标签:raw roman 技术分享 学习 from 顺序 参数 代码 随机
有监督的分类算法的评价指标通常是accuracy, precision, recall, etc;由于聚类算法是无监督的学习算法,评价指标则没有那么简单了。因为聚类算法得到的类别实际上不能说明任何问题,除非这些类别的分布和样本的真实类别分布相似,或者聚类的结果满足某种假设,即同一类别中样本间的相似性高于不同类别间样本的相似性。聚类模型的评价指标如下:
若已知样本的真实类别标签labels_true ,和聚类算法得到的标签labels_pred,ARI是计算两种标签分布相似性的函数,该函数对标签的定义形式没有要求。scikit-learn中的示例代码如下:
1 from sklearn import metrics 2 labels_true = [0, 0, 0, 1, 1, 1] 3 labels_pred = [0, 0, 1, 1, 2, 2] 4 metrics.adjusted_rand_score(labels_true, labels_pred)
1 metrics.adjusted_rand_score(labels_pred, labels_true)
adjusted_rand_score方法的输入参数没有顺序要求,上面两种结果是完全一样的。
最好的聚类结果是聚类类别和真实类别的分布完全一致,如下代码,结果为1
1 labels_pred = labels_true[:] 2 metrics.adjusted_rand_score(labels_true, labels_pred)
较差的聚类结果会得到负的或者接近0的兰德指数,如下代码
1 labels_true = [0, 1, 2, 0, 3, 4, 5, 1] 2 labels_pred = [1, 1, 0, 0, 2, 2, 2, 2] 3 metrics.adjusted_rand_score(labels_true, labels_pred)
结果为 -0.12
ARI指标需要事先知道样本的真实标签,这和有监督学习的先决条件是一样的。然而ARI也可以作为一个通用的指标,用来评估不同的聚类模型的性能。
如果C是真实类别,K是聚类结果,我们定义a和b分别是:
a: 在C和K中都是同一类别的样本对数
b: 在C和K中都是不同类别的样本对数
raw Rand Index 的公式如下:
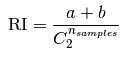
C2nsamples 是样本所有的可能组合对.
RI不能保证在类别标签是随机分配的情况下,其值接近0(极端情况是类别数和样本数相等)
为了解决这个问题,ARI被提出,它具有更高的区分度.
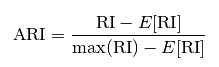
参考:
http://scikit-learn.org/stable/modules/clustering.html#clustering-performance-evaluation
http://blog.csdn.net/sinat_33363493/article/details/52496011
https://en.wikipedia.org/wiki/Rand_index
https://stats.stackexchange.com/questions/89030/rand-index-calculation
标签:raw roman 技术分享 学习 from 顺序 参数 代码 随机
原文地址:http://www.cnblogs.com/alice-wayne/p/7049363.html