标签:lin 模糊 立方体 预测 ges live 混合 情况 标准
基于快速搜索与寻找密度峰值的聚类(Alex Rodriguez and Alessandro Laio)
摘要:聚类分析目的是基于元素之间的相似度对其进行分类,应用范围从天文学到生物信息学、文献计量学到模式识别。我们提出一种方法,思想基于簇中心具有比其邻居更大密度的特点以及与更大密度点之间有一个相对较大的距离(1、簇中心点有相对高的密度 2、簇中心点之间距离一般较大,即不同类别之间一般距离较远),这种思想形成了簇数目直观出现的聚类机制的基础,自动发现和排除异常点,同时在识别簇时,不用关心其形状和它们嵌入空间的维数,我们在一些测试案例中证明了该算法的能力。
聚类算法试图基于他们之间相似度归类元素到类别,或者簇。一些不同的聚类策略已经提出,但是,甚至一个簇的定义都没有达成一致,在k-means和k-中心点方法中,簇是一些到簇中心小距离为特点的一些数据点的组合。目标函数,典型的是到假定簇中心集合的距离之和最小,优化直到最好的聚类中心候选点被找到,然而,由于一个数据点总是被分配到距离它最近的中心点,这些方法不能探测非球形的集群。在分配算法中,试图复制观察到的数据实现作为一个预先定义的概率分布函数(?啥),这些方法的准确性取决于这些试验概率去表达数据的能力。
聚类任意形状可以通过基于数据点的局部密度来检测,在噪声下基于密度空间聚类的应用(DBSCAN),选择一个密度阈值,抛弃区域中密度小于这个阈值的数据点作为噪声点,高密度区域之间的不连贯性来进行分配不同的簇,然而,选择一个合适的密度是非平凡的,这一个缺点不会呈现在均值漂移聚类算法中,这里有一个簇定义为数据点收敛到密度分布函数同等的局部最大值。这个方法允许寻找非球形的聚类,但是只在数据定义为坐标集(?set of coordinates)有用,并且计算代价大。
这里,我们提出另一种方法,类似于k中心点算法,它仅仅依赖于数据点之间的距离,类似于DBSCAN和均值漂移算法,它可以检测非球形的簇并且自动寻找正确的簇数目。这些簇中心被定义,如同均值漂移方法,如数据点密度的局部最大值。然而,不像均值漂移,我们的机制不需要嵌入数据点到向量空间以及明确最大化每一个数据点的密度域。
算法的基础是假定这些聚类中心点被更低局部密度的邻居所环绕,同时与更大局部密度的数据点之间有一个相对较大的距离。对每一个数据点,我们计算两个量,一个是局部密度ρi和它与更高局部密度数据点之间的距离δi,这两个量都且仅仅取决于数据点之间的距离dij,假定满足三角不等式。局部密度ρi定义为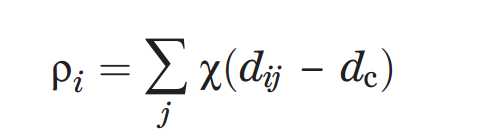
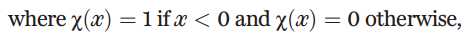
dc是截断距离,也就是说在截断距离之内时取值为1,在或者超过截断距离的取0.
