标签:pap 数据集 app stanford tps action seq 背景 blog
SST: Single-Stream Temporal Action Proposals
2017-06-11 14:28:00
本文提出一种 时间维度上的 proposal 方法,进行行为的识别。本文方法具有如下的几个特点:
1. 可以处理 long video sequence,只需要一次前向传播就可以处理完毕整个video;可以处理任意长度的 video,而不需要处理重叠的时间窗口;
2. 在 proposal generation task 上取得了顶尖的效果;
3. SST proposals 提供了一个较强的基准,进行 temporal action localization,将该方法结合到现有的分类任务中,可以改善分类的性能。
所提出方法的流程图如下所示:
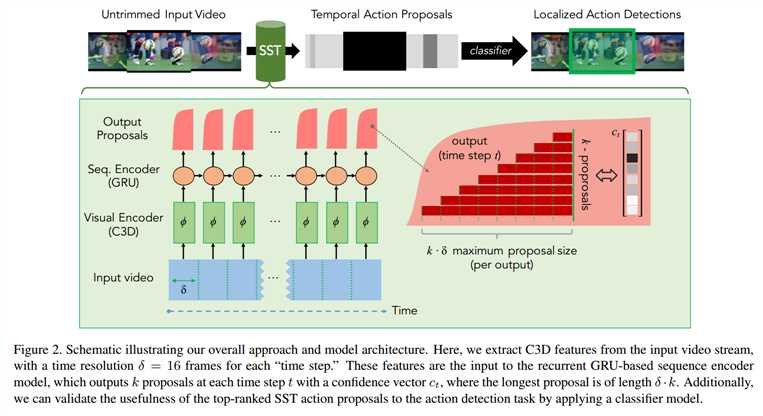
Technical Approach:
我们所要达到的目标是:在一个 long video 上产生 temporal action proposals。
网络的几个重要的部分:
1. Visual Encoder (C3D) 用于编码 video frame,感知输入 video ;
2. Seq.Encoder (GRU) 的输入是 降维后的 C3D feature,设计该模块的目的是: accumulate evidence across time as the video sequence progresses. 为了能够更好的产生 good proposals,该模块应该能够收集信息直到确定某个动作已经发生了,与此同时,扔掉不相关的背景信息。

Training:
由于行为识别本身就是一个多分类问题,所以这里用到了 交叉熵损失函数来作为最终 loss function。
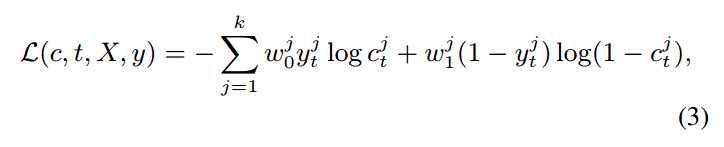
而总的 loss 就是该 loss 的加和:
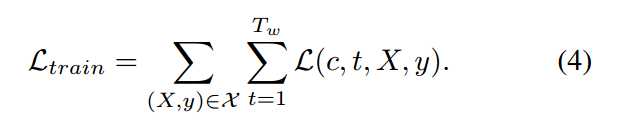
数据集提供了裁剪好的 video,所以就是给定 gt 的监督训练任务,完全可以用反向传播算法进行训练。
Reference:
1. Paper: http://vision.stanford.edu/pdf/buch2017cvpr.pdf
2. Github: https://github.com/ranjaykrishna/SST
论文笔记之 SST: Single-Stream Temporal Action Proposals
标签:pap 数据集 app stanford tps action seq 背景 blog
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/6985508.html