标签:-- 最小化 组成 图像 函数 开始 种类 ict 数据
图像分类是计算机视觉中的一项核心任务,那么什么是图像分类?
例如,给你一个标签集,其中包括(猫、狗、鸟、卡车、飞机...等) 然后给你一张图片,那么这张图片属于哪个类别呢?这就是一个分类问题
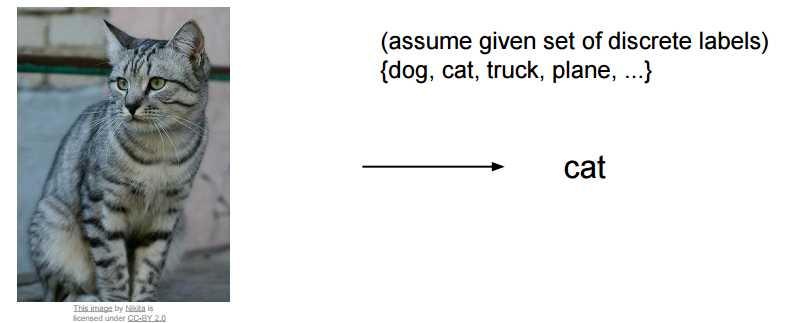
跟人有区别的是计算机“看到”的图是一堆数字组成的矩阵,彩色图通常为RGB三通道组成的,灰度则为0~255数字组成的单通道图片。
对于计算机来说识别物体面临着许多的困难,如从不同的角度拍摄的物体,不同光照下的物体,发生形变的物体,被遮挡的物体,跟背景相似的物体以及同种类物体间的变化都会对识别造成困难。
下面看看什么是图片分类器,一个简单的图片分类器应该如下,输入一副图像,返回一个对应的标签。
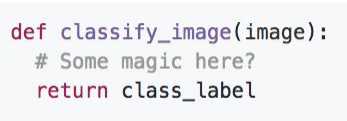
分类器通常是数据驱动型的方法,其步骤一般是 : 1 收集带标签的图像, 2 用机器学习方法在数据集上训练模型, 3 在测试集上评估验证模型
下面介绍一种简单的分类器 nearest neighbor,也就是最邻近模型,当比较前k个最邻近时便是KNN。
lecture中介绍的数据集是cifar10,包括10类图片,50000张训练,10000张测试

在NN中为了找出与输入图像最相近的图像我们需要一种比较机制,这里引入了L1 distance。
![]()
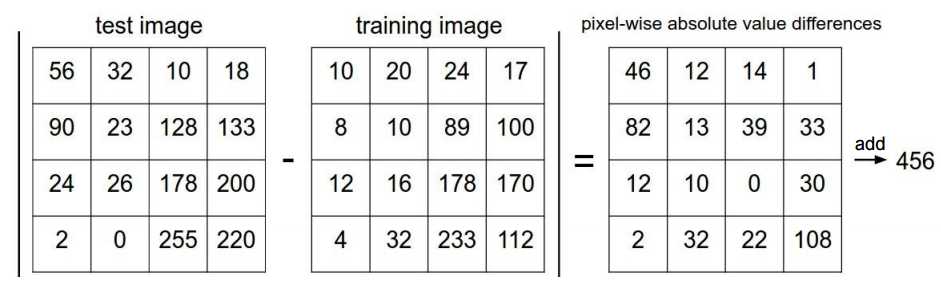
上式中I1,I2分别为我们输入的需要分类的测试图像和训练集图像,拿一个简单4*4的图像做例子如下,对于位置像素做差后求和得到两幅图像间的距离。
所以NN的train step 是记录所有训练图像的数值, predict step 则是找出与测试图片最近的图片。 这里我们发现一个问题就是没预测一副图像我们都需要计算所有训练集图片与测试图片的距离,也就是测试