δi度量是通过计算点i和其他具有更高密度的点之间最小距离。
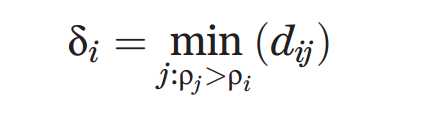
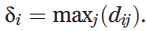
这个观测是算法的核心,用图1简单的例子来阐述,28个二维空间中的点。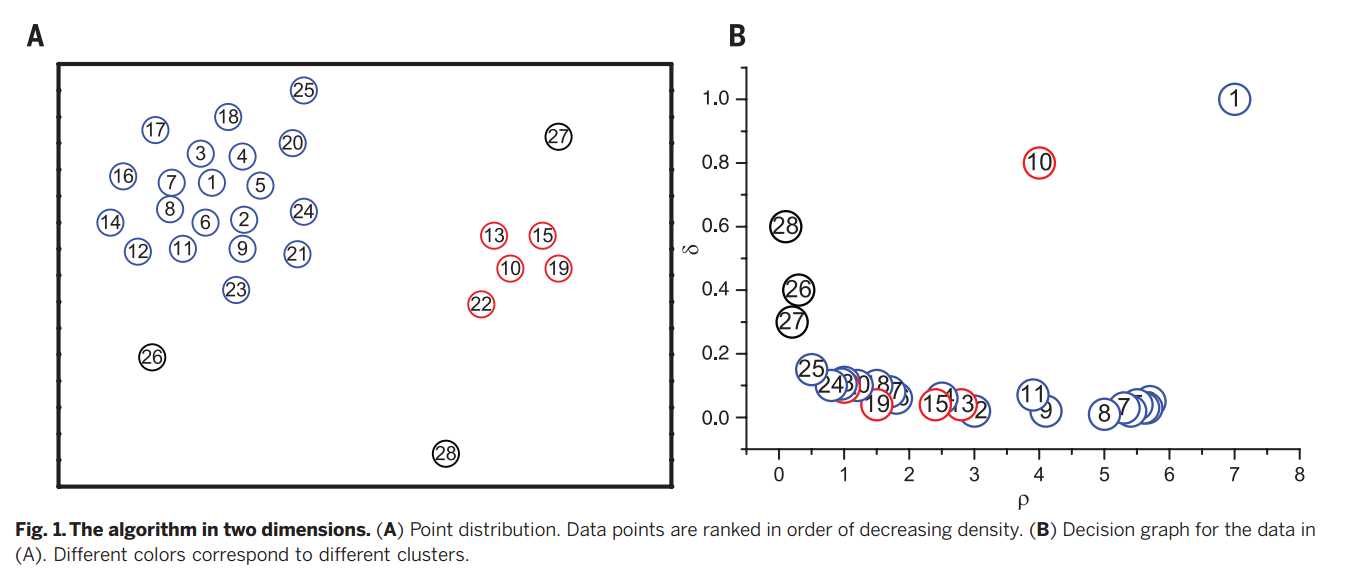
聚类中心点找到之后,每一个剩下的点分配其最邻近较高密度的同一簇(剩下的点去找离它最近的聚类中心点,形成簇,也就是说这个也是分为两步的,一个是利用密度和距离寻找聚类中心点,一个是找到中心点之后进行分配,而这个分配只需要执行一次)。数据点进行分配簇单步执行,对比其他算法,是在目标函数下进行迭代优化(省去了在每一次找到聚类中心后,每一次进行分配迭代过程)。
聚类分析中,经常定量的度量一次分配的可靠性是十分有用的,基于函数的优化方法,该值的收敛性是自然质量的度量,在DBSCAN方法中,考虑可靠点是密度高于某一个阈值,这个会造成低密度簇,如图2E所示,分类为噪声。在我们的算法中,我们不需要引进噪声信号截断,相反,我们首先为每一个簇找到一个边界区域,定义为一个属于该簇的数据点集合,但同时存在数据点属于他簇的距离为dc。我们接下来发现,对于每一个簇,在其边界区域的最高密度点,我们记这个密度为ρb。这个簇的数据点,其中密度大于ρb被视为部分簇核心(鲁棒性分配),其他视为簇个光晕(适合看做是噪声)。
为了对我们的程序做基准测试,我们先考虑图2的一些测试案例,
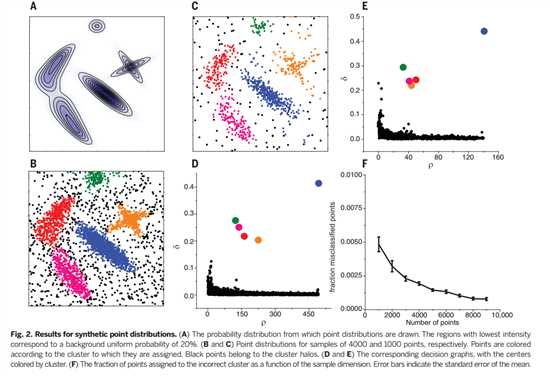
算法概率峰值的捕获位置和形状,尽管这些对应着非常不同的密度和非球形的峰值。
接下来我们使用图3进行基准测试,计算少数点案例的密度,我们采用指数内核

这个方法具有鲁棒性,在关于改变度量标准的,不会显著影响低于距离dc,也就是说,使密度在方程式中的估计不改变。明显的,距离求解的方程式会由于这个度量标准的改变而改变,但是这在决策途图的结构中很容易认识到(尤其是,大部分具有大δ值值的数据点)是密度值排序的结果,不是距离远数据点之间的实际距离,这一陈述的例子如图S5所示(图在哪?)
