标签:数据 images 不同 链接 技术 提高 thread 高效 roc
昨晚发现放在腾讯云主机上通过crontab定时执行用以爬去斗鱼分类页面数据的爬虫在执行的时候速度特别慢,于是想通过多线程来提高效率。
打开浏览器,键入关键字“python 多线程”,发现大多数内容都是使用threading、Queue这些看起来很笨重的实例。不过直到multiprocessing.dummy出现在眼前之后,一切都变得辣么简单。
multiprocessing.dummy 大杀器
multiprocessing.dummy 是multiprocessing的一个子库,二者的不同之处就是前者应用于线程后者主要应用于进程,而它们实现并行化操作的关键则是map函数。
以我的两段代码为例:
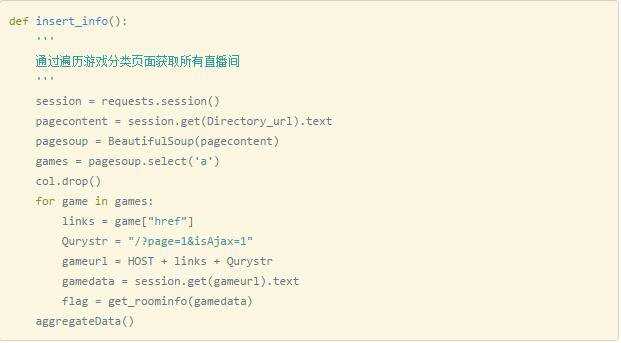
上边这段是之前运行在云主机速度真的跟爬似的代码,通过Directory_url这个地址,获取到页面中所有的标签,并获取到它们的’href’,再逐条获取每个链接中的内容,获取想要的东西,最终完成入库工作。所有的一切都看似按部就班哈。在我的笔记本上做测试,完成所有2032条数据的爬取共耗时140.5s(好特么慢=。=)。
但是在加入multiprocessing.dummy之后,真的是有飞一般的感觉:

标签:数据 images 不同 链接 技术 提高 thread 高效 roc
原文地址:http://www.cnblogs.com/wumingxiaoyao/p/7047858.html