) { if (key == node->key) { node->value = value; return; } node = node->next; }
Node *newNode = new Node(key, value); newNode->next = head; head = newNode; count++; }
bool contain(Key key) {
Node *node = head; while (node != NULL) { if (key == node->key) { return true; } node = node->next; }
return false; }
Value* search(Key key) {
Node *node = head; while (node != NULL) { if (key == node->key) { return &(node->value); } node = node->next; }
return NULL; }
void remove(Key key) {
if (key == head->key) { Node* delNode = head; head = head->next; delete delNode; count--; return; }
Node *node = head; while (node->next != NULL && node->next->key != key) { node = node->next; }
if (node->next != NULL) { Node* delNode = node->next; node->next = delNode->next; delete delNode; count--; return; } } };
#endif |
main.cpp:
#include "FileOps.h" #include "BST.h" #include "SequenceST.h" #include <iostream> #include <vector> #include <string> #include <ctime> using namespace std;
int main() { //把英文版共产主义宣言作为测试用例 string filename = "communist.txt"; vector<string> words; if (FileOps::readFile(filename, words)) {
cout << "There are totally " << words.size() << " words in " << filename << endl;
cout << endl;
// test BST time_t startTime = clock(); BST<string, int> *bst = new BST<string, int>(); for (vector<string>::iterator iter = words.begin(); iter != words.end(); iter++) { int *res = (*bst).search(*iter); if (res == NULL) { (*bst).insert(*iter, 1); } else { (*res)++; } }
//查找操作:单词 unite 的词频 cout << "‘unite‘ : " << *(*bst).search("unite") << endl; time_t endTime = clock(); cout << "BST , time: " << double(endTime - startTime) / CLOCKS_PER_SEC << " s." << endl;
cout << endl;
delete bst;
// test SST startTime = clock(); SequenceST<string, int> *sst = new SequenceST<string, int>(); for (vector<string>::iterator iter = words.begin(); iter != words.end(); iter++) { int *res = (*sst).search(*iter); if (res == NULL) { (*sst).insert(*iter, 1); } else { (*res)++; } }
cout << "‘unite‘ : " << *(*sst).search("unite") << endl;
endTime = clock(); cout << "SST , time: " << double(endTime - startTime) / CLOCKS_PER_SEC << " s." << endl;
cout << endl;
delete sst;