我们的方法只需要度量(计算)所有成对数据之间的距离,并不需要参数化一个概率分布函数,或者多维密度函数。因此,它的性能不受数据点嵌入的固有维数空间的影响。我们已经证实了这个,256维的16簇测试数据,算法找到了簇的数目,并且正确的分配数据点,对一个数据集对7个x射线特征进行了210次测量小麦种子的三种类型,该算法正确地预测了三个簇的存在和分类正确97%的点分配到集群核心(图S7和S8)。
我们应用这个方法到Olivetti Face Database ,一个机器学习算法的普遍基准,意在没有任何先前训练的情况下,识别数据库中的主题数,这个数据集对我们的方法提出了一个严重的挑战,因为“理想”的簇数量(主题数)与数据集中的元素数量(不同的图片,每一个主题10张)是可以相比较(这里是什么意思呢?)。这使得一个可靠的密度的估计很困难。两张图片的相似度依据(19)来计算,密度估计是通过方差dc=0.07的高斯核来计算的,对于这样一个小的数据集,密度估计不可避免地受到由大型统计错误的影响。因此,我们分配图像到一个类别中,较之先前的例子,是它遵守一个稍微有限制的规则,一张图像分配其最邻近具有更高的密度图像同一个簇,只有在它们的距离小于dc。结果,那些图像到其他更高密度图像距离比dc远的仍然未分配。
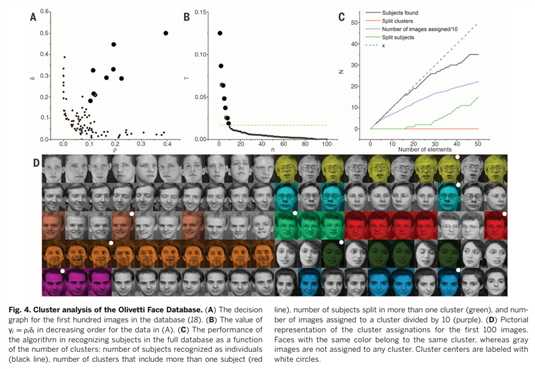
在(20)中,我们计算部分成对图像正确被分为统一主题(rture),部分成对不同主题的图像错分为统一主题(rfase)。如果分配时不使用截断dc(也就是说应用我们的算法在一般公式上),获得rture~68%,rfase~1.2%在~42到~50的中心点,其性能堪比最新水平的无监督图像分类。
最后我们对聚类算法进行了基准测试在分子动力学轨迹的分析上三丙氨酸在水中的300克,在这个里面,簇近似对应于动能盆地,即独立构造一种稳定的系统,这在相当长一段时间内都是稳定的,被自由的能量屏障隔开,在微观的时间尺度上交叉很少。我们第一次用标准方法分析轨迹,根据动力学的光谱分析矩阵,其特征值与系统的松弛时间相关。第七个特征值以后呈现的差距(图S10)表示这个系统有八个盆地,与此一直,我们的聚类分析给出了八个簇,包括构造在一对一的对应关系中定义了动态盆地。(这都是什么?)
识别密度最大的簇,如同这里和其他基于密度的聚类算法,这是一个简单而直观的选择,但是有一个重要的缺点。如果一个随机生成数据点,有限样本容量的密度估计是远远不一致的,而是表现为几个最大值。然而,决策图使我们能够区分真正的集群密度波动所产生的噪音。定性上说,只有在前案例中,数据点对应的簇中心由于ρ和δ有相当大的差距而与其他点之间分离开。对于随机分布,相反,它观察的是ρ和δ值时连续分布,确实,我们进行分析的随机生成的点集均匀分布在一个超立方体。前面公式中计算数据点之间的距离由超立方体的周期性边界条件来计算。这个分析表明对于随机分布的数据点,值γi=ρiδi根据幂律分布,它的指数取决于数据点嵌入空间的维数,真实簇数据集γ的分布,如图2到4所示,与幂律有显著的不同,特别是在γ高的区域(如图S11)。这个观察可能提供自动选择集群中心基础标准以及统计验证在我们方法下执行的可靠性分析方法。
Clustering by fast search and find of desity peaks(基于快速搜索与寻找密度峰值的聚类)
标签:lin 模糊 立方体 预测 ges live 混合 情况 标准
原文地址:http://www.cnblogs.com/betterforever/p/7007899.html