时间复杂度为O(N),而训练的时间复杂度反而为O(1)。通常我们可以接受较长训练的时间,而希望测试的时间能够短些,而knn恰恰相反。另外NN算法还存在如何确定k值,如何确定合适的计算距离以及
计算时面临维度爆炸等一系列的问题,而这些参数通常是依据你的问题而定的,往往需要我们在问题中寻找答案。
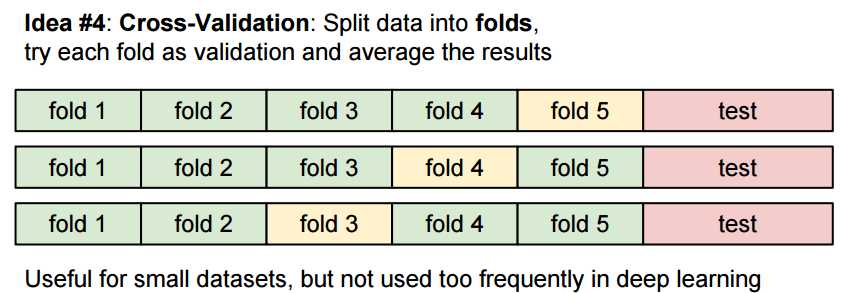
lecture中介绍了cross validation也就是交叉验证,用来确定k的最佳值。 其将训练集分为5个fold,每次分别用其中一个做验证集,最后取平均得到结果。
后面有提到距离机制对于像素的信息是很难提取的,最后给KNN的结论就是,不适合用在图像分类领域。。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
线性分类器
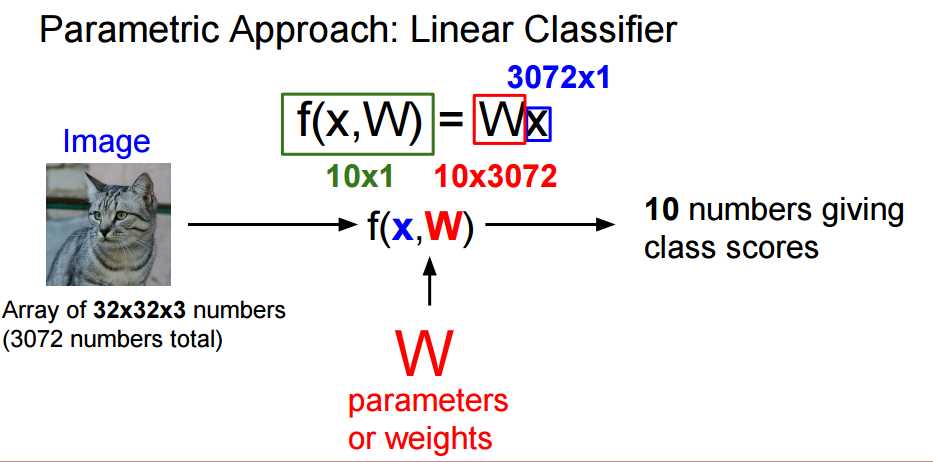
通过一张图片来理解什么是线性分类。给定一张图片作为输入,通过对输入特征(这里中用的是像素值)的线性组合得到各类的分数来确定类别。
一个更加简单直观的例子,假设有一副4个像素的图片,和3个类别。
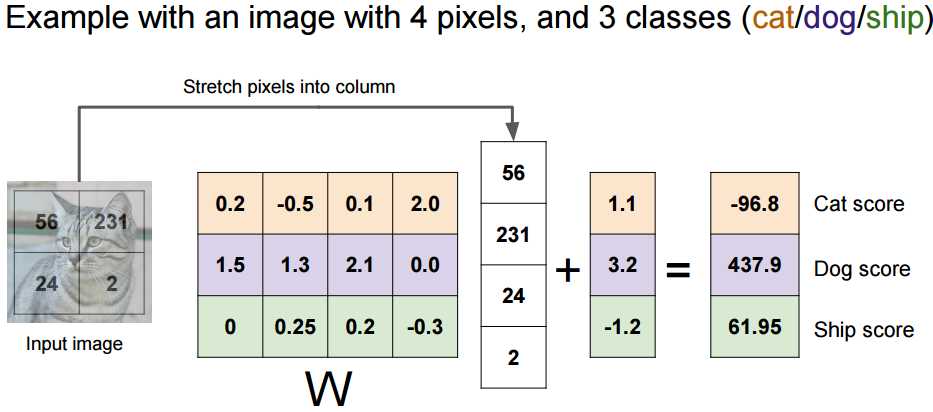
所以这里我们通过定义了一个线性的score fun f(x,W) = Wx + b (这里b是bias )来计算每类对应的得分,右面我们得到三类的分数。
这里有个问题是我们如何评估W是否合适,后面将引进loss function也就是损失函数来评估W的好坏。同时也将介绍optimization 优化方法,从随机的W开始最终得到一个最优的能够使loss fun最小化的W。以及后面的convnet卷积网络
CS231n 学习笔记(1) Image CLassification
标签:-- 最小化 组成 图像 函数 开始 种类 ict 数据
原文地址:http://www.cnblogs.com/klitech/p/7019366.html