// test BST2 startTime = clock(); BST<string, int> *bst2 = new BST<string, int>();
//在向二叉搜索树中插入节点之前,将words数组进行一次排序, //使得之后,按照从小到大的顺序逐一将单词放到二叉搜索树中 sort(words.begin(), words.end());
for (vector<string>::iterator iter = words.begin(); iter != words.end(); iter++) { int *res = (*bst2).search(*iter); if (res == NULL) { (*bst2).insert(*iter, 1); } else { (*res)++; } }
cout << "‘unite‘ : " << *(*bst2).search("unite") << endl; endTime = clock(); cout << "BST2 , time: " << double(endTime - startTime) / CLOCKS_PER_SEC << " s." << endl;
cout << endl;
delete bst2;
}
system("pause"); return 0; }
//为什么BST2比顺序查找表SST还要慢呢?原因如下: // //(1)顺序查找表SST用链表实现,它只处理一个指针,而BST2虽然退化 //成了链表,但在实现的每一步中,还是有左孩子这个概念的,所以要不 //停的判断左孩子为空这种情况,这就消耗了一定的性能 // //(2)BST是采用递归的方式实现的,递归本身也会比在链表中采用迭代 //的方式实现,性能会慢一些,累积起来就有了时间差距 |
运行一览:
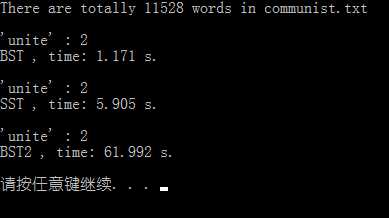
其实对于大多数情况,在正常使用中,BST 的性能非常好,出现非常极端的
退化情况的概率非常小
尽管如此,还是有机会出现这样的情况,可能有人就会想,可以像快速排序
那样,在初始化的时候,将数据打乱即可
当然,这是一个解决方案, 不过这个解决方案的缺点在于:需要一上来就拿
到所有的数据
可是在有些情况下,数据是慢慢的流入到系统的。如果在这个过程中,数据
是近乎有序的话,BST 的效率就令人担忧了
实际上,计算机科学家也为此想出了解决方案:可以改造二叉搜索树的实现,
使得二叉搜索树无法退化成链表,称这样的二叉搜索树为 平衡二叉搜索树,
简称 平衡二叉树(也称为 AVL 树)
「AVL 树中任何节点的两个子树的高度最大差别为一」
平衡二叉树的性质保证了整个二叉树的高度一定是 logN 级别的
平衡二叉树有诸多的实现,其中最为著名的一种实现,叫做 红黑树
红黑树非常创新的将节点分为了两类:红色节点 和 黑色节点,如下:
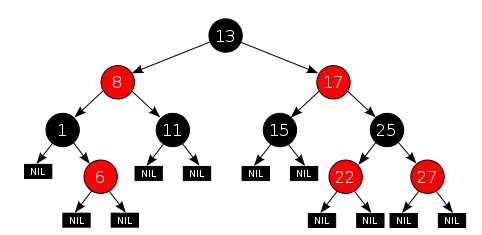
红黑树是每个节点都带有颜色属性的二叉搜索树,颜色为红色 或 黑色,
除了要满足一般二叉搜索树的要求,还要满足如下额外要求:
1)节点是红色 或 黑色
2)根是黑色
3)所有叶子都是黑色(叶子是 NIL 节点,即 空节点)
4)每个红色节点必须有两个黑色的子节点(从每个叶
子到根的所有路径上不能有两个连续的红色节点)
5)从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点
这些约束确保了红黑树的关键特性:从根到叶子的最长的可能路径
不多于最短的可能路径的两倍长,结果是这个树大致上是平衡的
「注:nil 叶子 或 null 叶子」
另外,平衡二叉树还有其他的实现方式,如:2-3 树、伸展树
事实上,对于树这种数据结构而言,还有非常多的变种,如:平衡二叉树
和堆的结合 Treap
最后介绍一个叫做 Trie 树的数据结构,也叫做字典树 或 前缀树
对于二叉搜索树来说,一个经典的用途就是字典,但对于字典这样的实现
有一个问题:假如收录的单词非常多,几千万的数量级,那么即使是 lgn
这样的查找效率,其实也是非常慢的
而 trie 做到了使用一种数据结构,使得查找一个单词的定义,它的时间复
杂度是和单词本身的长度相关的,而和字典中到底有多少个单词无关
换句话说,不管字典里有多少个单词,要想查找 news 这个单词(4 个字母),
只需要找 4 个节点就够了
具体实现:在 trie 中,每个节点中会存一个字母,而一个单词则是从根节点
开始,依次向下到它的某一个孩子节点的这样的一个路径
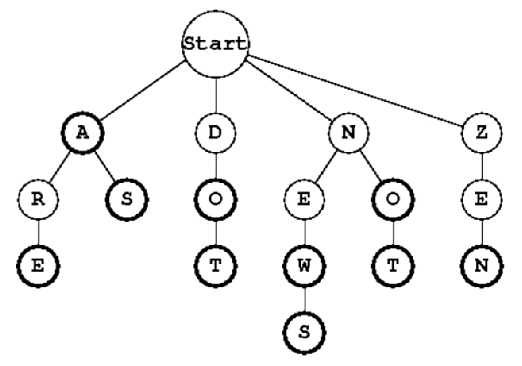
不难想象,每一个节点除了存一个字母之外,相应的要存 26 个孩子的
指针
当然,还有一些细节要处理,这是因为对于某些单词来说,它们是另外
某些单词的子集,所以并非是所有单词都要遍历到叶子节点
【made by siwuxie095】
标签:sequence level ace false etl pause white rtti 解决方案
原文地址:http://www.cnblogs.com/siwuxie095/p/6984262.html